






作者:rellyman
所谓PSO算法其实就是定义一个搜索空间,将粒子群随机分布在定义搜索空间内,通过计算个体在搜寻过程中的最佳适应度与位置和群体中的最优适应度和位置。最后,得到最佳的结果。
下面是PSO中每个粒子的运动推导式。
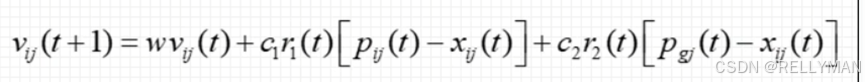
其中,![]() 为t+1时刻粒子的速度。
为t+1时刻粒子的速度。
![]() 为惯性权重,取0-1之间,认为粒子在运动过程中对于前一刻的速度存在惯性作用。
为惯性权重,取0-1之间,认为粒子在运动过程中对于前一刻的速度存在惯性作用。
![]() 为t时刻粒子的速度。
为t时刻粒子的速度。
![]() (个体学习速率)为粒子个体对于该个体历史最优位置的学习速率,就是假定认为相对适应度高的位置附近搜索到更优的值几率更高。因此设定该学习速率,使粒子能够始终对其历史最佳位置相当于一个朝向作用,在其附近搜索。0.5-0.8。
(个体学习速率)为粒子个体对于该个体历史最优位置的学习速率,就是假定认为相对适应度高的位置附近搜索到更优的值几率更高。因此设定该学习速率,使粒子能够始终对其历史最佳位置相当于一个朝向作用,在其附近搜索。0.5-0.8。
![]() 为粒子个体的随机值。rand,一般为0.2-2。
为粒子个体的随机值。rand,一般为0.2-2。
![]() 为该粒子的历史最优适应度处的粒子位置。
为该粒子的历史最优适应度处的粒子位置。
![]() 为该粒子t时刻的位置。
为该粒子t时刻的位置。
![]() (群体学习速率)为粒子个体对于该群体历史最优位置的学习速率,认为群体中最优适应度处位置能够搜索到更优位置几率更高,因此设定该学习速率让个体粒子能够往群体最优解当中靠近,有一个朝向作用。0.5-0.8。
(群体学习速率)为粒子个体对于该群体历史最优位置的学习速率,认为群体中最优适应度处位置能够搜索到更优位置几率更高,因此设定该学习速率让个体粒子能够往群体最优解当中靠近,有一个朝向作用。0.5-0.8。
![]() 为粒子群体的随机值。rand,一般为0.2-2。
为粒子群体的随机值。rand,一般为0.2-2。
![]() 为该粒子群体的历史最优适应度处的粒子位置。
为该粒子群体的历史最优适应度处的粒子位置。
为了不陷入群体最优,在迭代次数少时应该增加个体粒子的惯性作用,扩大粒子的搜索空间范围,迭代次数越高时相应减少。
下面附上PSO下的二维变量的matlab程序。
其余就是规定迭代次数、粒子个数、维数、每个维度的搜索空间范围、每个维度下粒子的速度上下限等。
其中,PSO优化其实就是找某个数学模型的最小值。因此对于最大值的搜索,可以变为负,就转变成了最小值问题。此外,粒子处的函数值越小,适应度越高。
1D
%1D
%%
%目标函数
f=@(x)x .* sin(x) .* cos(2 * x) - 2 .* x .* sin(3 * x) +3 .* x .* sin(4 * x);
%%
%控制参数
N=20; %种群个数
d=1; %维数
ger=100; %迭代次数
limit=[0,50]; %限制搜索的空间
vlimit=[-10,10]; %限制粒子
w=0.8; %惯性权重
c1=0.5; %自我学习因子
c2=0.5; %群体学习因子
x=limit(1)+(limit(2)-limit(1))*rand(N,d);
figure(1);fplot(f,[0,limit(2)]);
%%
%初始化
v=-2*rand(N,d)+1; %初始化每个粒子的速度
xm=x; %初始化每个粒子的历史最优位置,
ym=zeros(1,d); %初始化种群的历史最优位置,设为0
fxm=ones(N,1)*inf; %初始化每个粒子的最佳适应度,最小化问题一开始都赋值为无穷大
fym=inf; %初始化种群的历史最优适应度
hold on
plot(xm,f(xm),'ro');title('初始状态图');
figure(2)
%%
%进行迭代
iter=1; %迭代次数记录
record=zeros(ger,1); %记录每次迭代的最佳适应度
while iter<ger
fx=f(x); %计算每个粒子的当前的适应度
for i=1:N
if fx(i)<fxm(i) %该粒子是否目前为最佳适应度
fxm(i)=fx(i);
xm(i,:)=x(i,:);
end
end
%更新群体的历史最佳位置和历史最佳适应度
if min(fxm)<fym
[fym,nmin]=min(fxm); %fym——最小值,nmin——最小值索引
ym=xm(nmin,:); %更新群体历史最佳位置
end
v=v*w+c1*rand*(xm-x)+c2*rand*(repmat(ym,N,d)-x); %更新速度
%速度边界处理
v(v>vlimit(2))=vlimit(2); %v(v>limit(2)),选择速度大于limit(2)的元素
v(v<vlimit(1))=vlimit(1); %v(v<limit(1)),选择速度小于limit(1)的元素
x=x+v;
%处理x边界
x(x>limit(2))=limit(2);
x(x<limit(1))=limit(1);
record(iter)=fym; %记录本次得出的群体的最佳适应度
%绘图
x0=limit(1):0.01:limit(2);
subplot(1,2,1);
plot(x0,f(x0),'b-',x,f(x),'ro');title('粒子位置变化');
subplot(1,2,2);
plot(record);
title('最佳适应度——迭代次数');
pause(0.1);
iter=iter+1;
end
x0 = 0 : 0.01 : limit(2);
figure(4);plot(x0, f(x0), 'b-', x, f(x), 'ro');title('最终状态位置')
2D
%%
%目标函数
f=@(x,y)(x-3).^2+(y+2).^2+10.*sin(x).*cos(y);
%%
%控制参数
N=20; %粒子个数
d=2; %维数
ger=100; %迭代次数
xlimit=[-10,10];
ylimit=[-10,10];
xy_vxlimit=[-1,1];
xy_vylimit=[-1,1];
w=0.6; %惯性权重
c1=0.2; %个体学习速率
c2=0.2; %群体学习速率
%%
%绘图
step=0.1;
x_figure=xlimit(1):step:xlimit(2);
y_figure=ylimit(1):step:ylimit(2);
z_min=-inf;
z_max=inf;
num=((xlimit(2)-xlimit(1))/step)*((ylimit(2)-ylimit(1))/step);
x=zeros(num,1);
y=zeros(num,1);
z=zeros(num,1);
temp=1;
for i=1:length(x_figure)
for j=1:length(y_figure)
x_n=xlimit(1)+step*i;
y_n=ylimit(1)+step*j;
f_xy_val=f(x_n,y_n);
z_min=min(z_min,f_xy_val);
z_max=max(z_max,f_xy_val);
x(temp)=x_n;
y(temp)=y_n;
z(temp)=f_xy_val;
temp=temp+1;
end
end
%figure(1);
%scatter3(x, y, z, 'y','filled');
%%
%初始化
xy_pos=rand(N,d).*2-1;
xy_pos=xy_pos.*[(xlimit(2)-xlimit(1))/2,(ylimit(2)-ylimit(1))/2];
xy_pos(:,1)=xy_pos(:,1)+(xlimit(2)+xlimit(1))/2;
xy_pos(:,2)=xy_pos(:,2)+(ylimit(2)+ylimit(1))/2;
xy_v=rand(N,d).*2-1;
xy_optimal_pos=xy_pos; %初始最优位置
f_optimal_pos=zeros(1,d); %历史最优位置设为0
xy_optimal_xy_val=ones(N,1)*inf; %初始化每个粒子的最优适应度原本为inf
f_optimal_xy_val=inf; %初始化种群的最优适应度为inf
%%
%初始位置图
%disp(xy_pos);
%hold on;
%size=100;
%figure(1);scatter3(xy_pos(:,1), xy_pos(:,2), f(xy_pos(:,1),xy_pos(:,2)),size, 'r','filled');
%title('初始位置图');
figure(2);
figure('WindowState', 'maximized'); % 全屏显示
%%
%迭代
iter=1;
record=zeros(ger,1);
while iter<=ger
fxy=f(xy_pos(:,1),xy_pos(:,2));
%处理每个粒子的
for i=1:N
if fxy(i)<xy_optimal_xy_val(i)
xy_optimal_pos(i,:)=xy_pos(i,:);
xy_optimal_xy_val(i)=fxy(i);
end
end
%更新群体的
if min(fxy)<f_optimal_xy_val
[f_optimal_xy_val,nmin]=min(fxy);
f_optimal_pos=xy_pos(nmin,:);
end
xy_v=xy_v.*w++c1.*rand.*(xy_optimal_pos-xy_pos)+c2.*rand.*(repmat(f_optimal_pos,N,1)-xy_pos);
%速度边界处理
xy_v(xy_v(:,1)<xy_vxlimit(1),1)=xy_vxlimit(1);
xy_v(xy_v(:,1)>xy_vxlimit(2),1)=xy_vxlimit(2);
xy_v(xy_v(:,2)<xy_vylimit(1),2)=xy_vylimit(1);
xy_v(xy_v(:,2)>xy_vylimit(2),2)=xy_vylimit(2);
xy_pos=xy_pos+xy_v;
%边界处理
xy_pos(xy_pos(:,1)<xlimit(1),1)=xlimit(1);
xy_pos(xy_pos(:,1)>xlimit(2),1)=xlimit(2);
xy_pos(xy_pos(:,2)<ylimit(1),1)=ylimit(1);
xy_pos(xy_pos(:,2)>ylimit(2),1)=ylimit(2);
record(iter)=f_optimal_xy_val;
subplot(1,2,1);
scatter3(x,y,z,'y','filled');title('粒子位置变化');
hold on;
scatter3(xy_pos(:,1),xy_pos(:,2),fxy(:),'k');
hold off;
subplot(1,2,2);
plot(record);
title('最佳适应度——迭代次数');
pause(0.2);
iter=iter+1;
end
subplot(1,2,1);
scatter3(x,y,z,'y','filled');title('粒子最终位置图');
hold on;
scatter3(xy_pos(:,1),xy_pos(:,2),fxy(:),'k');


















 4448
4448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









