







 本文档详细介绍了如何在Ubuntu主节点和CentOS从节点上部署Hadoop大数据环境,包括用户组添加、权限配置、SSH免密登录的实现,以及Hadoop的安装和配置步骤。通过这些步骤,可以在不同操作系统间实现Hadoop集群的稳定运行。
本文档详细介绍了如何在Ubuntu主节点和CentOS从节点上部署Hadoop大数据环境,包括用户组添加、权限配置、SSH免密登录的实现,以及Hadoop的安装和配置步骤。通过这些步骤,可以在不同操作系统间实现Hadoop集群的稳定运行。
前言:主节点(Master)部署在Ubuntu上,从节点(slave1)部署在centos上,配置这样的Hadoop大数据环境。
注意网络配置在上一篇博客!!!!
用户组添加
CentOS操作系统
1.使用以下代码添加hadoop用户,并设置密码:
adduser hadooppasswd hadoop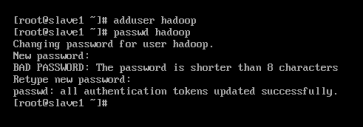
2. 给hadoop用户添加管理员权限(后续的实验可能使用到管理员权限)使用以下代码:
chmod -v u+w /etc/sudoers #更改sudoers文件权限后才能对其进行修改
vi /etc/sudoers #修改sudoers文件
chmod -v u+w /etc/sudoers 
vi /etc/sudoers找到## Allow root to run any commands anywhere后在root一行下方添加下列代码:
hadoop ALL=(ALL) ALL #此行代码表示赋予刚才新建的hadoop用户root权限
保存退出后将sudoers文件权限改回使用下列代码:
hadoop ALL=(ALL) ALL
chmod -v u-w /etc/sudoers #将sudoers文件权限改回原始状态
chmod -v u-w /etc/sudoers 
Ubuntu操作系统
使用以下以命令创建hadoop用户:
sudo useradd -m hadoop -s /bin/bash使用以下命令为hadoop用户设定密码:
sudo passwd hadoop使用以下命令赋予hadoo用户超级权限
sudo adduser hadoop sudo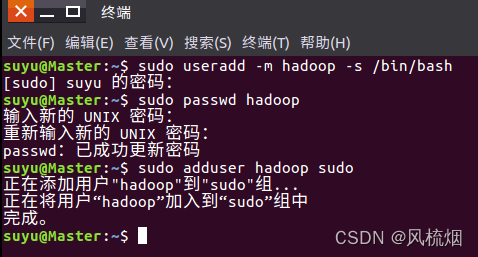
免密登陆
免密登陆的原理
每个服务器中初始时没有.ssh文件夹,使用shh登陆命令一次后会自动产生.ssh文件夹
.ssh文件夹中初始没有authorized_keys文件,生成id_rsa.pub文件后可以使用cat命令将其加入

首先在集群中各节点登陆一次ssh为了创建.ssh文件夹,注意此处请切换到hadoop用户
Ubuntu操作系统使用以下命令:
su - hadoop
ssh localhost #登陆ssh
exit #退出ssh登陆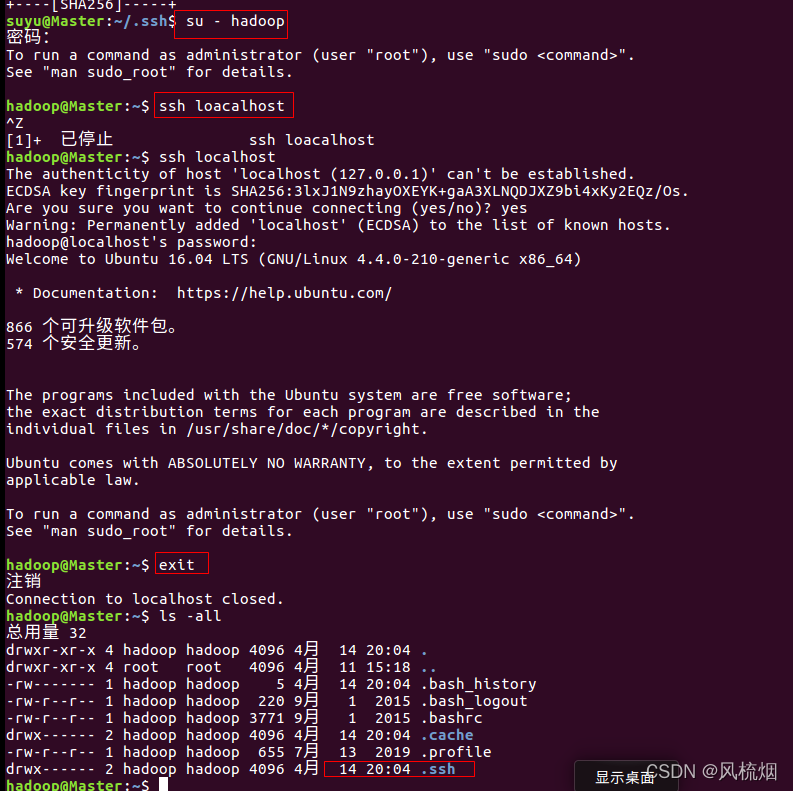
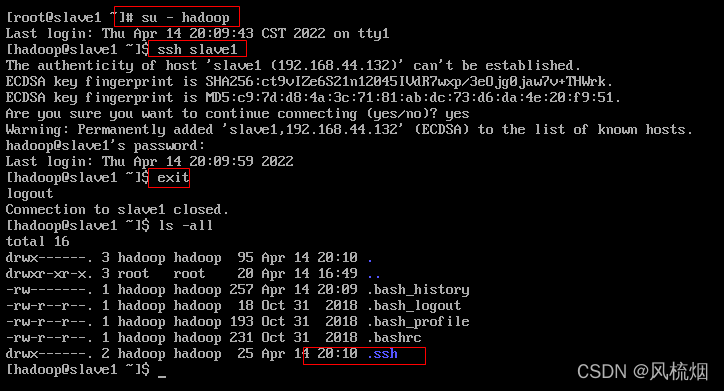
CentOS操作系统使用以下命令:
su - hadoop
ssh slave1
exit
生成公钥
在集群中每个服务器使用以下命令生成秘钥文件:
在Ubuntu中使用以下代码:
cd ~/.sshssh-keygen -t rsa在次过程中只需要一路回车到结束即可
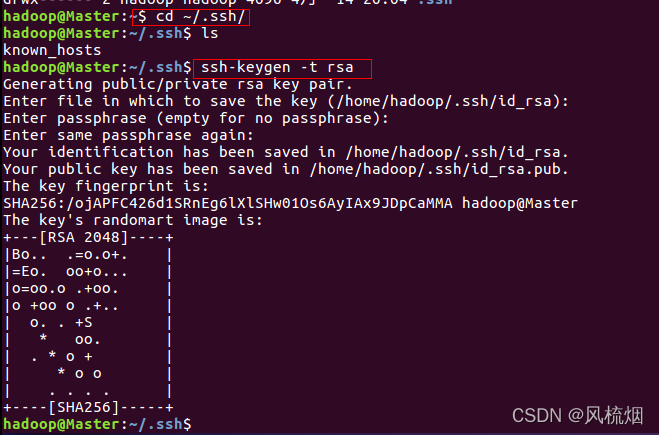
在CentOS中使用以下代码:
cd ~/.sshssh-keygen -t rsa与Ubuntu同理
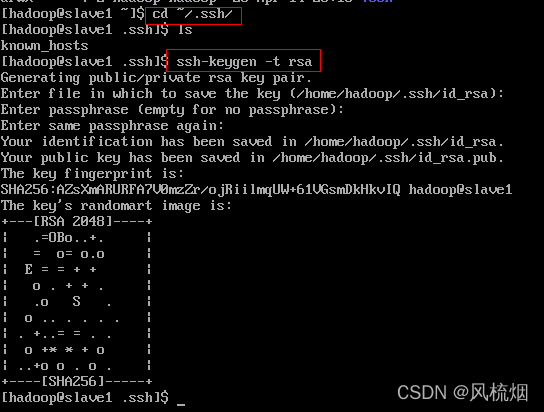
将公钥相互传输
在Ubuntu系统中使用以下代码:
scp -r id_rsa.pub hadoop@slave1:/home/hadoop #将Master节点的公钥传输给slave1此过程需要输入slave1中hadoop用户的密码

在CentOS系统中使用以下代码
scp -r id_rsa.pub hadoop@Master:/home/hadoop #将slave1节点的公钥传输给Master同理需要输入Master中的hadoop用户密码
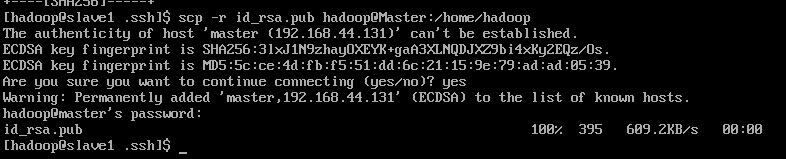
相互将公钥放到验证文件中
注意此处刚才传输的公钥都放在/home/hadoop文件夹下
但是authorized_keys文件在/home/hadoop/.ssh文件夹下才生效
在Ubuntu系统中使用以下命令:
cat /home/hadoop/id_rsa.pub >> authorized_keys
同理在CentOS系统中使用以下命令:
cat /home/hadoop/id_rsa.pub >> authorized_keys
测试免密登陆是否生效
在CentOS系统中使用以下命令:
ssh Master
exit 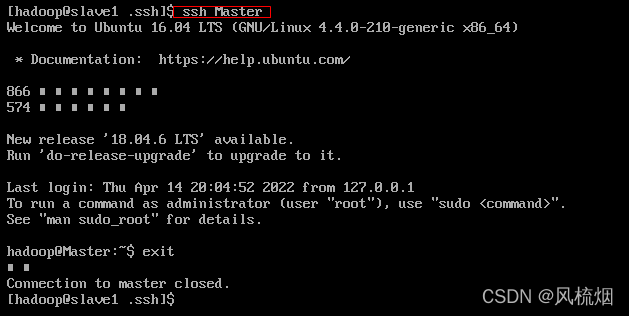
免密登陆成功
在Ubuntu系统中使用以下命令:
ssh slave1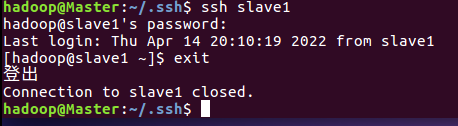
注意此处我们的免密登陆是不成功的,原因是因为
我们的CentOS系统中的.ssh文件夹和authorized_keys文件权限有问题
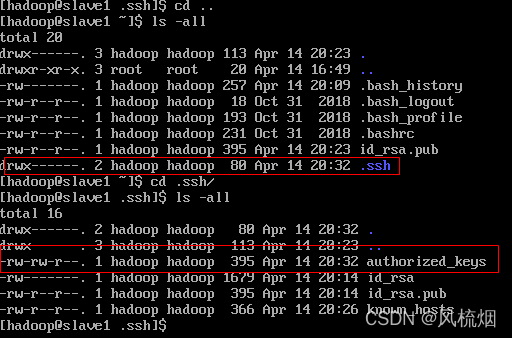
使用以下命令修改权限
chmod 0755 /home/hadoop
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
再次到Master中尝试免密登陆:
ssh slave1 
免密登陆成功
安装并配置Hadoop
因为我们的CentOS还没有jdk所以我们将jdk先解压安装
1.传输安装包,这里顺便把hadoop也传输进去(在Ubuntu系统同样操作)
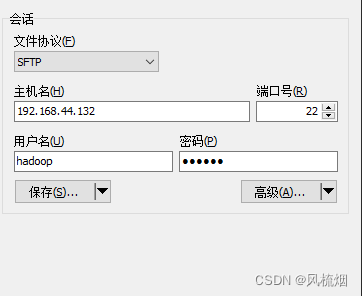
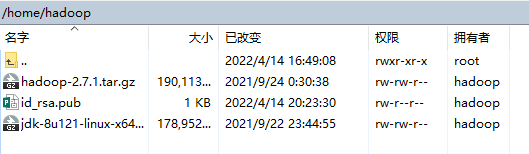
2.解压jdk并配置环境文件
cd ~
tar -zxf jdk-8u121-linux-x64.tar.gz
cd /usr/lib
sudo mkdir jdk #注意使用sudo命令创建jdk文件夹
sudo mv ~/jdk1.8.0_121/ /usr/lib/jdk #移动jdk到/usr/lib/jdk文件夹中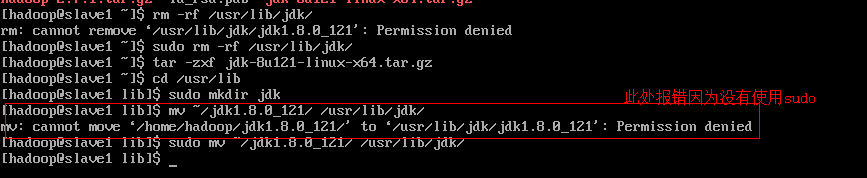
编辑/etc/profile环境变量(此处直接把hadoop的环境变量也加进去)
因为/etc/profile文件超级用户才可以修改,我们切换回超级用户
su -
vi /etc/profile加入以下环境变量代码:
#java setting
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_121
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
#hadoop setting
export HADOOP_HOME=/home/hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin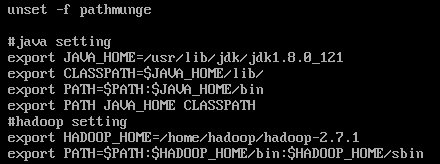
source /etc/profile #刷新环境变量文件
java -version

解压并配置hadoop环境变量
1.首先在Ubuntu系统解压hadoop
tar -zxf hadoop-2.7.1.tar.gz2.编辑hadoop环境变量
vim ~/.bashrc 在.bashrc中添加以下环境变量代码(其实和CentOS中相同)
#java setting
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_121
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
#hadoop setting
export HADOOP_HOME=/home/hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin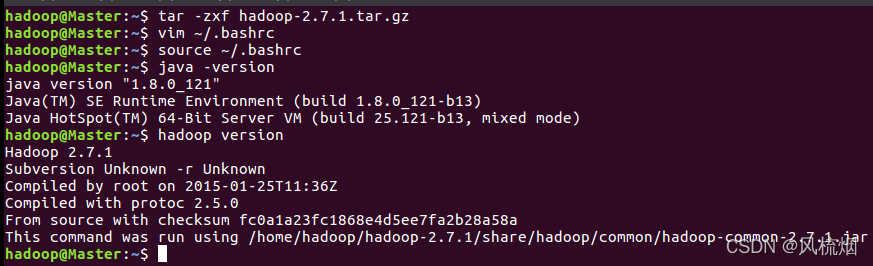
配置hadoop文件
1.配置hadoop中的 env.sh文件
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-env.sh 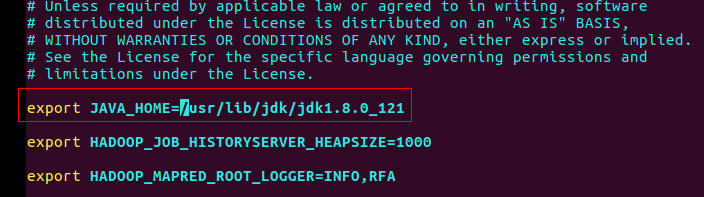
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/yarn-env.sh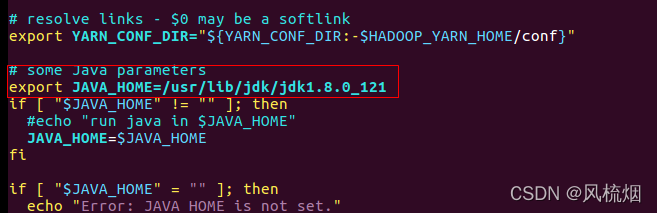
2.配置 core-site.xml文件
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/core-site.xml<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopfile</value>
</property>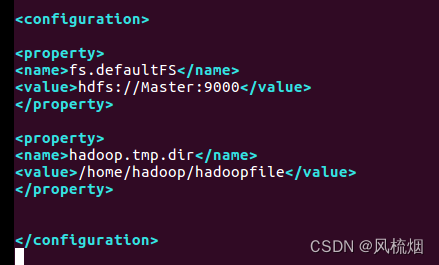
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
· <value>Master:50090</value>
</property>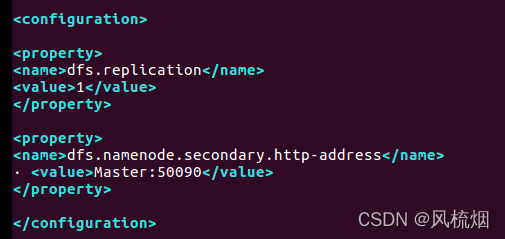
mv /home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.template.xml /home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml #因为mapred.site文件是个模板所以需要利用模板生成一个可用文件
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>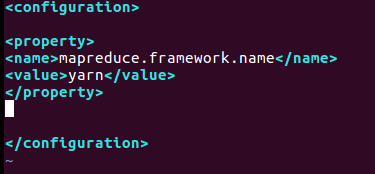
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>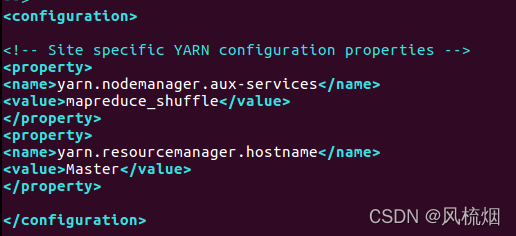
vim /home/hadoop/hadoop-2.7.1/etc/hadoop/slaves
Master
slave1
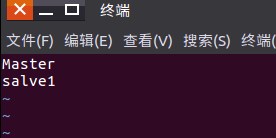
将配置好的文件传输给slave1
scp -r /home/hadoop/hadoop-2.7.1 hadoop@slave1:/home/hadoop 
格式化hdfs启动hadoop集群
cd /home/hadoop/hadoop-2.7.1/sbinhdfs namenode -format #再次重申不要多次使用这个命令,只有安装好hadoop第一次启动前才使用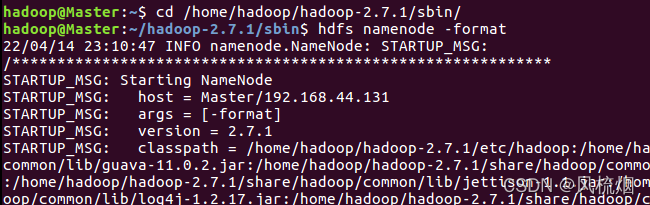
启动hadoop集群
cd /home/hadoop/hadoop-2.7.1/sbin
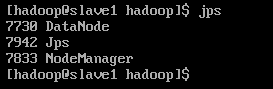
start-all.sh 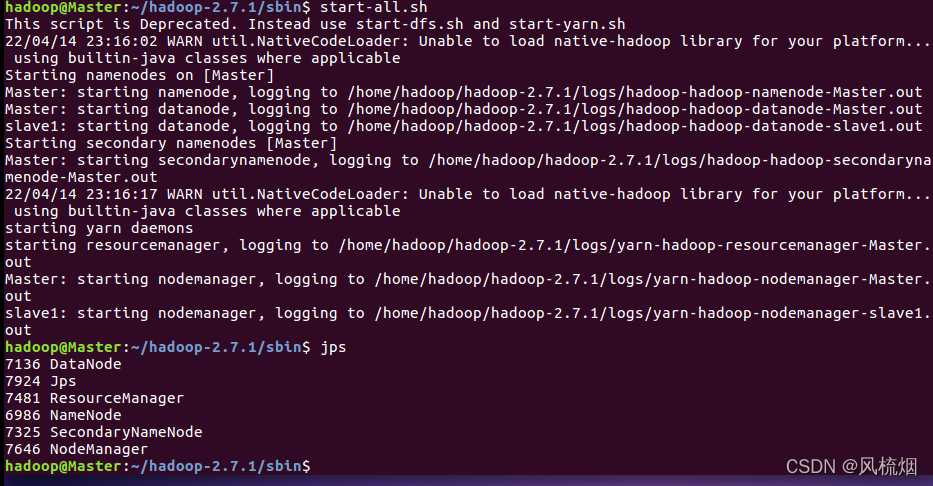


















 8647
8647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











