







paper:2404.02905 (arxiv.org)
目录
3、通过下一个token预测进行自回归建模(传统自回归模型)
阶段一:多尺度VQVAE训练 (具体实现细节看伪代码算法1、2)
1、什么是自回归模型(AR)?
自回归模型(Autoregressive Model, AR) 是一种通过序列中的过去值来预测当前值的统计模型。它通常用于时间序列分析、自然语言处理、计算机视觉等领域。在自回归模型中,当前的值依赖于先前时刻的值。
自回归模型的核心思想是:给定一个序列,预测下一个值时仅依赖于当前和历史的值,而不依赖于其他外部信息。具体来说,对于一个序列,自回归模型通过条件概率的方式建模每个元素在序列中的生成过程:
这里的表示在给定前
个元素的条件下,预测第
个元素的概率。也就是说,自回归模型将一个序列的生成过程分解为一系列条件概率的乘积。
2、什么是token?
token(标记)是对输入数据(如文本、图像或其他类型的数据)进行分解后得到的最小单位。
(1)自然语言处理
在自然语言处理中,token通常是单词、子词、字符或者标点符号等语言的基本单元。
例如,句子“我喜欢学习”可能被分解为以下tokens:
- [“我”,“喜欢”,“学习”],如果是按词来分词。
- [“我”,“喜”,“欢”,“学习”],如果是按子词来分词。
Tokenization(标记化):将一段文本分解为这些基本单位的过程。标记化是NLP中的重要预处理步骤。
(2)计算机视觉
token可以是将图像数据通过特定方式分解后得到的基本单位。
- 图像标记化(Tokenization):图像可以通过某些方法(如卷积、区域划分、特征提取等)被切分成小的块,每个块可以看作一个token。
- Vision Transformer(ViT)通过将图像划分成若干个patch(补丁),每个patch可以看作一个token。
3、通过下一个token预测进行自回归建模(传统自回归模型)
(1)序列依赖
生成序列时,每个 token 依赖于它的前缀序列(已生成的 token)。
由于展平操作,破坏了二维空间关系,序列中的相邻 token 不一定对应图像中相邻的位置。
(2)自回归模型的似然函数:
给定一个离散标记序列,其中每个标记
(
是词汇表大小),模型根据前面的标记
来预测每个标记
。
整个序列的似然可以分解为:
自回归假设认为每个token的出现只依赖于它之前的token(即“马尔可夫假设”),因此可以将整个序列的联合概率分解为一系列条件概率的乘积。
在这个过程中,模型被训练来优化每个token 在给定之前的token下的预测,这就是下一个token预测。
(3)图像的标记化过程(Tokenization)
图像是二维的连续信号,为了将自回归建模应用到图像上,需要将图像转化为离散的token,并定义这些标记的顺序。因为与语言不同,图像没有自然的从左到右的顺序。
图像首先通过编码器
转换为一个特征图
。这里的
是一个连续的高维特征张量,形状为
,其中
和
是图像的高度和宽度,
是通道数。
然后通过量化器将该特征图转换为离散 token
。量化后的token
是一个离散的网格,每个位置上存储一个token,表示该位置的特征被映射到字典中的哪个离散值。
(4)量化过程
是特征图
中第
位置的特征向量,表示图像在该位置的特征。
是量化器通常中的一个可学习的字典,其中包含
个离散的向量,每个向量代表一个“代码”。
是字典查找操作,表示获取字典
中第
个向量。
操作寻找与特征向量
最相似的字典向量。通过计算
和字典中每个向量的欧几里得距离,找到最小距离对应的 token
。
完成标记化后,得到的 token 序列会被展平成一维序列,然后传递给自回归模型进行训练。
自回归模型(如Transformer或RNN)通常是为处理 一维序列数据(如自然语言、时间序列)而设计的。在这种情况下,输入数据必须被表示为线性序列。因此,为了将二维特征图(如图像的token map)输入到自回归模型中,通常需要将其展平为一维序列。一个的二维token图,展平后变成长度为
的一维序列
。通过这种方式,自回归模型可以依赖序列生成的机制逐步生成图像的每个token。
(5)图像重建
为了训练量化自编码器,每个会查找字典
,以获取
,即原始特征
的近似值。然后,使用解码器
通过
重建新的图像
将 token
转换回特征图
,这个特征图是图像的近似表示。
使用解码器
将重建的特征图
转换回图像
,这是输入图像的近似重建。
(6)复合损失函数
这个复合损失函数用于训练量化自编码器,其目的是最小化输入图像和重建图像
之间的差异,同时保持特征空间的准确性。
是图像重建误差,表示输入图像和重建图像之间的差异(通常使用均方误差)。
是特征图误差,表示原始特征图和重建特征图之间的差异。
是感知损失,用于衡量重建图像与原图像在视觉上的差异。
是判别性损失,通过判别器来衡量生成图像的质量(如StyleGAN)。
(7)传统自回归模型中的主要问题
虽然自回归模型在文本(有自然顺序)中表现良好,但将其应用于图像时会遇到一些挑战,具体包括:
数学前提的违背:展平之后,图像标记仍然保持双向相关性,这与自回归模型的单向依赖假设相矛盾。
zero-shot泛化能力差:自回归模型在需要双向推理的任务上表现差(例如,给定图像的下半部分,无法预测上半部分)。
空间结构破坏:展平操作破坏了图像特征图中固有的空间结构和局部相关性。
低效性:传统的自回归生成图像的复杂度为,计算量大。
4、通过下一个尺度预测进行自回归建模(VAR)
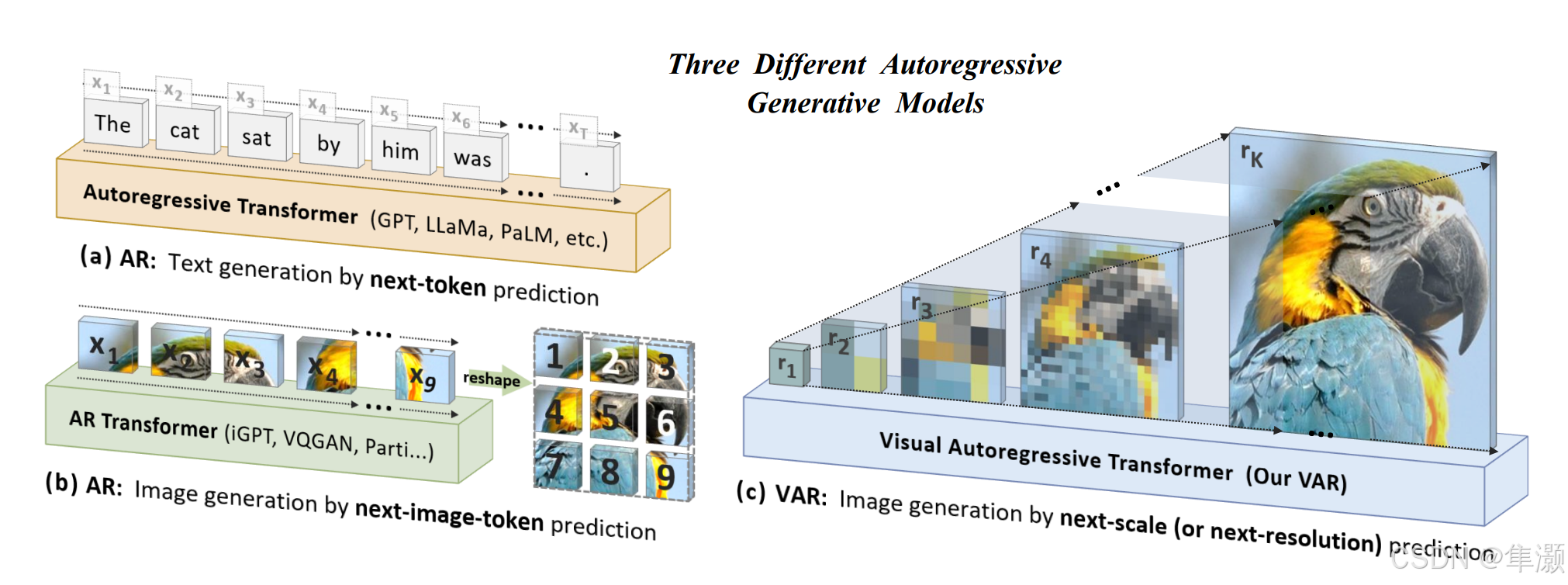
与其预测单个标记,不如预测整个“token图”(即多个token的网格),每个尺度逐渐生成更高分辨率的token图,从而以粗到细的方式进行图像生成。
首先,特征图被量化为
个多尺度token图
,其中每个
的分辨率逐渐增加,最终
匹配原始特征图的分辨率
。
(1)VAR 似然函数:
其中, 是第
个尺度的 token 图,包含
个token。前缀
用于预测
中的token。
(2)VAR 的标记化
为了实现VAR,提出了一种多尺度量化自编码器,它将图像编码为个多尺度的标记图
,用于VAR的学习。该自编码器类似于VQGAN,但经过修改以适应多尺度量化。
在编码过程中:每个尺度仅依赖于前面的尺度
,所有尺度共享一个代码本
,确保每个尺度的标记属于相同的词汇表。
(3)VAR训练阶段
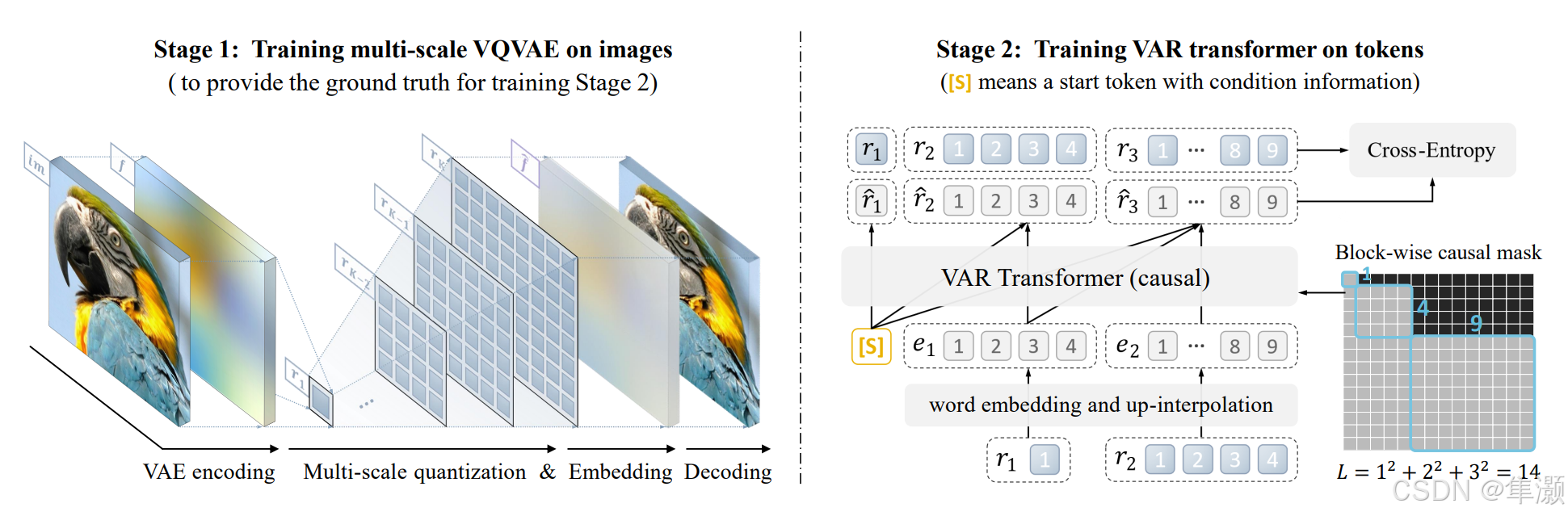
VAR涉及两个独立的训练阶段:
阶段一:多尺度VQVAE训练 (具体实现细节看伪代码算法1、2)
一个多尺度VQVAE将图像编码为 个token 图
,并通过复合损失进行训练。
(1)输入图像处理:输入的图像经过VAE的编码部分,将其从原始的连续特征(如RGB像素)转化为一组具有离散表示的token图。每个token图 是图像在不同尺度下的离散表示。最终,将得到
个token图
,每个token图都对应一个不同的图像尺度(比如低分辨率、中分辨率和高分辨率的特征表示)。
(2)多尺度量化:这一步使用了多尺度量化(Multi-scale Quantization)的技术。与传统的单一尺度量化不同,VAR使用了多个不同的分辨率或尺度来表示图像。每个尺度下,图像被量化成不同的token图。这些token图有不同的分辨率。
阶段二:VAR变换器训练(下一个尺度预测)
使用一个基于变换器(Transformer)的自回归模型,这个模型用于从训练数据中学习如何生成图像的多个尺度token图。其核心思想是通过下一个尺度预测来建模图像生成的过程
在训练过程中,使用注意力掩码来确保每个 只能关注之前的 token 图。
在训练时,VAR变换器的输入包括一个带有条件信息的起始token 和前
个token图
,目标是预测下一个token图
。即变换器根据前面的token图来生成下一个尺度的token图。
(1)输入部分:
输入数据:图片底部的
显示了输入的tokens序列,这些tokens是通过第一阶段的多尺度VQVAE从图像中提取的,每个token代表图像中的一个特定尺度,这些token是图像被分块处理后生成的离散值。
初始token :
是一个特殊的start token,用于初始化序列并带有条件信息。
Word Embedding and Up-Interpolation: 输入的tokens首先通过词嵌入(word embedding)转换为向量表示,然后进行上采样(up-interpolation)以匹配VAR变换器的输入要求。
(2)模块部分
VAR Transformer (causal): 这是一个基于因果机制的 Transformer 模型,用于预测序列中的下一个标记,意味着在生成序列时,每个token的预测仅依赖于它之前的tokens,这有助于模型学习序列中元素之间的时间依赖关系。它接受等,通过递归计算生成新的标记预测值
。
块级因果掩码 Block-wise Causal Mask: 图中右下角展示了一个用于限制信息流的掩码矩阵,掩码基于块(block)设计,每个块代表一组相邻的token,灰色区域表示可用信息,黑色区域表示被掩盖的信息,确保标记只能依赖于已经生成的内容。例如,块编号为 9 的标记只能看到编号为 1、4、9 的块。总复杂度为 ,计算效率高于逐像素的依赖机制。
(3)输出部分
Cross-Entropy: 训练过程中,VAR Transformer 的输出是预测的token值 。使用交叉熵损失(Cross-Entropy)计算预测值与真实值
的误差,并以此优化模型。这个损失函数用于指导模型的学习过程,以最小化预测和实际之间的差异。
(4)VAR 优势:
数学一致性:下一个尺度预测确保每个尺度 仅依赖于其前缀
,这一约束符合自回归模型的数学前提,同时也符合人类视觉感知的自然发展(粗到细)。
保留空间局部性:在VAR中没有展平操作。每个尺度中的标记是完全相关的。多尺度设计进一步增强了空间结构的保留。
提高效率:使用VAR生成图像的计算复杂度大大降低为,相比之下,传统自回归模型的复杂度为
。这一效率提升来自于每个尺度内标记的并行生成。
(5)伪代码
算法1:多尺度VQVAE编码

:输入
:原始图像
:超参数
:量化过程的尺度数,即图像会被编码成
个不同分辨率的token图。
:每个尺度
的分辨率,用于调整图像特征图到目标分辨率。
:使用编码器
对图像
提取特征图
,这是一个连续的特征表示,大小为
:初始化一个空列表
,用于存储多尺度的离散token图。
:遍历每个尺度
,依次生成分辨率从低到高的离散标记图。
:使用插值方法将特征图
调整到当前尺度的目标分辨率
,使用量化器
对插值后的特征图进行量化,得到离散的token图
。
:将当前尺度的离散 token 图
压入列表
。
:使用代码本
对离散 token 映射
中的每个 token 查找对应的实际代码向量
,每个 token
在代码本中都有唯一对应的连续向量表示。
:将
从当前分辨率
插值到最高分辨率
,这是为了使
能够与原始特征图
对齐,用于后面的残差计算。
:使用卷积层
处理
,得到当前尺度的信息贡献。从原始特征图
中减去该贡献,以得到残差特征图
,残差特征图用于生成下一尺度的标记图,保证每个尺度的标记图捕获不同层次的信息。这一步是逐层剥离特征的过程,确保每个
只编码与其对应的尺度相关的独立信息。
:返回包含
个尺度的离散token图的列表
。
算法2:多尺度VQVAE 重建
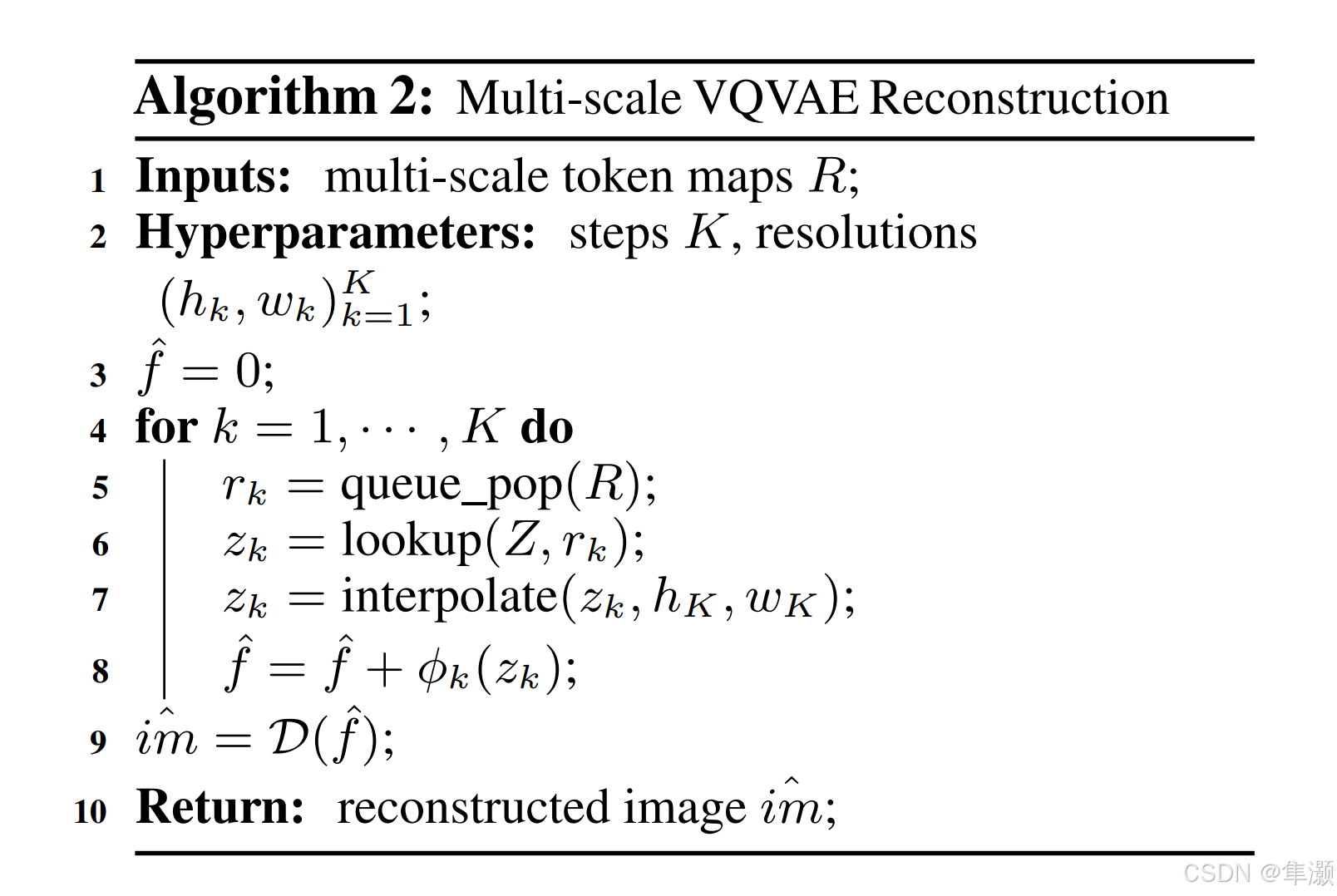
:初始化一个零特征图,逐步累积每层的特征贡献。它将作为最后的重建输入传递给解码器
。
:从队列
中取出当前分辨率的 token map
。
:从共享的代码本
中,查找 token
对应的嵌入向量
。
是查找后的嵌入向量集合,表示当前层特征的连续化表示。
:将当前嵌入向量
插值到最高分辨率
(最终解码分辨率),将低分辨率的嵌入对齐到最终图像的分辨率以便融合。
:使用卷积层
对当前嵌入
进行变换,得到本层的特征贡献。将本层的特征贡献累加到重建特征图
中。
:使用解码器
将累积的重建特征图
转化为最终的重建图像
。
5、拓展
1、VQVAE
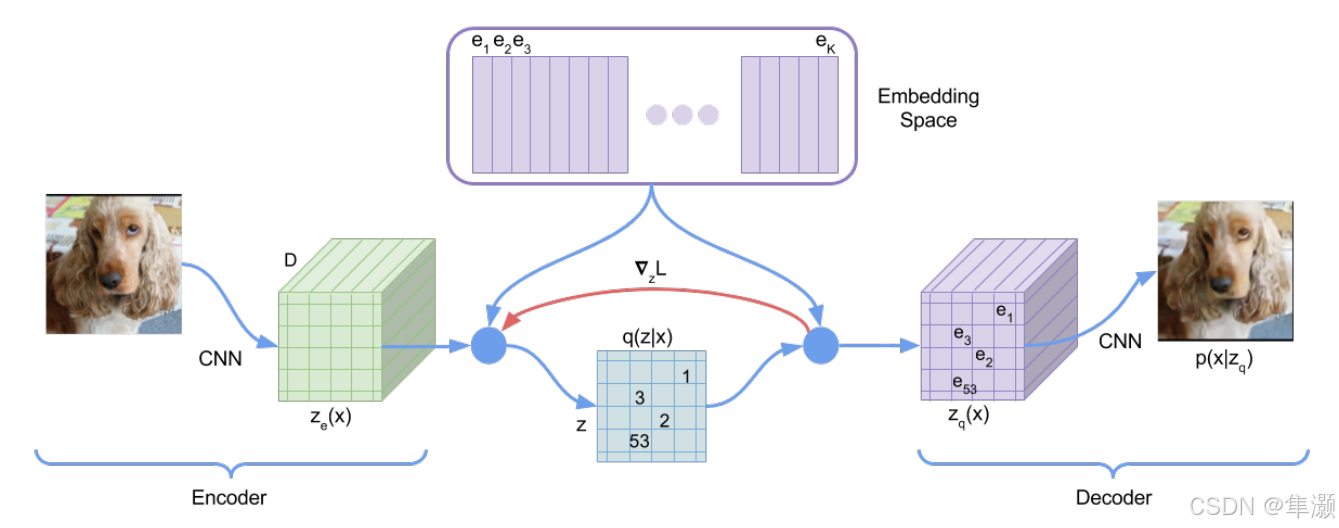
VQVAE(Vector Quantized Variational Autoencoder)是一种改进的变分自编码器(VAE)模型,结合了离散表示学习和自编码器的优点。VQVAE的核心思想是将图像或其他数据的连续特征表示通过向量量化映射到离散空间,并利用这种离散空间进行生成和重构。与传统的VAE不同,VQVAE引入了向量量化操作,帮助它学习到更加结构化和有意义的离散表示。
VQVAE模型包括三个主要部分:编码器(Encoder)、量化器(Quantizer)和解码器。
编码器(Encoder):编码器将输入数据(例如图像)映射到一个高维特征空间中。通常,编码器由一个卷积神经网络(CNN)组成,它将输入图像映射为一个连续的潜在空间表示 。
量化器(Quantizer):量化器是VQVAE的核心部分,它将编码器输出的连续潜在表示映射到一个离散的表示空间中。具体而言,量化器使用一个预定义的离散向量集合(Embedding Space)来表示潜在空间的每一个点。给定一个输入特征向量,量化器会将其映射到代码本中最接近的向量,这个过程称为向量量化。量化后的离散向量称为
。
解码器(Decoder):解码器将离散的潜在表示转换回原始数据空间。在图像生成任务中,解码器将离散的token重新映射回图像数据。解码器通常由反卷积神经网络(Deconvolutional Network)组成。
2、VQGAN
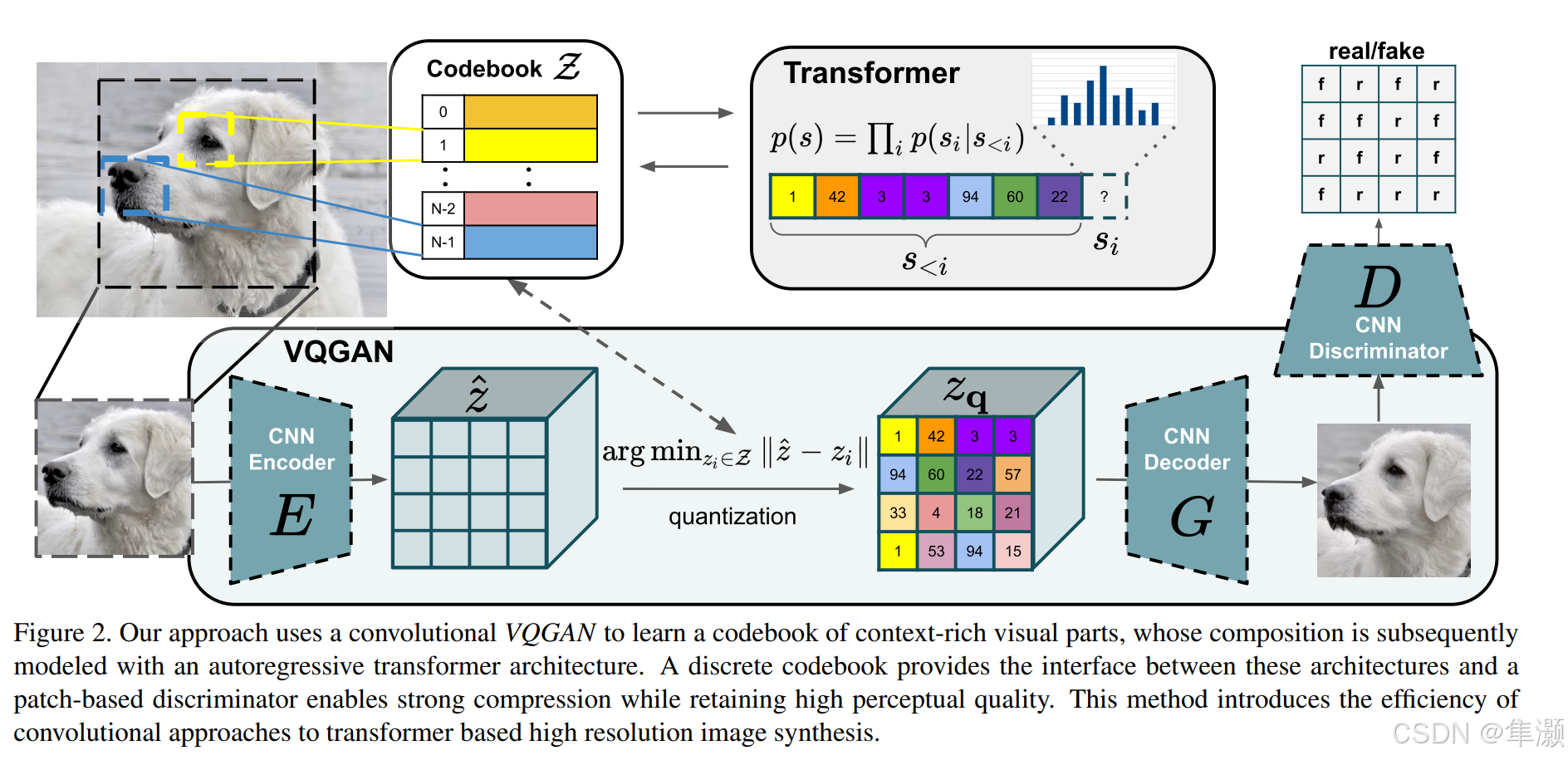
VQGAN 实际上就是在 VQVAE 的基础上增加了一个判别器 。
(1)模块介绍:
编码器 :将输入的图像(左下角的狗图像)通过卷积神经网络(CNN)提取特征,生成一个潜在表示
。
是一个连续的特征表示矩阵。
Quantization(量化):将编码器生成的连续特征 映射到一个离散的代码本(Codebook)
中,每个特征向量都会找到一个最接近的离散向量
进行替换(通过
)。
解码器:将离散表示
(矢量量化后的矩阵)通过卷积神经网络解码为原始分辨率的图像。
判别器:作为对抗网络的一部分,判别生成的图像是真实的还是伪造的。与解码器
对抗训练,提升生成图像的真实性。
Transformer:使用 Transformer 模型对离散化后的代码本表示进行序列建模,Transformer 学习序列分布 ,表示如何根据先前的离散代码片段
预测当前代码
。
(2)整体流程:
- 输入的图像经过 CNN 编码器
,生成潜在表示
。
- 潜在表示
,得到
。
- Transformer 对代码本中的离散表示进行建模,用于捕捉全局语义。
- 解码器
将离散表示
- 判别器
对生成图像进行真假判别,从而改进解码器(生成器)

















 25
25

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









