







 本文详细介绍了学而思在高并发活动保障方面的策略,包括架构高可用性设计、压测与容量保障、放火演练与防护预案以及变更管控。在架构设计上,强调了N+1设计、回滚策略和多活数据中心等原则。在压测环节,通过全链路接口压测和监控大盘的强化,确保系统的稳定性。放火演练和混沌测试用于发现并增强系统的抗风险能力。变更管控则通过严格的流程和时间窗口,避免潜在影响。此外,文中还涵盖了人员值守、异常处理的流程,以及重保后的复盘总结和经验积累,旨在提升未来活动的保障水平。
本文详细介绍了学而思在高并发活动保障方面的策略,包括架构高可用性设计、压测与容量保障、放火演练与防护预案以及变更管控。在架构设计上,强调了N+1设计、回滚策略和多活数据中心等原则。在压测环节,通过全链路接口压测和监控大盘的强化,确保系统的稳定性。放火演练和混沌测试用于发现并增强系统的抗风险能力。变更管控则通过严格的流程和时间窗口,避免潜在影响。此外,文中还涵盖了人员值守、异常处理的流程,以及重保后的复盘总结和经验积累,旨在提升未来活动的保障水平。
导读:
随着业务的不断发展,尤其是在2020疫情开始后,整个在线教育行业的竞争变得异常严峻,作为这个行业的领路人,用户流量更是成倍增长,这就对我们在线业务运维体系的稳定性提出了更高的要求。
对此网校整体产研部每年寒、暑假都会针对性成立寒、暑特战队。特战队成员为各业务总接口人以及各专项总负责人
特战队成员共同目标为:保障寒、暑假期间百万学员同时稳定上课,无S0事故
每个部门方向均需要输出负责人review过得保障方案,如需有风险,列出整改计划
这里我们从SRE视角对活动保障体系进行了系统性的梳理和总结,将好的沉淀总体分享给大家。整体来看,保障大致分成三个阶段:重保前-重保中-重保后
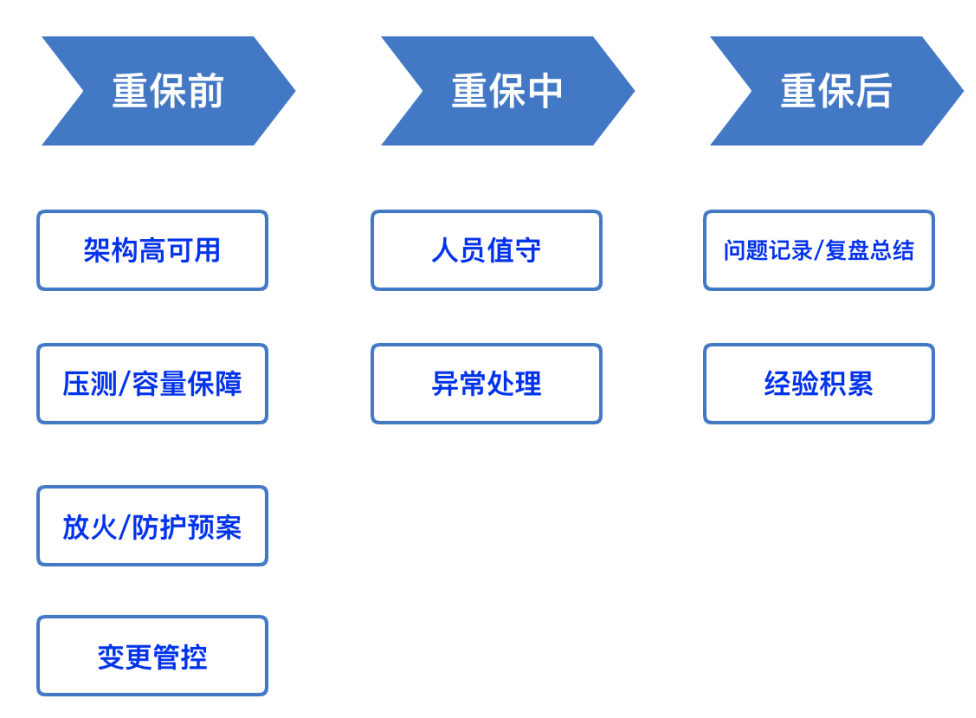
重保前
一、架构高可用
1.架构设计的原则
.N+1设计。系统中的每个组件都应做到没有单点故障;
.回滚设计。确保系统可以向前兼容,在系统升级时应能有办法回滚版本;
.禁用设计。应该提供控制具体功能是否可用的配置,在系统出现故障时能够快速下线功能;
.监控设计。在设计阶段就要考虑监控的手段;
.多活数据中心设计。若系统需要极高的高可用,应考虑在多地实施数据中心进行多活,至少在一个机房断电的情况下系统依然可用;
.资源隔离设计。应避免单一业务占用全部资源;
.架构应能水平扩展。系统只有做到能水平扩展,才能有效避免瓶颈问题
2.狡兔双活架构设计总图
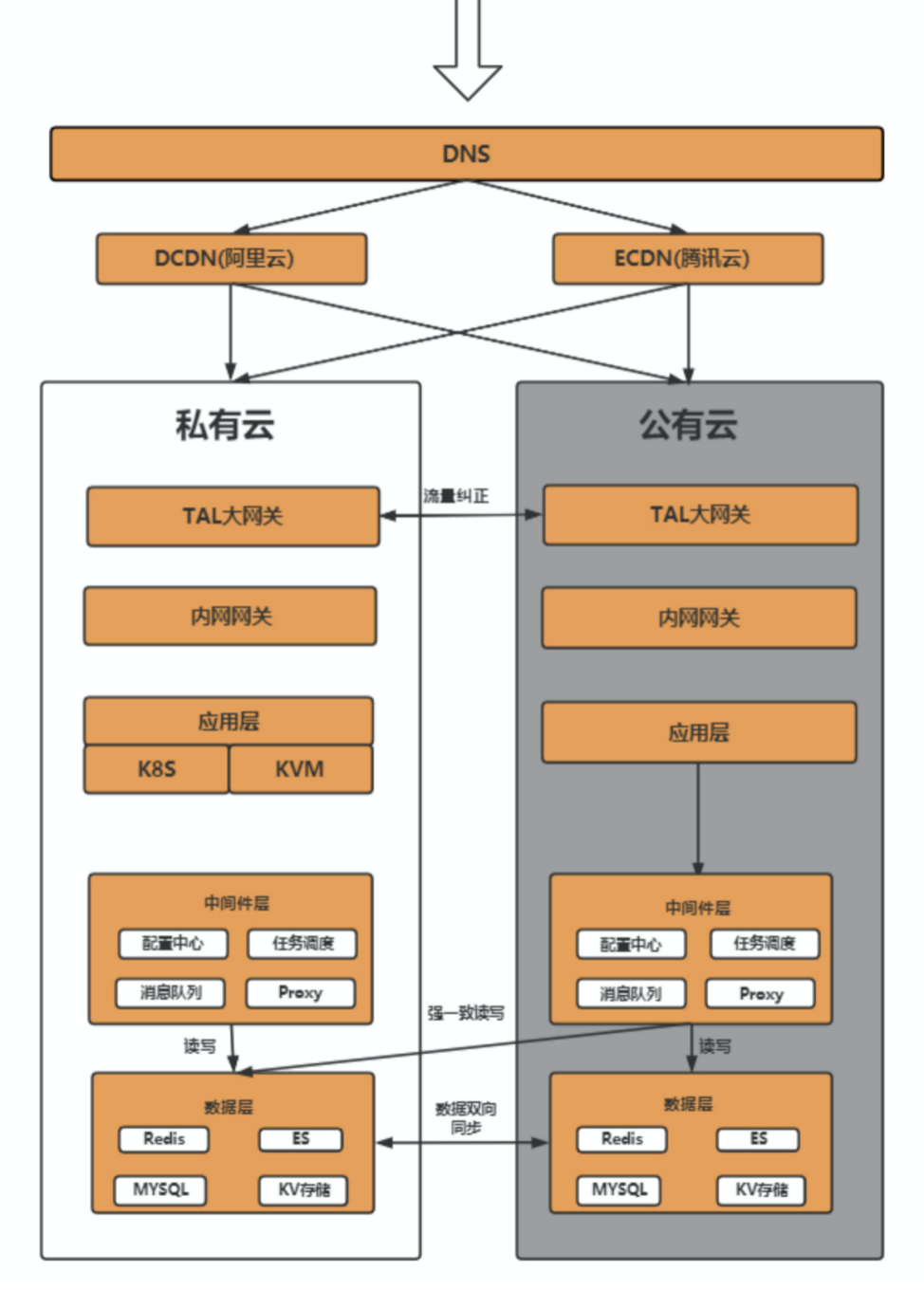
二、压测及容量保障
1.全链路接口压测
a.直播全场景压测试
场景业务说明:直播场景比较特殊 ,一个大的直播场景就是一堂课,而一堂课是由多个独立的互动场景构成,所以这里仅仅一个课中场景来整体覆盖,肯定是不能准确真实的找到系统的性能问题的。为了更贴近真实,覆盖的更加深入,我们将直播课中场景按照小的互动形式,再结合着接口依赖,拆分成13个小场景,然后逐一场景去进行压测。

b.平台全场景压测
场景业务说明:

2.监控大盘
.监控加固
从物理层面(服务器资源)、服务层面(进程、日志、core)、数据层面(配置一致性、数据一致性)、业务层面(语义监控、访问时延、域名)4个维度进行监控的补全,便于重保当天进行实时监测
a.基础监控加固
做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑。所以,依靠强大的监控系统,收集尽可能多的指标,意义重大。但哪些指标才是有意义的呢,本着从实践中来的思想,我们在长期摸爬滚打中总结了在系统运维过程中,经常会参考的一些指标,主要包括以下几个类别:

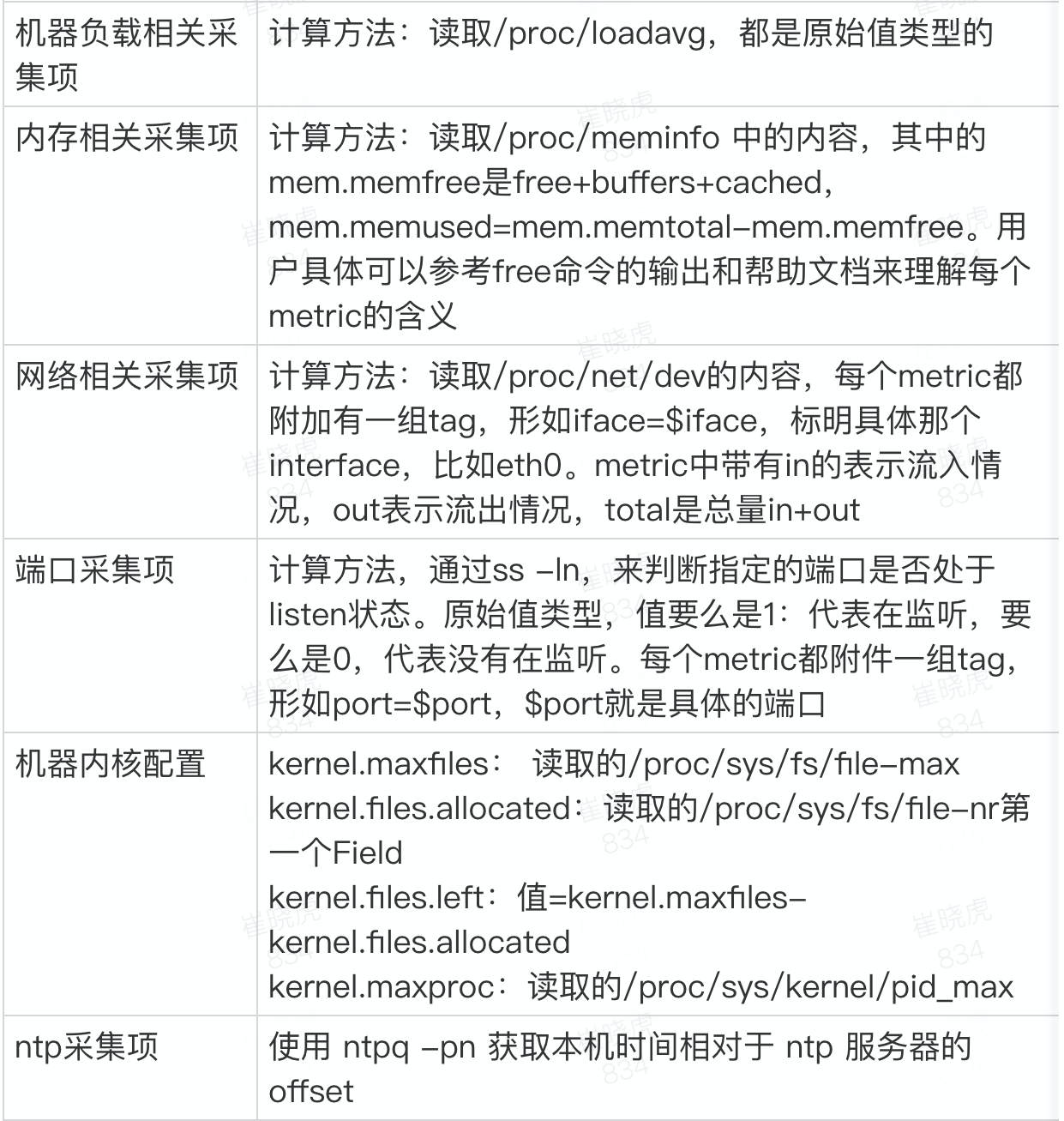

参考文献:https://book.open-falcon.org/zh_0_2/faq/linux-metrics.html
b.网关集群QPS大屏
内网地址:https://cloud.tal.com/tal-beacon#/1/gateway/cluster
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









