







paper:arxiv.org/pdf/2102.02808
GitHub:swz30/MPRNet:[CVPR 2021] 多阶段渐进式图像修复。图像去模糊、去色和去噪的 SOTA 结果。
MPRNet 论文解读:《MPRnet》学习笔记-优快云博客
1、配置环境
conda create -n MPRNet python=3.9
conda activate MPRNet
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu118
pip install matplotlib scikit-image opencv-python yacs joblib natsort h5py tqdm
cd pytorch-gradual-warmup-lr
python setup.py install
cd ..2、推理
下载预训练模型并上传至
MPRNet-main/任务名/pretrained_models示例:
python demo.py --task Task_Name --input_dir path_to_images --result_dir save_images_here去雨:
python demo.py --task Deraining --input_dir ./samples/input/ --result_dir ./samples/output/效果展示:






3、训练
按照子文件夹内的 .yml 文件设置数据集位置及其他超参数
###############
## 配置文件开始
####
# GPU 配置
GPU: [0,1,2,3] # 使用的 GPU 设备编号。此配置指示使用 GPU 设备 0, 1, 2, 和 3。
VERBOSE: True # 设置为 True 表示在训练过程中打印详细的日志信息,便于调试和监控训练进度。
# 模型配置
MODEL:
MODE: 'Deraining' # 模型任务类型,本例中是去雨任务(Deraining),即去除图像中的雨滴。
SESSION: 'MPRNet' # 训练会话的名称,通常用于标识当前训练过程,便于保存和恢复。
# 优化器相关的超参数配置
OPTIM:
BATCH_SIZE: 16 # 每次训练迭代使用的样本数量,这里设置为 16。
NUM_EPOCHS: 250 # 训练的总轮数(Epochs),表示整个训练数据集将被处理多少次。
# NEPOCH_DECAY: [10] # 可选项,用于设置学习率衰减的轮数。
LR_INITIAL: 2e-4 # 初始学习率,控制优化器在训练开始时的步长。
LR_MIN: 1e-6 # 最小学习率,当训练接近结束时,学习率将逐渐减少至此值。
# BETA1: 0.9 # 可选项,Adam 优化器的超参数,用于控制一阶矩估计的指数衰减率。
# 训练相关配置
TRAINING:
VAL_AFTER_EVERY: 5 # 每训练 5 个 epoch 后进行一次验证,确保模型训练过程中有持续的性能评估。
RESUME: False # 设置为 False 表示不从中断的训练检查点继续训练(即从头开始训练)。
TRAIN_PS: 256 # 训练图片的尺寸,这里设置为 256x256,表示每次训练使用的图像大小。
VAL_PS: 128 # 验证图片的尺寸,这里设置为 128x128,通常验证使用的图像大小较小。
TRAIN_DIR: './Datasets/train' # 训练数据集的路径。此路径下应包含训练图像。
VAL_DIR: './Datasets/test/Rain100L' # 验证数据集的路径。此路径下应包含用于验证的图像数据。
SAVE_DIR: './checkpoints' # 模型和图像保存的路径,训练过程中会将模型权重和生成的图像保存在此目录。
# SAVE_IMAGES: False # 可选项,设置是否保存生成的图像。
训练数据集下载地址:
https://drive.google.com/drive/folders/1Hnnlc5kI0v9_BtfMytC2LR5VpLAFZtVe?usp=sharing数据集形式:
train
|———— input
————— traget
运行 train.py 文件
报错:
Traceback (most recent call last):
File "/root/autodl-tmp/MPRNet-main/Deraining/train.py", line 70, in <module>
path_chk_rest = utils.get_last_path(model_dir, '_latest.pth')
File "/root/autodl-tmp/MPRNet-main/Deraining/utils/dir_utils.py", line 17, in get_last_path
x = natsorted(glob(os.path.join(path,'*%s'%session)))[-1]
IndexError: list index out of range
ERROR conda.cli.main_run:execute(33): Subprocess for 'conda run ['python', '/root/autodl-tmp/MPRNet-main/Deraining/train.py']' command failed. (See above for error)修改 get_last_path 函数
def get_last_path(path, session):
files = natsorted(glob.glob(os.path.join(path, f"*{session}")))
if files:
return files[-1]
else:
print(f"Warning: No files found in path {path} with pattern *{session}. Returning None.")
return None修改主脚本
######### Resume ###########
if opt.TRAINING.RESUME:
path_chk_rest = utils.get_last_path(model_dir, '_latest.pth')
print(f"Searching for files in path: {model_dir}")
print(f"File pattern: *{session}")
if path_chk_rest is not None:
utils.load_checkpoint(model_restoration, path_chk_rest)
start_epoch = utils.load_start_epoch(path_chk_rest) + 1
utils.load_optim(optimizer, path_chk_rest)
for i in range(1, start_epoch):
scheduler.step()
new_lr = scheduler.get_lr()[0]
print('------------------------------------------------------------------------------')
print(f"==> Resuming Training from epoch: {start_epoch} with learning rate: {new_lr}")
print('------------------------------------------------------------------------------')
else:
print("No checkpoint found. Starting training from scratch.")
start_epoch = 1
else:
print("Starting training from scratch.")
start_epoch = 1报错:
Traceback (most recent call last):
File "/root/autodl-tmp/MPRNet-main/Deraining/train.py", line 146, in <module>
loss_char = torch.sum([criterion_char(restored[j],target) for j in range(len(restored))])
TypeError: sum(): argument 'input' (position 1) must be Tensor, not list
ERROR conda.cli.main_run:execute(33): Subprocess for 'conda run ['python', '/root/autodl-tmp/MPRNet-main/Deraining/train.py']' command failed. (See above for error)Traceback (most recent call last):
File "/root/autodl-tmp/MPRNet-main/Deraining/train.py", line 148, in <module>
loss_edge = torch.sum([criterion_edge(restored[j],target) for j in range(len(restored))])
TypeError: sum(): argument 'input' (position 1) must be Tensor, not list
ERROR conda.cli.main_run:execute(33): Subprocess for 'conda run ['python', '/root/autodl-tmp/MPRNet-main/Deraining/train.py']' command failed. (See above for error)解决方案:
将
# Compute loss at each stage
loss_char = torch.sum([criterion_char(restored[j],target) for j in range(len(restored))])
loss_edge = torch.sum([criterion_edge(restored[j],target) for j in range(len(restored))])
loss = (loss_char) + (0.05*loss_edge)
替换成
# Compute loss at each stage
# 确保 restored 中的每个元素都是张量,并且需要梯度
restored_tensors = [r.requires_grad_() for r in restored] # 设置每个张量的 requires_grad
# 计算损失
loss_char = torch.sum(torch.stack([criterion_char(restored_tensors[j], target) for j in range(len(restored_tensors))]))
loss_edge = torch.sum(torch.stack([criterion_edge(restored_tensors[j], target) for j in range(len(restored_tensors))]))
# 计算总损失
loss = loss_char + (0.05 * loss_edge)
# 确保 loss 是一个标量张量
loss = loss.sum()
# 反向传播
loss.backward()开始迭代:
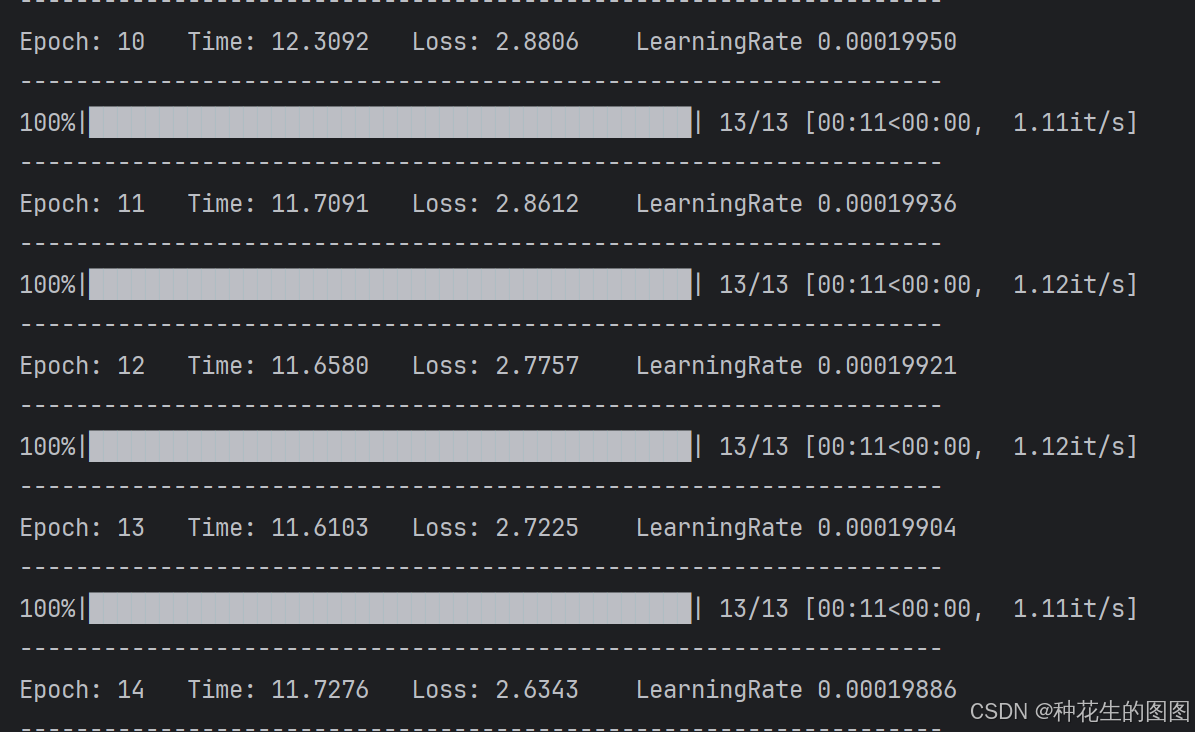

















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









