







【算法方法总结·八】二叉树的一些技巧和注意事项
- 【算法方法总结·一】二分法的一些技巧和注意事项
- 【算法方法总结·二】双指针的一些技巧和注意事项
- 【算法方法总结·三】滑动窗口的一些技巧和注意事项
- 【算法方法总结·四】字符串操作的一些技巧和注意事项
- 【算法方法总结·五】链表操作的一些技巧和注意事项
- 【算法方法总结·六】栈队列堆的一些技巧和注意事项
- 【算法方法总结·七】哈希的一些技巧和注意事项
- 【算法方法总结·八】二叉树的一些技巧和注意事项
【二叉树】
二叉树的定义
// 二叉树定义
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
// 构造器
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
【二叉树】可以分为几个重要的部分
1、二叉树的遍历(DFS、BFS、层次遍历)
2、对称二叉树、平衡二叉树
3、构造二叉树
4、二叉搜索树
5、二叉树公共祖先
【二叉树的遍历】
【DFS】的递归遍历
- 递归按照 3 要素来写
- 1、确定 递归函数的参数和返回值
- 2、确定 终止条件
- 3、确定 单层递归的逻辑
// 前序遍历
// 1、确定递归函数的参数和返回值
public void preorder(TreeNode root, List<Integer> result){
// 2、确定终止条件
if(root == null) return;
// 3、确定单层递归的逻辑:N L R,先取中节点
result.add(root.val); // N
preorder(root.left,result); // L
preorder(root.right,result); // R
}
// 中序遍历
// 1、确定递归函数的参数和返回值
public void inorder(TreeNode root, List<Integer> result){
// 2、确定终止条件
if(root == null) return;
// 3、确定单层递归的逻辑:L N R
inorder(root.left,result); // L
result.add(root.val); // N
inorder(root.right,result); // R
}
// 后序遍历
// 1、确定递归函数的参数和返回值
public void postorder(TreeNode root, List<Integer> result){
// 2、确定终止条件
if(root == null) return;
// 3、确定单层递归的逻辑:L R N
postorder(root.left,result); // L
postorder(root.right,result); // R
result.add(root.val); // N
}
前、中、后序的 递归遍历 非常简单,但是 非递归遍历 会有点难度
【DFS】的迭代遍历(非递归遍历)
- 递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中
- 所以也能用 栈 实现二叉树的前后中序遍历
前序遍历 N L R
- 入栈的顺序是
N R L,弹出N,再入栈R L,出栈顺序才会是N L R
// N L R
// 入栈的顺序是 N R L,弹出 N,再入栈 R L,出栈顺序才会是N L R
public List<Integer> preorderTraversal(TreeNode root){
List<Integer> result = new ArrayList<>();
if(root == null) return result;
Stack<TreeNode> stack = new Stack<>();
stack.push(root); // N入栈
while(!stack.isEmpty()){
TreeNode node = stack.pop(); // N出栈
result.add(node.val);
if(node.right != null) stack.push(node.right);
if(node.left != null) stack.push(node.left);
}
return result;
}
后序遍历 L R N
- 入栈的顺序是
N L R,弹出N,再入栈L R,出栈顺序才会是N R L,再 翻转 为L R N - 翻转函数为
Collections.reverse()
// L R N
// 入栈的顺序是 N L R,弹出 N,再入栈 L R,出栈顺序才会是N R L,再翻转为 L R N
public List<Integer> postorderTraversal(TreeNode root){
List<Integer> result = new ArrayList<>();
if(root == null) return result;
Stack<TreeNode> stack = new Stack<>();
stack.push(root); // N入栈
while(!stack.isEmpty()){
TreeNode node = stack.pop(); // N出栈
result.add(node.val);
if(node.left != null) stack.push(node.left);
if(node.right != null) stack.push(node.right);
}
Collections.reverse(result); // 翻转结果,N R L -> L R N
return result;
}
中序遍历 L N R (与前后序逻辑不同)
- 前后序 要 访问的元素 和 要处理的元素 顺序是一致的,都是 中间节点。所以代码简洁
- 使用迭代法中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素
// L N R
// 入栈的顺序是 L R
public List<Integer> inorderTraversal(TreeNode root){
List<Integer> result = new ArrayList<>();
if(root == null) return result;
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root; // 记录访问节点
while(cur != null || !stack.isEmpty()){
if(cur != null){ // 访问到最底层
stack.push(cur);
cur = cur.left; // 继续找左孩子
}else{
cur = stack.pop(); // 要处理的数据
result.add(cur.val); // N
cur = cur.right; // R
}
}
return result;
}
【BFS] 层次遍历(广度优先)
- 借助 队列
public List<List<Integer>> res = new ArrayList<>(); // 保存最终结果
public void BFS01(TreeNode node){
if(node == null) return;
Queue<TreeNode> q = new LinkedList<TreeNode>(); // 辅助队列
q.offer(node);
while(!q.isEmpty()){ // 队列不为空
List<Integer> list = new ArrayList<Integer>(); // 保存每一层的结果
int len = q.size();
while(len > 0){
TreeNode tmp = q.poll(); // 弹出父节点
list.add(tmp.val);
if(tmp.left != null) q.offer(tmp.left); // 加入左孩子
if(tmp.right != null) q.offer(tmp.right); // 加入右孩子
len--;
}
res.add(list);
}
}
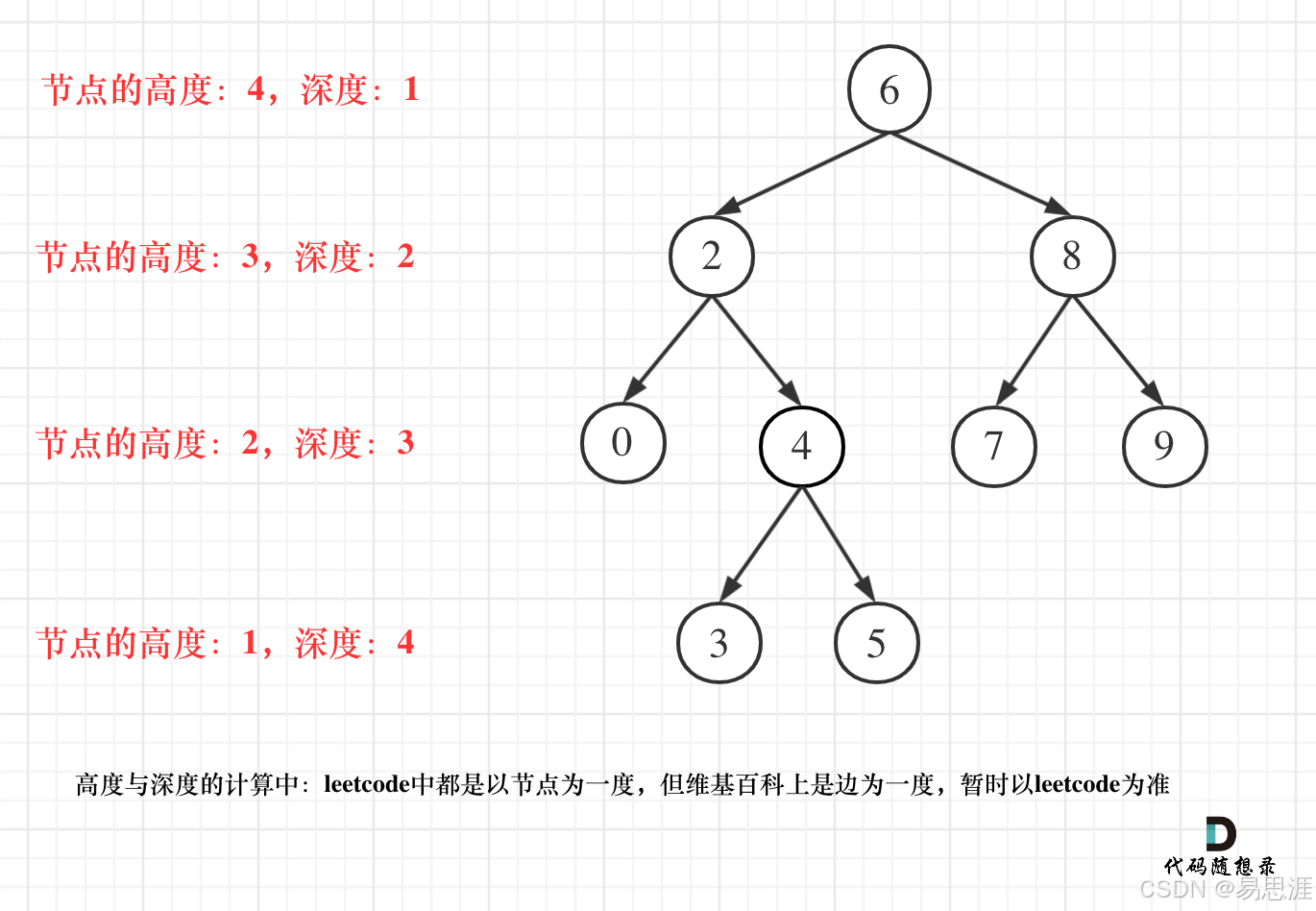
【平衡二叉树】
- 求深度 可以 从上到下 去查,所以需要 前序遍历(
NLR) - 求高度 只能 从下到上 去查,所以只能 后序遍历(
LRN)
【构造二叉树】(至少要知道思路)
- 前序和后序不能唯一确定一棵二叉树!
- 因为没有中序遍历无法确定左右部分,也就是 无法分割
【中、后序构造二叉树】
- 中序
L N R, 后序L R N - 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
- 第五步:切割后序数组,切成后序左数组和后序右数组
- 第六步:递归处理左区间和右区间
class Solution {
Map<Integer,Integer> map;//根据数值找位置
public TreeNode buildTree(int[] inorder, int[] postorder) {
map = new HashMap<>();
for(int i = 0; i < inorder.length; i++){
map.put(inorder[i],i); //保存中序(值,索引)
}
return findNode(inorder,0,inorder.length,postorder,0,postorder.length);
}
public TreeNode findNode(int[] inorder,int inBegin,int inEnd, int[] postorder,int postBegin,int postEnd) {
// [inBegin,inEnd),[postBegin,postEnd)
if(inBegin >= inEnd || postBegin >= postEnd){ // 没有元素
return null;
}
int rootIdx = map.get(postorder[postEnd-1]); //后序最后一个元素在中序中的位置
TreeNode root = new TreeNode(inorder[rootIdx]);
int lenLeft = rootIdx - inBegin; //中序左子树的长度
// L N R 前序;L R N 后序
root.left = findNode(inorder,inBegin,rootIdx,postorder,postBegin,postBegin+lenLeft);
root.right = findNode(inorder,rootIdx+1,inEnd,postorder,postBegin+lenLeft,postEnd-1);
return root;
}
}
【前、中序构造二叉树】
- 与上面同理
- 前序
N L R,中序L N R
class Solution {
Map<Integer,Integer> map = new HashMap<>();
public TreeNode buildTree(int[] preorder, int[] inorder) {
for(int i = 0; i < preorder.length; i++){
map.put(inorder[i],i); //保存中序(值,索引)
}
return findNode(preorder,0,preorder.length,inorder,0,inorder.length);
}
public TreeNode findNode(int[] preorder,int preBegin,int preEnd,int[] inorder,int inBegin,int inEnd){
// [preBegin,preEnd),[inBegin,inEnd)
if(preBegin >= preEnd || inBegin >= inEnd){ // 没有元素
return null;
}
int rootIdx = map.get(preorder[preBegin]); //前序第一个元素在中序中的位置
int lenLeft = rootIdx - inBegin;
TreeNode root = new TreeNode(inorder[rootIdx]);
// 这部分要好好考虑一下
root.left = findNode(preorder,preBegin+1,preBegin+1+lenLeft,inorder,inBegin,rootIdx);
root.right = findNode(preorder,preBegin+1+lenLeft,preEnd,inorder,rootIdx+1,inEnd);
return root;
}
}
【二叉搜索树】
一个 二叉搜索树 具有如下特征:
- 节点的 左子树 只包含 小于 当前节点的数。
- 节点的 右子树 只包含 大于 当前节点的数。
- 所有左子树和右子树 自身 必须也是 二叉搜索树。
【二叉树公共祖先】
- 遇到这个题目首先想的是要是能 自底向上 查找就好了,这样就可以找到公共祖先了。
- 如何实现 自底向上查找 呢?回溯!二叉树回溯的过程就是从底到上。
- 后序遍历(
LRN)就是天然的回溯过程,可以根据左右子树的返回值,来处理中节点的逻辑
相关力扣题
- 相关解法见【算法题解答·八】二叉树


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









