







目录
在机器学习领域,当我们想要衡量一个分类模型的优劣时,经常用到一些分析指标,如、精确率、正确率,但看这两个指标往往过于片面,并不能真正反映模型性能的优势。因此,可以引入混淆矩阵来衡量,在此,又得到:召回率(Recall)、 Specificity(特异性)、F1 Score衡量指标。
1.混淆矩阵
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
- 混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
- 每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
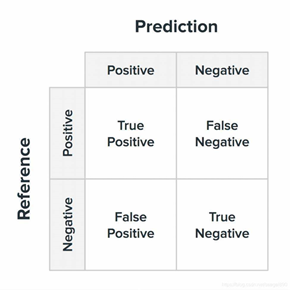
- TP(True Positive,真正例):将真实情况为正例的类型正确地预测为正例
- FN(False Negative,假反例):将真实情况为正例的类型错误地预测为反例
- FP(False Positive,假正例):将真实情况为反例的类型错误地预测为正例
- TN(True Negative,真反例):将真实情况为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









