







【算法题解答·五】链表操作
接上文【算法方法总结·五】链表操作的一些技巧和注意事项
链表操作相关题目如下:
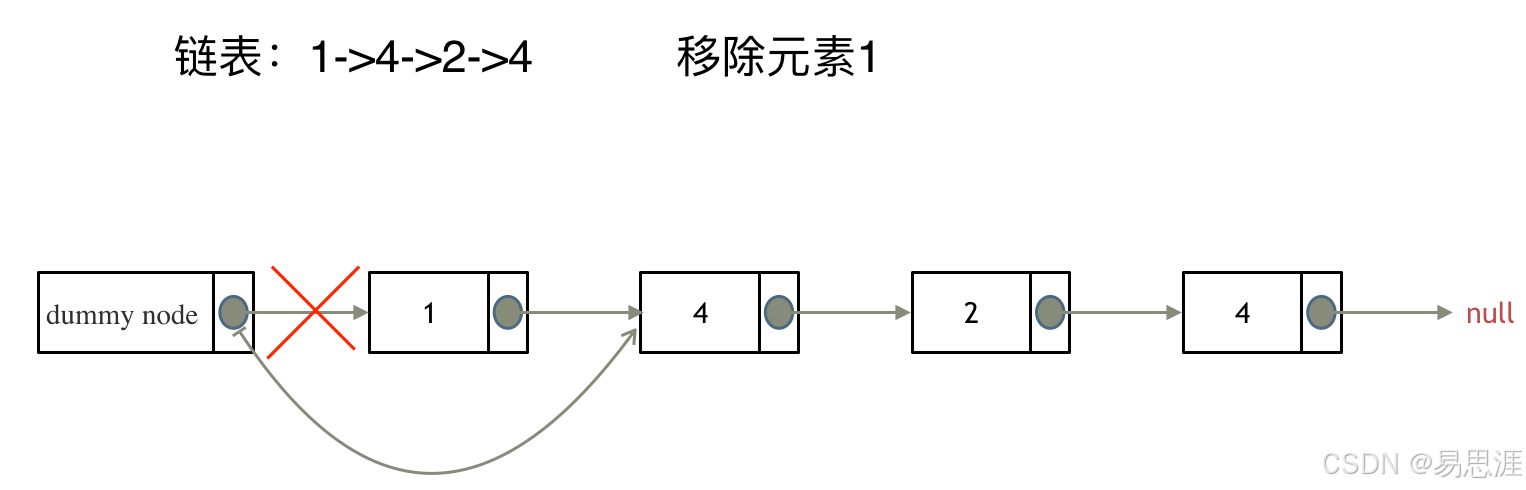
203.移除链表元素简单
- 体会一下 虚拟头结点 的作用
- 如果没有 虚拟头结点,则要对带数据的首元结点做操作,要处理多余的问题
class Solution {
public ListNode removeElements(ListNode head, int val) {
// 设置一个虚拟的头结点
ListNode dummy = new ListNode();
dummy.next = head;
ListNode cur = dummy;
while (cur.next != null) {
if (cur.next.val == val) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
return dummy.next;
}
}
206.反转链表简单
- 两种解法:双指针法 和 递归法
- 双指针法 好理解,这里使用 递归法
head.next = null是先把head.next置空,返回上一层后head.next.next = head把它指向它的前一个元素
class Solution {
public ListNode reverseList(ListNode head) {
// 边缘条件判断
if (head == null) return null;
if (head.next == null) return head;
// 递归调用,翻转第二个节点开始往后的链表
ListNode last = reverseList(head.next);
// 翻转头节点与第二个节点的指向
head.next.next = head;
head.next = null; //先置空
return last; // last一直为最后一位
}
}
24. 两两交换链表中的节点
- 两种解法:直接法 和 递归法
- 直接法 易想到好理解,这里使用 递归法
class Solution {
public ListNode swapPairs(ListNode head) {
// 边缘条件判断
if (head == null || head.next == null) return head;
ListNode p = head.next; // 第2个元素
ListNode newNode = swapPairs(p.next); // 递归调用
// 原先:head -> p -> p.next
// 下面指令执行后:p -> head -> newNode
p.next = head;
head.next = newNode;
return p;
}
}
234.回文链表
- 最简单的方法是 复制一份到数组,利用双指针分别在数组上遍历,空间复杂度为
O(n) - 使用快慢指针实现空间复杂度为
O(1),具体操作为 -
1.找到链表的 中间结点
2.把 中间结点后 的链表 反转
3.双指针分别 指向被中间结点分为两份的 两链表,进行对比
// 空间复杂度 O(1)
class Solution {
public boolean isPalindrome(ListNode head) {
ListNode mid = middleNode(head); // 1.找到中间节点
ListNode head2 = reverseList(mid); // 2.反转中间节点后的链表
while (head2 != null) {
if (head.val != head2.val) {
return false;
}
head = head.next;
head2 = head2.next;
}
return true;
}
// 876.链表的中间节点
public ListNode middleNode(ListNode head) {
ListNode slow = head, fast = head; // 快慢指针
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
// 206.反转链表
public ListNode reverseList(ListNode head) {
ListNode cur = head, pre = null;
while (cur != null) {
ListNode temp = cur.next; // 1.暂存后继节点
cur.next = pre; // 2.修改引用指向
pre = cur; // 3.暂存当前节点
cur = temp; // 4.访问下一节点
}
return pre;
}
}
142.环形链表Ⅱ
- 以下结论需要数学证明的,但我们 只要知道能做题就好
从头结点出发一个指针,从相遇节点也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是环形入口的节点
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head, slow = head; // 快慢指针
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
// 有环,找入口
if (slow == fast) {
ListNode p = fast; // 相遇点
ListNode q = head; // 元素头结点
while (p != q) { // 找入口
p = p.next;
q = q.next;
}
return q; //相遇点为环形入口
}
}
return null;
}
}
2.两数相加
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode head = null, tail = null;
int flag = 0; // 进位
while (l1 != null && l2 != null) {
int sum = flag + l1.val + l2.val;
l1 = l1.next;
l2 = l2.next;
// 因为没有虚拟头结点,所以需要分情况
if (head == null) { // 第一个元素
head = new ListNode(sum % 10);
tail = head;
} else {
tail.next = new ListNode(sum % 10);
tail = tail.next;
}
flag = sum / 10; //看需不需要进位
}
// l1 和 l2 至少有一个为空
ListNode cur = l1 != null ? l1 : l2;
while (cur != null) {
int sum = cur.val + flag;
tail.next = new ListNode(sum % 10);
tail = tail.next;
flag = sum / 10;
cur = cur.next;
}
if (flag > 0) { //单独只有个进位
tail.next = new ListNode(flag);
}
return head;
}
}
19.删除链表的倒数第N个结点
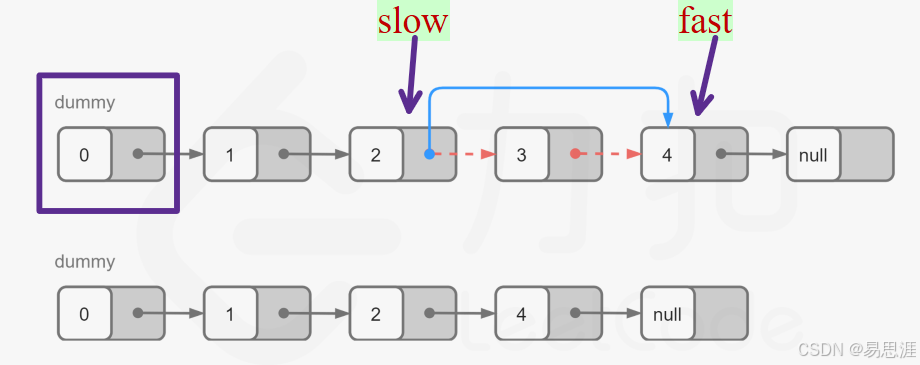
- 让 快慢指针
slow和fast相差n个位置 - 当
fast到尾的时候,slow指向要 删除元素的前驱结点
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0); // 虚拟头结点
dummy.next = head;
ListNode fast = dummy, slow = dummy; // 快慢指针
// 让slow和fast相差n个位置
for (int i = 0; i < n; i++) {
fast = fast.next;
}
// 找到要删除的元素的前驱
while (fast.next != null) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return dummy.next;
}
}
25.k个一组翻转链表 困难
- 每
k个结点为最小反转单位 - 需要注意的点是翻转前需要把链表断开,翻转后需要接上
- 使用自定义翻转函数
reverse,对取出的链表进行翻转
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy = new ListNode(0); // 虚拟头结点
dummy.next = head;
ListNode pre = dummy, end = dummy;
// 只要end不为最后一个
while (end.next != null) {
// 寻找第一组的 end
for (int i = 0; i < k && end != null; i++) {
end = end.next;
}
if (end == null) { // 要翻转的节点数小于k,不需要翻转
break;
}
ListNode next = end.next; // 记录下end.next
end.next = null; // 断开链表
ListNode start = pre.next; // 需要翻转的链表的头
pre.next = reverse(start);
// 翻转完后头变成尾了
start.next = next; // 重新链接上
// 更新下一组
pre = start;
end = start;
}
return dummy.next;
}
public ListNode reverse(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode pre = null, cur = head;
// 1 -> 2 -> 3 -> 4 -> null
// null <- 1 <- 2 <- 3 <- 4
while (cur != null) {
ListNode tmp = cur.next; // 1.暂存后继节点
cur.next = pre; // 2.修改引用指向
pre = cur; // 3.暂存当前节点
cur = tmp; // 4.访问下一节点
}
return pre;
}
}
148.排序链表
- 这题可以用 归并排序 和 快速排序,时间复杂度都是
O(n log n) - 但是 归并排序 是 稳定 的,快速排序 是 不稳定 的
- 而且 归并排序 天然适合 链表结构,因为它 不需要随机访问元素,而是通过 指针操作 进行 分割和合并,快速排序 在链表中实现时,需要 频繁地修改指针
方法一:归并排序
findMid:找到中点,并把链表断开成两个
class Solution {
public ListNode sortList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode mid = findMid(head); // 找到中点
// 划分
ListNode left = sortList(head);
ListNode right = sortList(mid);
return merge(left, right);
}
// 合并
ListNode merge(ListNode left, ListNode right) {
if (left == null) return right;
if (right == null) return left;
if (left.val < right.val) {
left.next = merge(left.next, right);
return left;
} else {
right.next = merge(left, right.next);
return right;
}
}
// 找到中点
ListNode findMid(ListNode head) {
ListNode dummy = new ListNode(0); // 虚拟头结点
dummy.next = head;
ListNode slow = dummy, fast = dummy; // 快慢指针找中点
while (fast.next != null) {
if (fast.next.next == null) {
break;
}
fast = fast.next.next;
slow = slow.next;
}
ListNode x = slow.next;
slow.next = null; // 断开
return x;
}
}
方法二:快速排序 TODO
23.合并k个升序链表 困难
- 使用 最小堆 的方法,先把
k个链表的头结点入堆
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> a.val - b.val);
for (ListNode head : lists) {
// 把所有非空链表的头节点入堆
if (head != null) {
pq.offer(head);
}
}
ListNode dummy = new ListNode(); // 哨兵
ListNode cur = dummy;
while (!pq.isEmpty()) {
ListNode node = pq.poll(); // 剩余节点中的最小节点
if (node.next != null) { // 下一个节点不为空
pq.offer(node.next); // 下一个节点有可能是最小节点,入堆
}
cur.next = node; // 把 node 添加到新链表的末尾
cur = cur.next; // 准备合并下一个节点
}
return dummy.next;
}
}
146.LRU缓存
方法一:哈希表 + 双向链表
class ListNode {
public int key, val;
public ListNode next; // 下一个
public ListNode prev; // 前一个
ListNode() {}
ListNode(int key, int val) {
this.key = key;
this.val = val;
}
}
public class LRUCache {
// head | 7 2 3 4 | tail
public ListNode head, tail; // 左右两哨兵
private int capacity;
public int n; // 总容量
Map<Integer, ListNode> map;
// 1.初始化操作
public LRUCache(int capacity) {
head = new ListNode(-1, -1);
tail = new ListNode(-1, -1);
map = new HashMap<>();
n = capacity;
head.next = tail;
tail.prev = head;
}
// 2.返回该节点的值
public int get(int key) {
// 2.1.存在说明访问过,直接更新
if (map.containsKey(key)) {
ListNode node = map.get(key);
refresh(node); // 更新当前节点
return node.val;
}
return -1;
}
public void put(int key, int value) {
ListNode node = null;
// 存在,则更改其值
if (map.containsKey(key)) {
node = map.get(key);
node.val = value;
} else { // 不存在,插入
// 超出范围,删除最久未使用
if (n == map.size()) {
ListNode del = tail.prev;
map.remove(del.key);
delete(del); // 当前节点从双向链表中移除
}
node = new ListNode(key, value);
map.put(key, node);
}
refresh(node); // 更新当前节点
}
// refresh 操作分两步:
// 1. 先将当前节点从双向链表中删除(如果该节点本身存在于双向链表中的话)
// 2. 将当前节点添加到双向链表头部
public void refresh(ListNode node) {
delete(node);
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
// delete 操作:将当前节点从双向链表中移除
public void delete(ListNode node) {
// node.prev不为空,则代表了node本身存在于双向链表(不是新节点)
if (node.prev != null) {
ListNode left = node.prev;
left.next = node.next;
node.next.prev = left;
}
}
}
方法二:LinkedHashMap
LRU缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。
LinkedHashMap 源码
/**
* //调用父类HashMap的构造方法。
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
// 这里的 accessOrder 默认是为false,如果要按读取顺序排序需要将其设为 true
// initialCapacity 代表 map 的 容量,loadFactor 代表加载因子 (默认即可)
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后复写该方法即可
// 例如 LeetCode 第 146 题就是采用该种方法,直接 return size() > capacity;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
解法
// 继承 LinkedHashMap<Integer, Integer>
class LRUCache extends LinkedHashMap<Integer, Integer> {
private int capacity;
public LRUCache(int capacity) {
// 容量,加载因子,读取是否按顺序
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
算法题解答系列
【算法题解答·一】二分法
【算法题解答·二】双指针法
【算法题解答·三】滑动窗口
【算法题解答·四】字符串操作
【算法题解答·五】链表操作
【算法题解答·六】栈队列堆


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









