







原视频链接,这里是自学笔记版本。
第1课-基本概念(State,action,policy等)_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1sd4y167NS/?p=2&spm_id_from=333.880.my_history.page.click&vd_source=412bb3f136dac0fe6accc6d28f99d8a3第1课-基本概念(Reward,return,MDP等)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1sd4y167NS/?p=2&spm_id_from=333.880.my_history.page.click&vd_source=412bb3f136dac0fe6accc6d28f99d8a3第1课-基本概念(Reward,return,MDP等)_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1sd4y167NS?p=3&vd_source=412bb3f136dac0fe6accc6d28f99d8a3
https://www.bilibili.com/video/BV1sd4y167NS?p=3&vd_source=412bb3f136dac0fe6accc6d28f99d8a3
目录
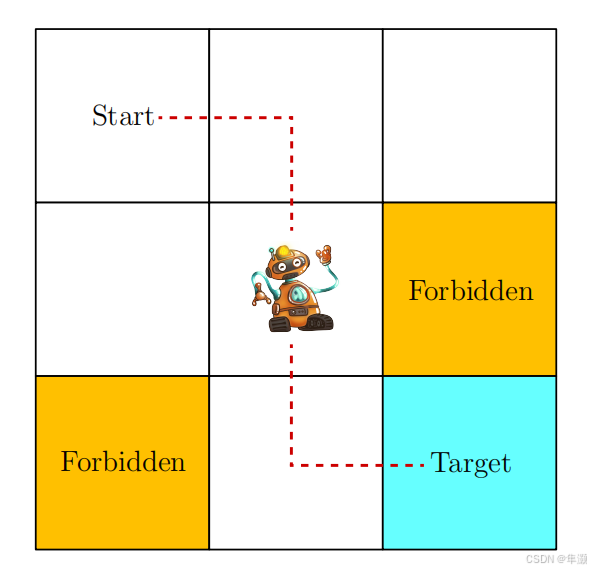
Accessible 表示可以进入,用白色表示
Forbidden 表示不可进入,用黄色表示
Target area 表示希望进入的这个领域当中
机器人只能在相邻的网格之间移动,不能斜方向移动
State
它描述了 agent 相对于 environment 的 status。
在grid-world example 中,表示位置location。
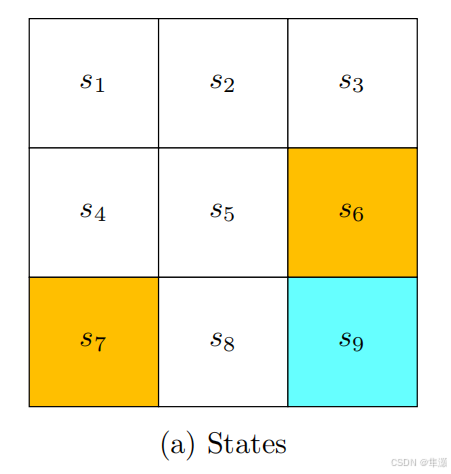
在这里,s1实际上表示一个索引 ,它真正对应的状态,在这里面是二维平面的位置。x方向的位置x,和y方向的位置y。
在复杂问题中,除了位置之外,可能还会对应速度,加速度等状态。
当我们把所有的状态放在一起,我们就会得到状态空间 state space。实际上,空间就是一个集合set。
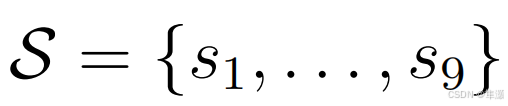
S 表示状态空间,{ } 表示一个集合。
Action
action 表示在每一个状态实际上有一系列的可采取的行动。这里面包含了5个行动,分别是a1(表示向上走),a2(表示向右走),a3(表示向下走),a4(表示向左走),a5(表示原地不动) 。
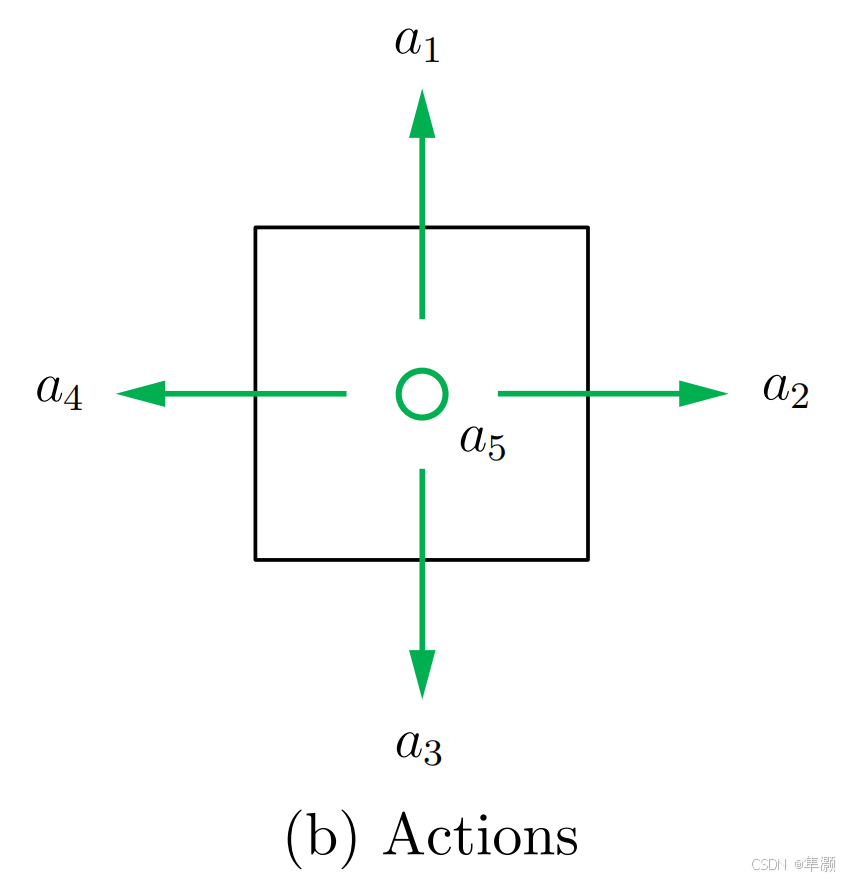
如果将所有的 action 放在一起,我们就会等到行动空间 action space。
![]()
需要注意的是, action space 与 state 是依赖的,也就是不同的 state 对应不同的 action sapce。
![]()
State transition
当采取一个 action 后,这个agent可以从一个 state 移动到另一个 state,这样的过程就被称为state transition。
举一个例子,比如说在状态s1,如果我采取action是a2,那么下一个状态就会是到s2 。
![]()
在s1,然后take action a1,s1 a1下一个状态是s1。在s1然后往上走 会撞到这个边界,如果边界是一堵墙的话,则会被撞回来,就还是回到s1,不会出去。
![]()
State transition实际上是定义agent和环境的一种交互的行为 。
State transition可以用这种 tabular 的形式表现出来。
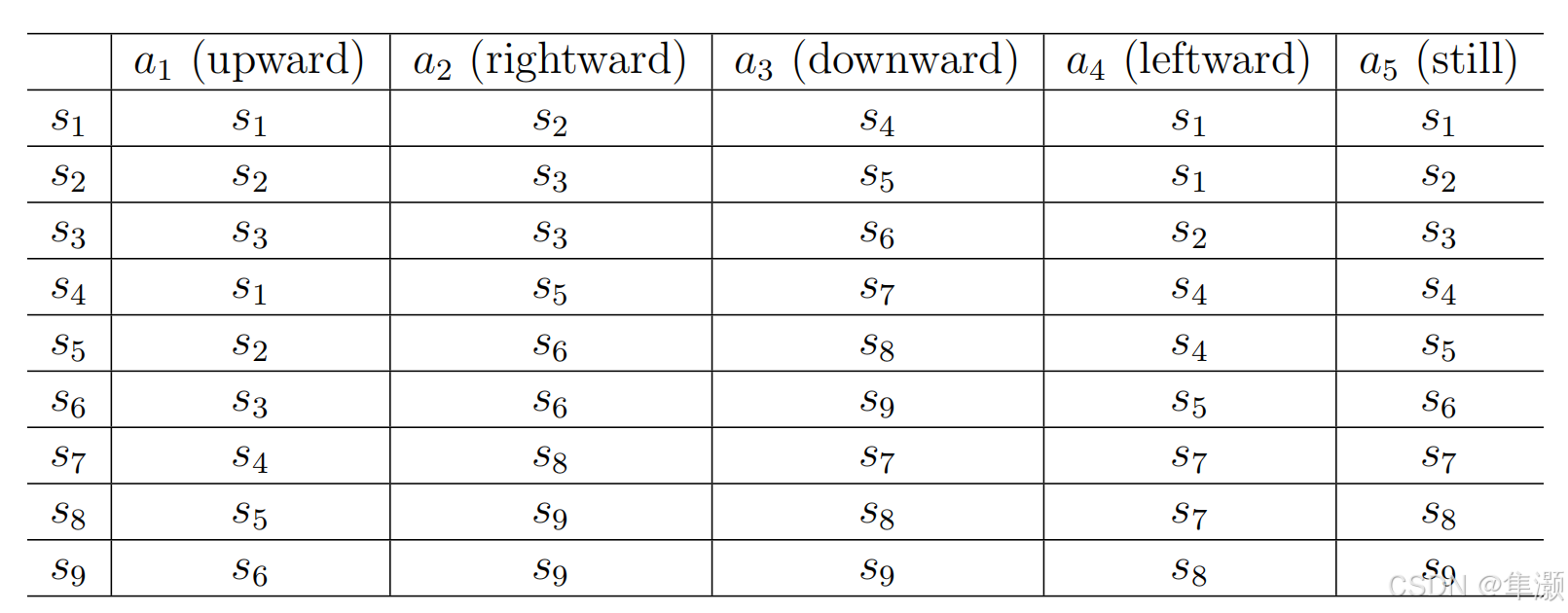
这个表格的每一行 都对应了每一个状态。这个表格的每一列 都对应了这样一个action。
虽然这个表格的形式是比较直观的,但是在实际当中用的是比较受限,因为它只能表示这种deterministic 也就是确定性的情况。比如说我在s1 然后我take action a1,我也有可能跑到s1 我也可能被弹回到s4,我甚至可能被弹回到s7,也就是说有多个状态存在这样的可能性,这时候这个表格是无法表达的,所以这时候其实我们更一般的方法是什么呢?用state transition probability。
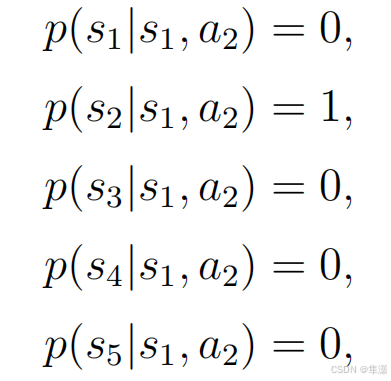
Policy
Policy是什么?就是它会告诉agent,我如果在一个状态我应该take哪一个action。直观上的理解policy 我们是用箭头来表示的,大家可以看到这里边有9个状态,每一个状态都对应一个箭头。那么 这样一个策略我就可以用箭头来表示,基于这个策略,实际上我们可以得到一些path或者叫trajectory。
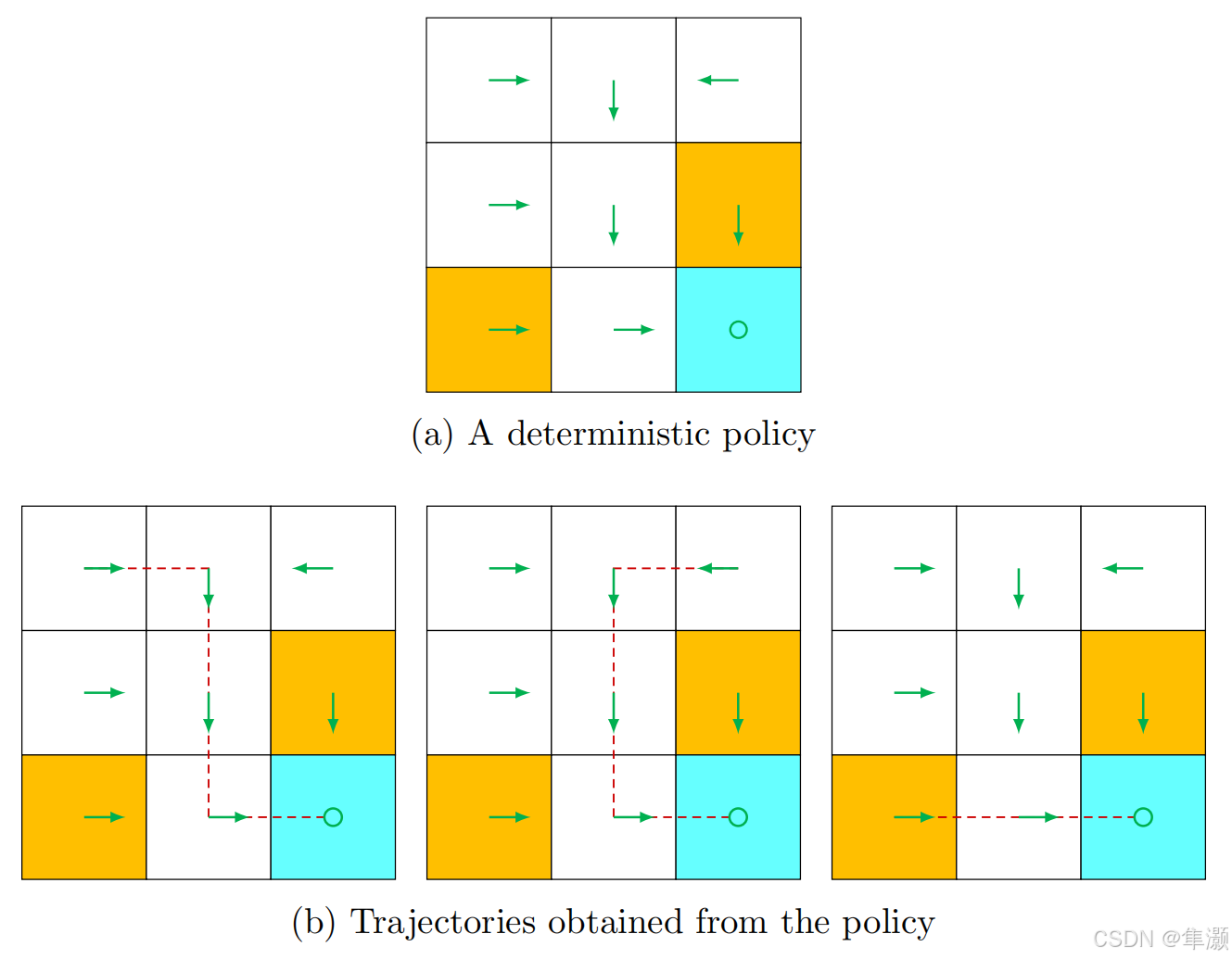
在强化学习当中 π 就统一指的是策略。π是一个条件概率,它指定了任何一个状态下 任何一个action 它的概率是多少。比如说针对s1,在s1下它take action a1也就是往上走的概率是0,在s1下它take action a2也就是往右走的概率是1,其他所有的action的概率全都是0,它所有针对一个状态,它所有的概率之和应该加起来是等于1,这个就是一个策略。这是一种确定性的情况。
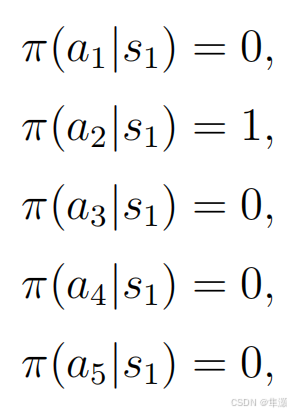
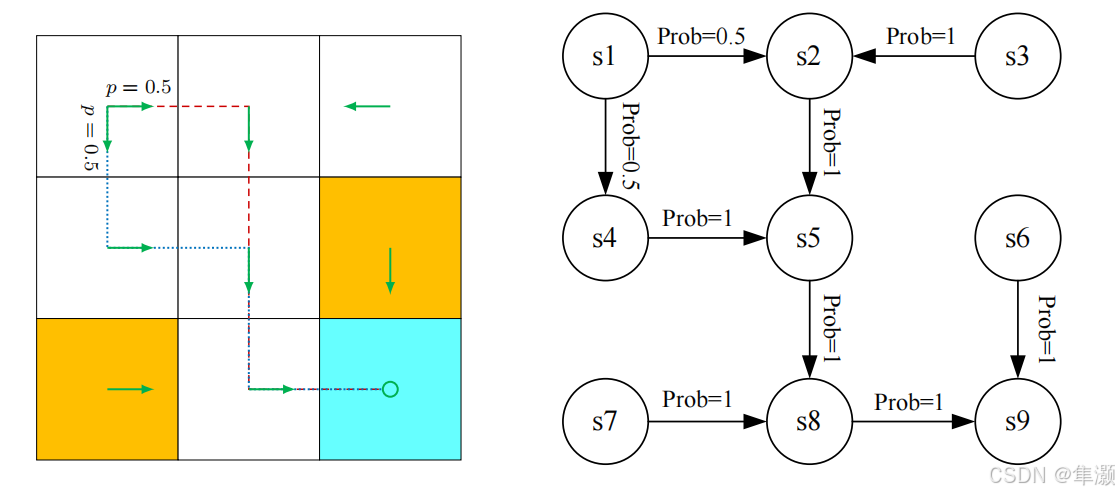
实际上也存在这种不确定性的情况,也就是stochastic的policy,比如说从这个地方出发,Policy 实际上有0.5的概率是要往右走,有另外0.5的概率是要往下走,如果这时候我从这个地方出发,有可能我得到的是这样一条轨迹,我也有可能得到是这样一条轨迹,所以这个时候策略是不确定的。
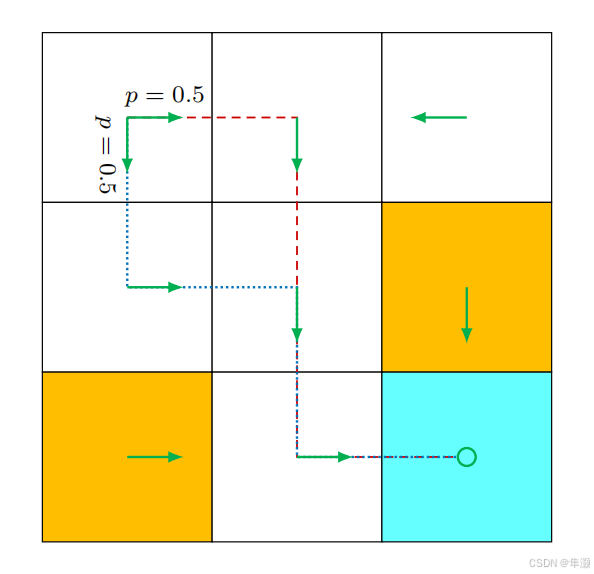
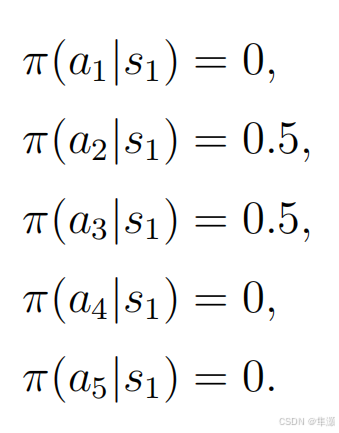
这个策略也可以用这种表格的形式来表达出来,比如说这个每一行都对应了一个状态,每一列都对应了一个action。像 s5 它采取往下走的这样一个action ,它的概率是1,所以这个对于s5来说 它是有一个确定性的策略。那么对于s1来说,它有0.5的概率是a2,0.5的概率是a3,所以对s1来说它是一个不确定性 stochastic 的一个策略,这种表格实际上它是非常general的。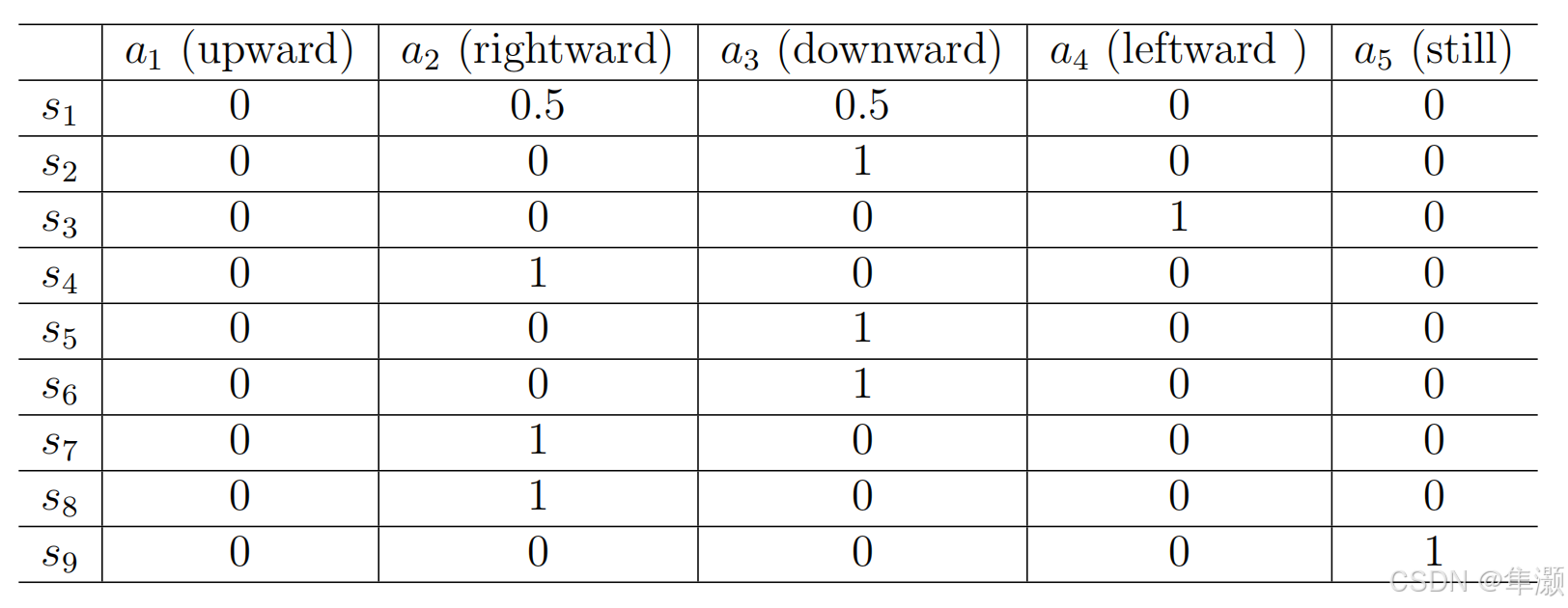
Reward
Reward是强化学习当中非常有独特性的一个概念。Reward是什么呢?首先它是一个数,它是一个实数,它是一个标量,在agent采取了一个动作之后它会得到这样一个数,这个数是有一定含义的,如果这个数是正数 代表我们对这样的行为是鼓励的,如果这个数是一个负数代表我们不希望这样的行为发生,实际上是对行为的一个惩罚。
Reward实际上是可以被理解成是一个human-machine interface,就是我们和机器进行交互的一种手段。

举个例子,在我们这个grit-world example当中 我们是这样设计reward的:
- 如果agent想要去逃出四周的这样一个边界,每次它有这样的动作的时候,我们就会给它一个负数 r bound=-1;
- 如果agent是要进到forbidden area里面去,有这样的倾向的时候 我们会给它 r forbid=-1;
- 如果agent进到了target area,那么由于到达了目标 我们会给它鼓励 让它的r target=+1;
- 其它的所有agent采取的行动得到的reward都是0。
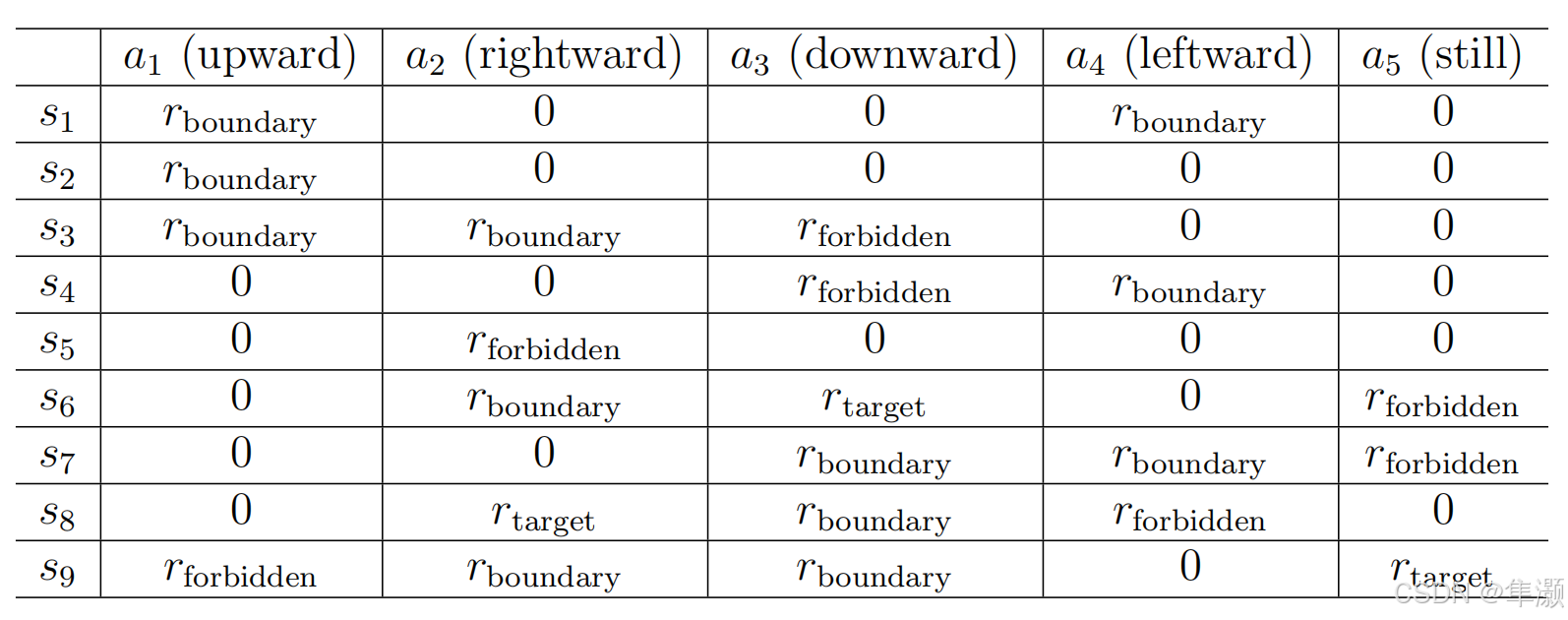
这个表格它的每一行对应的是一个状态,它的每一列对应的是一个action。比如说在这样一个状态s1当中 我采取了action a1,我得到的一个reward的就是r bound
这个表格相对来说还是比较直观的,但是它的问题就是说它应用的还是比较有限的。为什么?因为它只能来表示determinisric的情况。什么是determinisric?就是说我在一个状态 我采取了一个行动
我一定会得到一个什么样的reward,但是实际上可能会得到reward的大小是不确定的。
这时候我们可以用一种更加一般化的方法,用条件概率。
![]()
上面公式表示,我在s1 我选择a1 我得到-1的 probability 是1;我得到不是-1的probability是0。这个也是确定性的,我在这个状态采取这个行动 我一定会得到那个reward。
也会存在这种 stochastic 这种 reward ,比如说我们学习得非常地努力 那么我一定会得到reward,但是我能得到多少reward,可能是有很多因素所决定的,这可能是有一定随机性的,但是我们努力学习这样一个action还是值得我们去鼓励的,所以一定会得到一个正的reward,究竟多少的话 具体的值可能是不确定的。
另外,需要强调的是 Reward它一定是依赖于当前的状态和action,而不是依赖于下一个状态。
Trajectory
实际上是一个叫state-action-reward一个链。
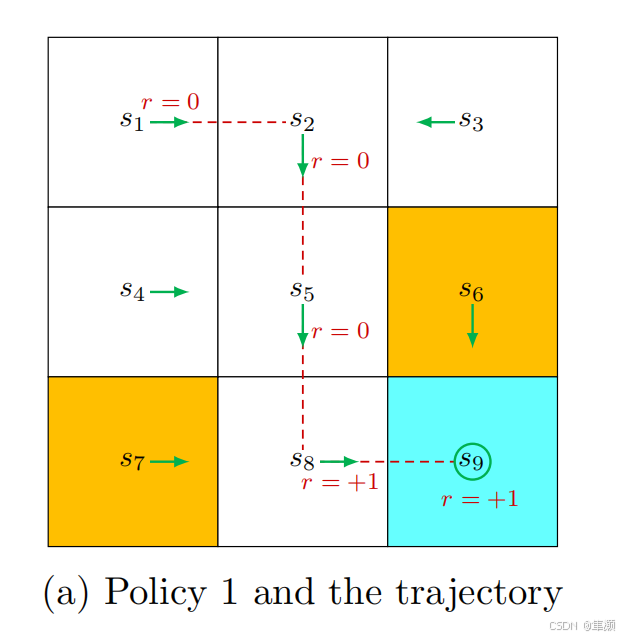
具体来说 比如说考虑这样一个trajectory,初始状态是s1,然后take action a2,得到一个reward 0,到达s2。然后再接着take action a3, 得到一个reward 0,这样持续下去一直最后就到了s9。那这样一个链就被称为一个trajectory,这里边包含了三个部分:状态、action、reward。
Return
Return是针对一个trajectory而言的,是把沿着这个trajectory所得到的所有的reward加起来。
Episode
首先episode会伴随一个叫 terminal state,也就是一个最终会停止的 trajectory 。一个episode通常都是有限步的,这样的任务也被称为episodic tasks。有些任务它是没有terminal state的,意味着agent和环境的这样的交互会永远地持续下去,这样的任务呢就成为continuing tasks。
Markov decision process (MDP)
关键要素:

- 第一个集合就是 State
- 第二个集合就是 Action
- 第三个集合就是 Reward

- 第一种是state transition probability,也就是我当前是在s ,那么我如果采取一个行动 我跳到s’它的概率是多少。
- 第二种就是reward probability,我当前是在s 我 take action a 那么我得到r 它的probability是多少。

- 我在状态s 我有一个策略,这个策略会告诉我采取action a它的概率究竟是多少 。

是和历史无关的一个性质,通过这个式子会比较清晰地看出来。比如说我最开始的状态是s0 ,然后我采取了一个action,慢慢地我走到 st 的时候 ,我采取了一个action 是at。这时候我跳到下一个状态st+1的概率等于什么呢?它等于我完全不考虑这些历史,我也不管我之前是在什么地方,反正现在我是在st,现在我是take action at然后我会跑到st+1 。它俩的概率是一模一样的,也就是说你之前的历史是完全没有关系的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









