







一、JVM解析
jvm是Java Virtual Machine (Java虚拟机) 的缩写,jvm是一种用于计算设备的规范,它是一个虚拟出来的计算机,是通过再实际的计算机上仿真模拟各种计算机功能来实现的。Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入了Java虚拟机后,Java语言在不同平台上运行时不需要重新的编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成虚拟机上运行的目标代码(字节码),就可以在各种平台上不加修改的运行,Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行,这就是Java的能够"一次编译,到处运行的原因"
也就是说java是一门跨平台的语言是因为java运行在jvm中,但是jvm是分不同版本的,只要我们把需要运行的java代码放在不同版本的jvm当中,那么就可以实现java的一次编译到处运行
二、JVM的生命周期
jvm也是有生命周期的,当jvm运行的时候,jvm就相当于一个软件,存在于内存当中,
jvm的启动
启动一个java程序时,一个JVM实例就产生了,任何一个拥有public static void main(String args[]) 函数的class 都可以作为jvm实例运行的起点
jvm在javase当中 当启动main方法的时候jvm就会启动
在javaWeb当中当tomcat启动的时候,就会启动jvm
jvm的运行
main()作为该程序初始线程的起点,任何其他线程均由该线程进行启动
jvm在javase当中 当程序在main方法中进行逻辑语句计算的时候,jvm就在运行
在javaWeb当中 当tomcat运行的时候,jvm就会运行
jvm的消亡
当程序中的所有非守护线程都终止时,JVM才退出,若安全管理器允许,程序也可以使用Runtime类或者System.exit() 来退出
【finally一定会执行到吗】 不一定,当在finally之前执行了System.exit() 那么finally就不会被执行
【总结】当在电脑上运行一个程序时,就会运行一个java虚拟机,java虚拟机总是开始于main方法,main方法时线程的起点
三、java的线程
java的线程一般分为两种:守护线程和普通线程。
守护线程:是java虚拟机自己使用的线程,比如GC线程(垃圾回收) 就是一个守护线程,当然你可以把自己的线程设置为守护线程。
【注意】main方法启动的初始线程不是守护线程
普通线程: java中我们编写的线程
只要java虚拟机中还有普通线程在执行,java虚拟机就不会停止,如果有足够的权限,你可以调用exit() 方法终止线程
四、jvm的体系结构

类加载器
当我们编写.java文件的时候,我们经过javac编译之后会变成.class文件,此时我们的文件放在了磁盘当中,jvm中的类加载器会把磁盘中的文件放在电脑的内存当中,我们的java程序必须在内存里才能够运行
类加载器的任务是根据类的全限定名(包名) 来读取类的二进制字节流(.class文件)到JVM中,然后转换成一个与目标类对象的java.lang.Class对象的实例,在虚拟机中提供三种类加载器,启动类加载器,扩展类加载器,应用类加载器
启动类加载器(Bootstrap Class-Loader) , 加载jre/lib包下面的jar文件,比如说常见的rt.jar
扩展类加载器(Extesion or Ext Class-Loader) , 加载jre/lib/ext 包下面的jar文件
应用类加载器(Applocation or App Class-Loader) , 根据程序的类路径(classpath)来加载java类,也就是加载我们自己引的额外的jar包
【类加载器的加载顺序】
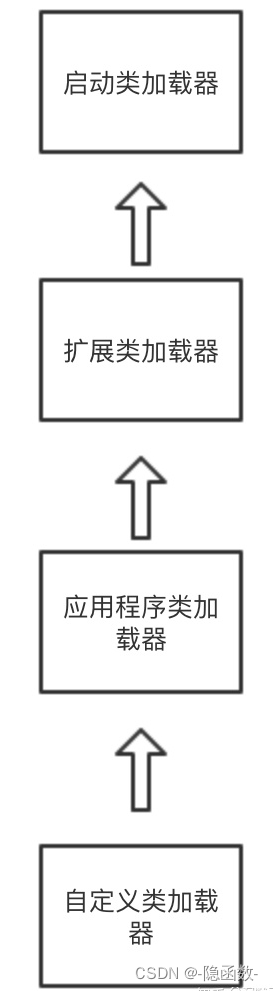
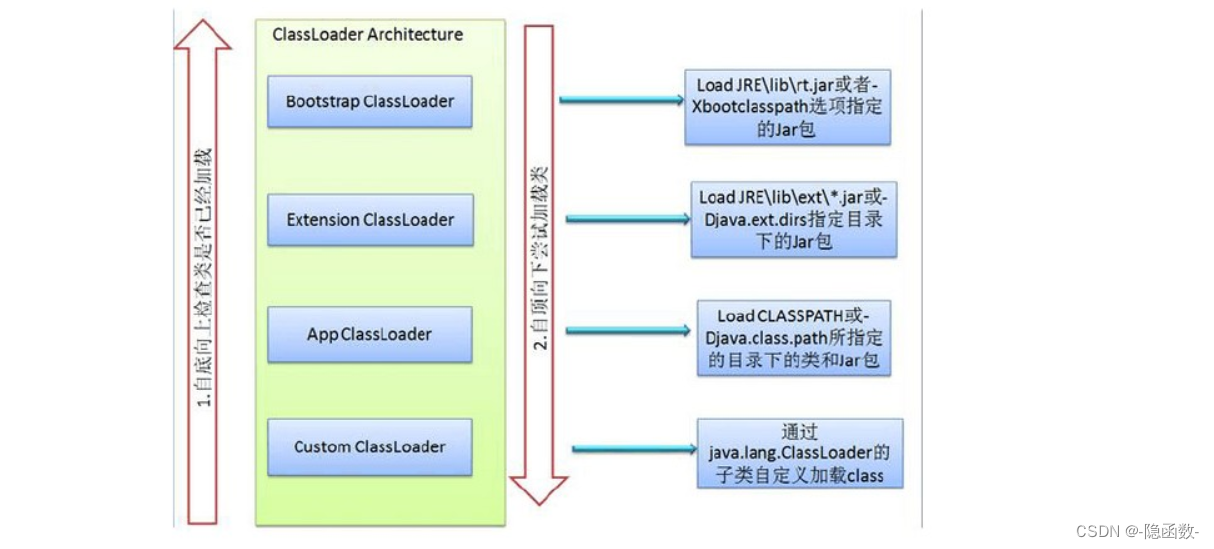
运行的时候:应用程序类加载器---> 扩展类加载器 ---> 启动类加载器
当程序运行的时候先加载应用程序类加载器,检查该加载器发现有一个父加载器叫做扩展类加载器,检查扩展类加载器的时候发现有一个父加载器叫做启动类加载器
加载的时候:启动类加载器---> 扩展类加载器 ---> 应用程序类加载器
【什么是双亲委派模型】
一旦父加载器加载过某个类,子加载器就不再加载,因为在加载的时候是通过完整的包名,类名来判断,jvm中不允许存在和系统一模一样的类,目的是禁止破坏java
【自己编写一个类,包名,类名和系统的完全一致,能否被加载运行,为什么】
正常来说,不能够被运行,因为jvm中不允许存在和系统一模一样的类,因为这样会发生安全问题,破坏java,但是如果我们可以破坏双亲委派模型,这样的话就可以进行加载了
【如何破坏双亲委派模型】
【类加载器的加载过程是什么】
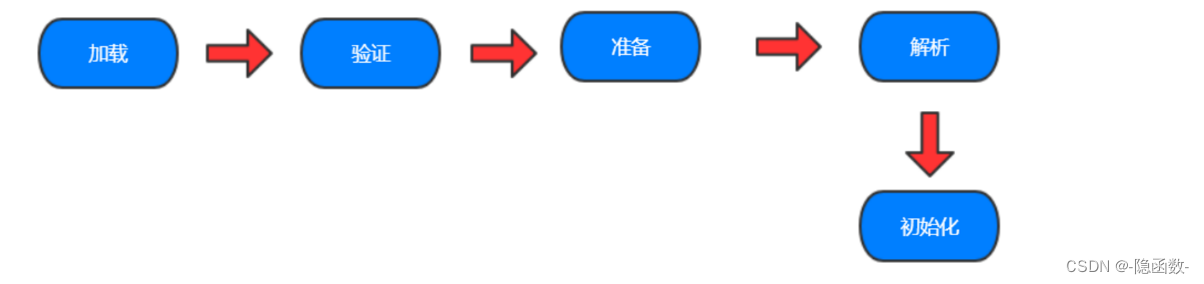
加载Loading
类加载过程的一个阶段,ClassLoader通过一个类的完全限定名查找此类的字节码文件,并利用字节码文件创建一个对象 JVM在该阶段的主要目的是将字节码从不同的数据源(可能是class文件、也可能是ajr包、甚至网络的包)转化为二进制字节流加载到内存中,并生成一个代表该类的java.lang.Class对象
验证Verification
目的在于确保class文件的字节流中包含的信息符合当前虚拟机的要求,不会危害到虚拟机自身的安全,主要包括四种验证,文件格式的验证,元数据的验证,字节码的验证,符号引用验证
JVM会在该阶段进行一些重要的检查
-
确保二进制字节流格式符合预期(比如说是否以
cafe bene开头)。 -
是否所有方法都遵守访问控制关键字的限定。
-
方法调用的参数个数和类型是否正确。
-
确保变量在使用之前被正确初始化了。
-
检查变量是否被赋予恰当类型的值。
准备Preparation
为类变量(static修饰的字段变量) 分配内存并且设置该类变量的初始值,如static int i = 5 这里只是将 i 赋值为0,在初始化的阶段再把 i 赋值为5),这里不包含final修饰的static,因为final在编译的时候就已经分配了,这里不会为实例变量(无static修饰的)分配初始化,类变量会分配在方法区中,实例变量会随着对象分配到java堆中
解析Resolution
这里主要的任务是把常量池中的符号引用替换成直接引用
该阶段将常量池中的符号引用转化为直接引用。
符号引用:
以一组符号(任何形式的字面量,只要在使用时能够无歧义的定位到目标即可)来描述所引用的目标
直接引用:
通过对符号引用进行解析,找到引用的实际内存地址,将符号进行替换掉
因为常量在编译的时候就已经分配了内存,以String举例子,String的底层就是final修饰的char,假如说在不同的作用域或者不同的方法中我们定义了两个String类型的变量 全部赋值为abc,abc这个时候在常量池当中的 在刚开始创建的时候我们创建并不会直接给我们赋值abc而是用符号来代替,所以说编译的时候我们并不是直接给他存值,而是用符号进行记录,在解析的时候我们去常量池进行查询,看常量池中有没有我们需要的值,这个值的内存地址我们在编译的时候就已经创建了
初始化Initialization
这里是类加载的最后阶段,如果该类具有父类就进行父类的初始化,以及给静态变量进行赋值,执行静态代码块和静态初始化成员变量
【类加载的时机】
隐式加载:new创建类的实例
显示加载:loaderClass,forname等
访问类的静态变量,或者为静态变量赋值,调用类的静态方法
使用反射的方式创建某个类或者接口对象的Class对象 初始化某个类的子类
直接使用java.exe命令来运行某个主类
执行引擎
执行引擎就是用来执行我们的字节码,也就是执行我们的目标代码
运行时数据区
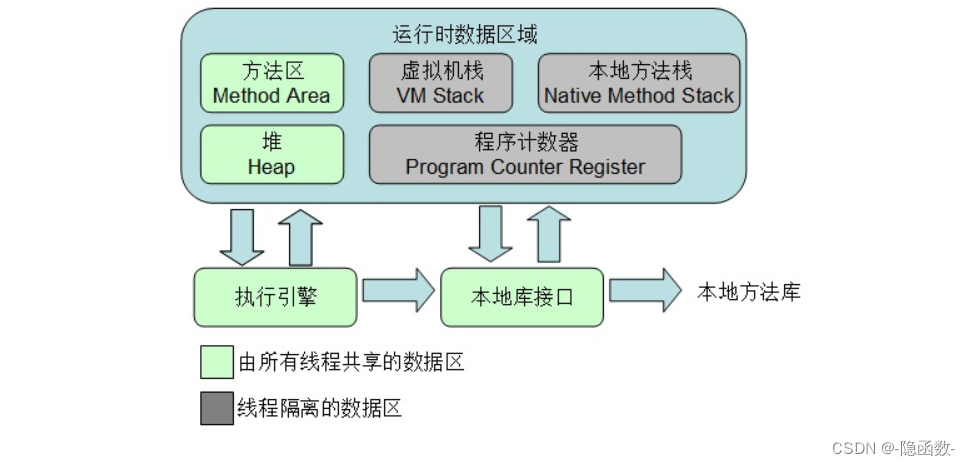
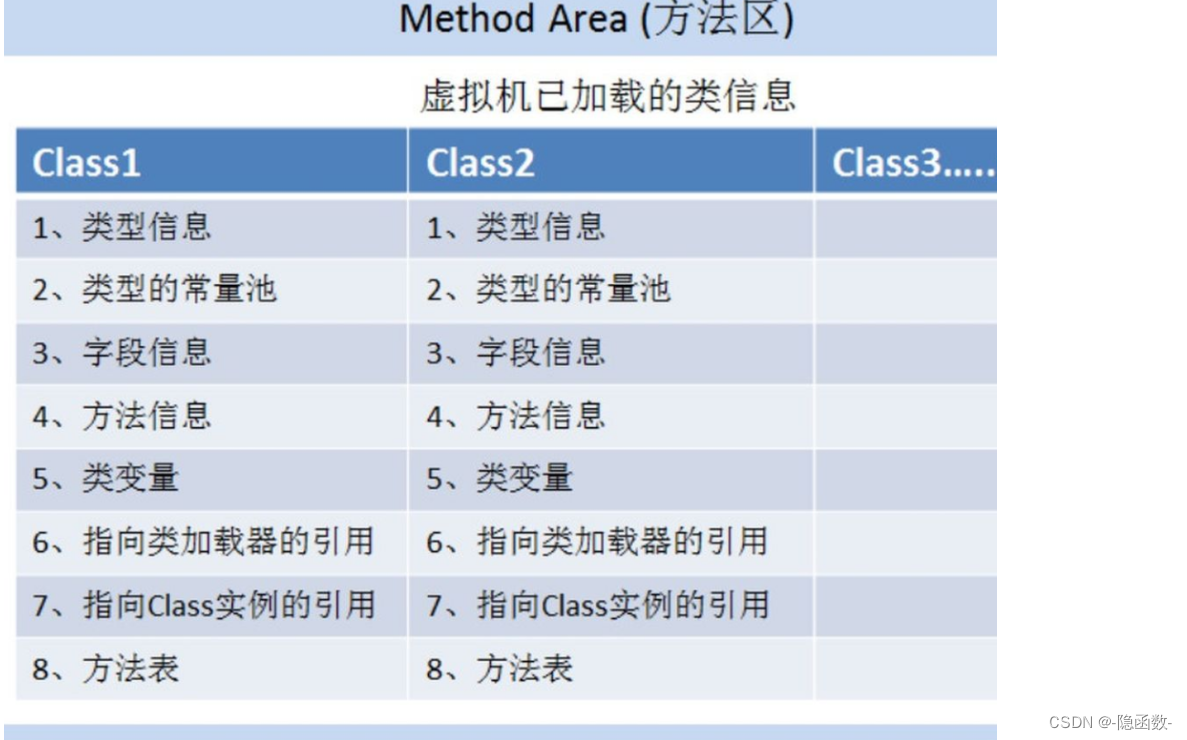
方法区:静态成员,常量,类的信息例如包名,类的构造方法信息 存的是类对象但是new出来的在堆中,方法区的内容各线程都可以使用,类加载器加载的东西在方法去里边
堆:new 的对象,也就是引用数据类型,堆空间的内容各线程都可以使用,只用堆需要GC回收
【说明】方法区和堆区的线程可以共享
本地方法栈:用来存储第三方的
虚拟机栈:用来存局部变量
程序计数器:用来记录多线程情况下,某一线程在时间片轮转的情况下轮转到了什么地方,下一次在该地方继续运行(也就是存行号的,记录代码运行到第几行了),程序计数器私有,每个线程都有自己的程序计数器,
【运行时数据区里的5个区域,都哪些会发生内存溢出的异常 】
方法区、虚拟机栈、堆
五、堆内存划分概述
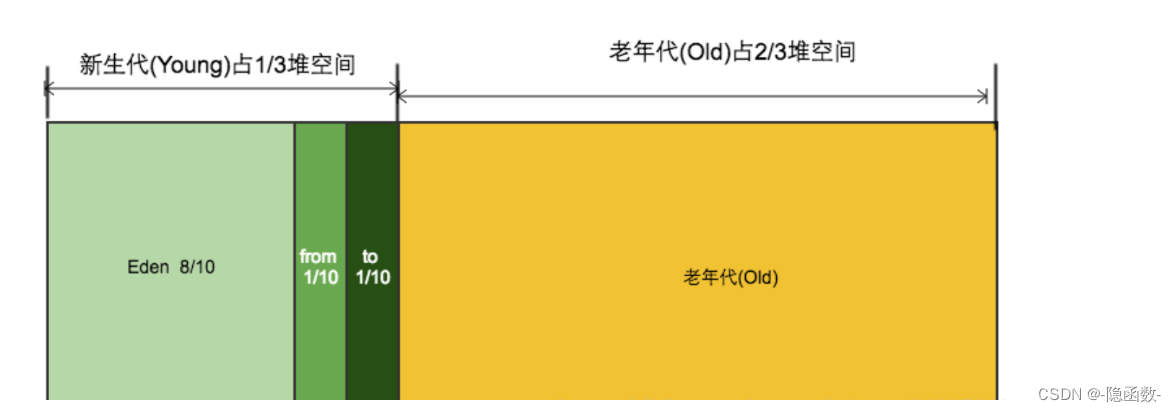
jdk1.8之前把堆内存划分为三个部分,分别是新生代,老年代,永久代 ,永久代是用来放我们的常量,静态变量,等,但是在jdk1.8开始,取消了永久代得概念,并把常量,静态变量拿到了我们的
方法当中去
【为什么分新生代和老年代】
降低GC的回收频率
一个对象创建完成也就是new之后,首先放在了新生代里的 E F 中,新生代对象经过一次GC回收之后,80%的几率被回收走了,新生代的垃圾回收算法叫做复制算法,复制算法的基本思想是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还存活的对象复制到另一块上面,复制算法不会产生内存碎片
在新生代当中一共分为三个区域,分别是 E区 F区 T区 F区和T区又叫S区
gc开始之前,对象存在E区和S区中的F区中,T区是空的,在经历过一次gc之后,我们把E区还存活下来的对象复制在T区,而f区根据年龄来划分,达到年龄这个阈值 15 的话(也就是回收了15次还没被回收掉,15可调节) 就移到了老年代,而没有达到的被复制到T区,这个时候E区和S区中的F区就被清空了
老年代中存放到是程序中声明周期较长的内存变量,采用的是清除算法,
六、GC的方法
GC可分为三种:Minor GC Major GC 和 Full GC
Minor GC :是清理新生代。触发条件:当Eden区满时,触发Minor GC。
Major GC:是清理老年代。是 Major GC 还是 Full GC,大家应该关注当前的 GC 是否停止了所有应用程序的线程,还是能够并发的处理而不用停掉应用程序的线程。
Full GC :是清理整个堆空间—包括年轻代和老年代。 触发条件:调用System.gc时,系统建议执行Full GC,但是不必然执行;老年代空间不足;方法区空间不足;通过Minor GC后进入老年代的平均大小大于老年代的可用内存;由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
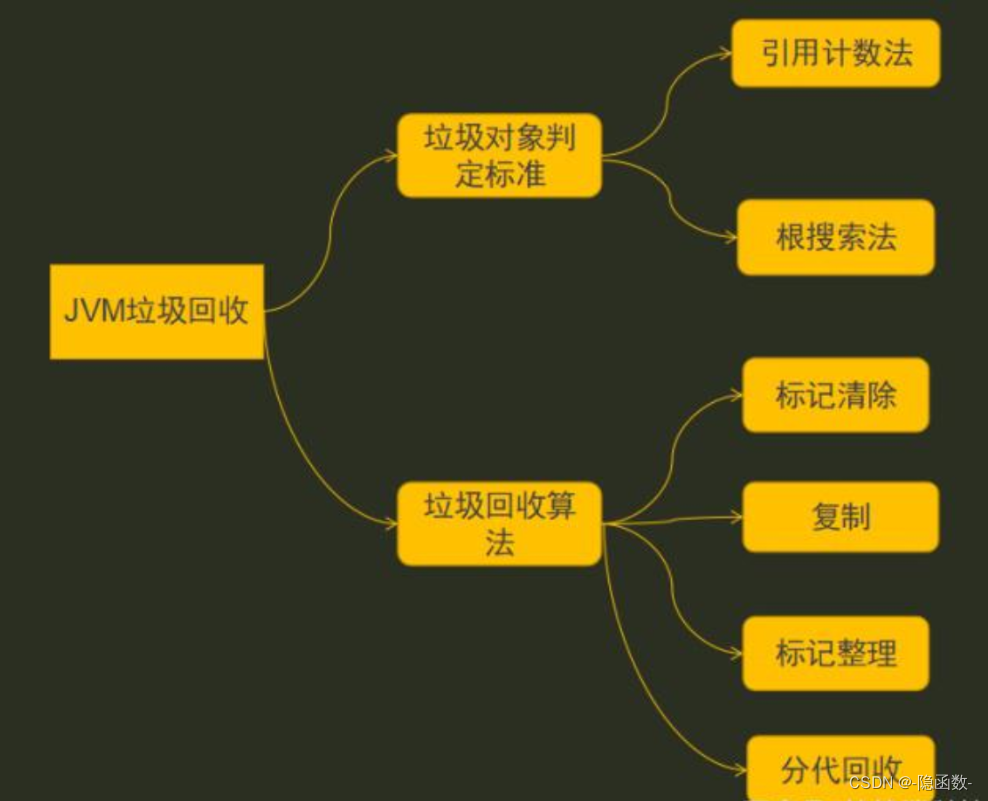
七、JVM垃圾回收算法
判断对象是否可回收的算法:引用计数法、根搜索法
垃圾回收算法可分为:标记清除法、复制法、标记整理法、分代回收法
引用计数法: 每个设置一个计数器,当引用这个对象时,计数器+1,引用完-1,计数器为0时,判定为可回收对象,但是不能解决循环依赖问题(A引B B引A的问题) 易造成内存泄漏 该算法已经放弃
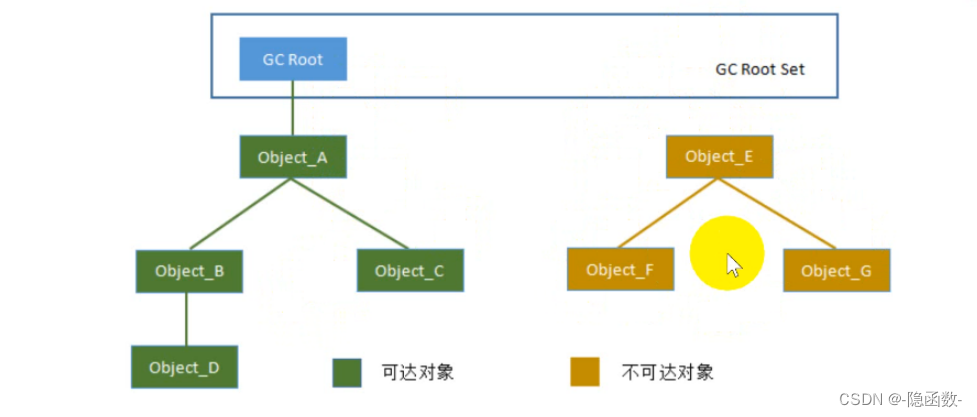
根搜索法(可达性算法):通过GC Root作为起始点,从起始点开始向下路径上的对象,搜索的路径称为引用链,当一个对象不在根节点开始的引用链之上,下边所有对象都不可达,进行回收
复制算法
复制算法,将完整内存区域分为大小相等的2块,每次只使用其中的一块,当这块内存满了(用完),则将此块内存上的对象都「复制」到另一块空内存上去,然后将用完的那块内存进行垃圾回收。这样的好处是将对象复制到空内存空间时由于是按顺序分配,只需要移动堆顶指针,实现起来简单高效,无内存碎片。
劣势:空间消耗比较大,一半的内存空间得不到利用
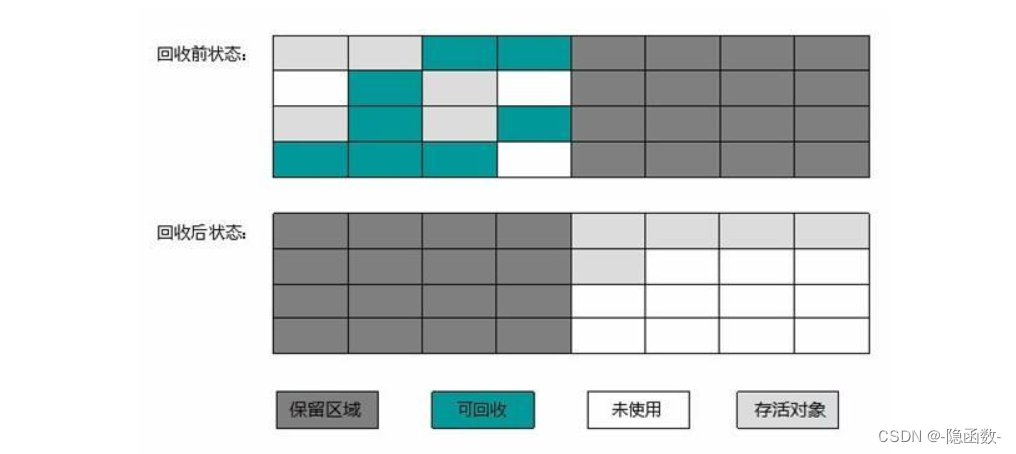
标记-清除算法
此算法主要分为“标记”和“清除”两个阶段, 首先标记出需要收集/回收的对象,在标记完成后将标记过的对象统一回收。标记清除算法是最基础的收集算法。
劣势:
效率较低,因为标记和清除这两个过程效率都比较低
空间问题,标记清除后会产生大量不联系的内存空间(碎片),导致如果有大内存的对象,那么就无法找到足够大的连续内存空间以供分配。
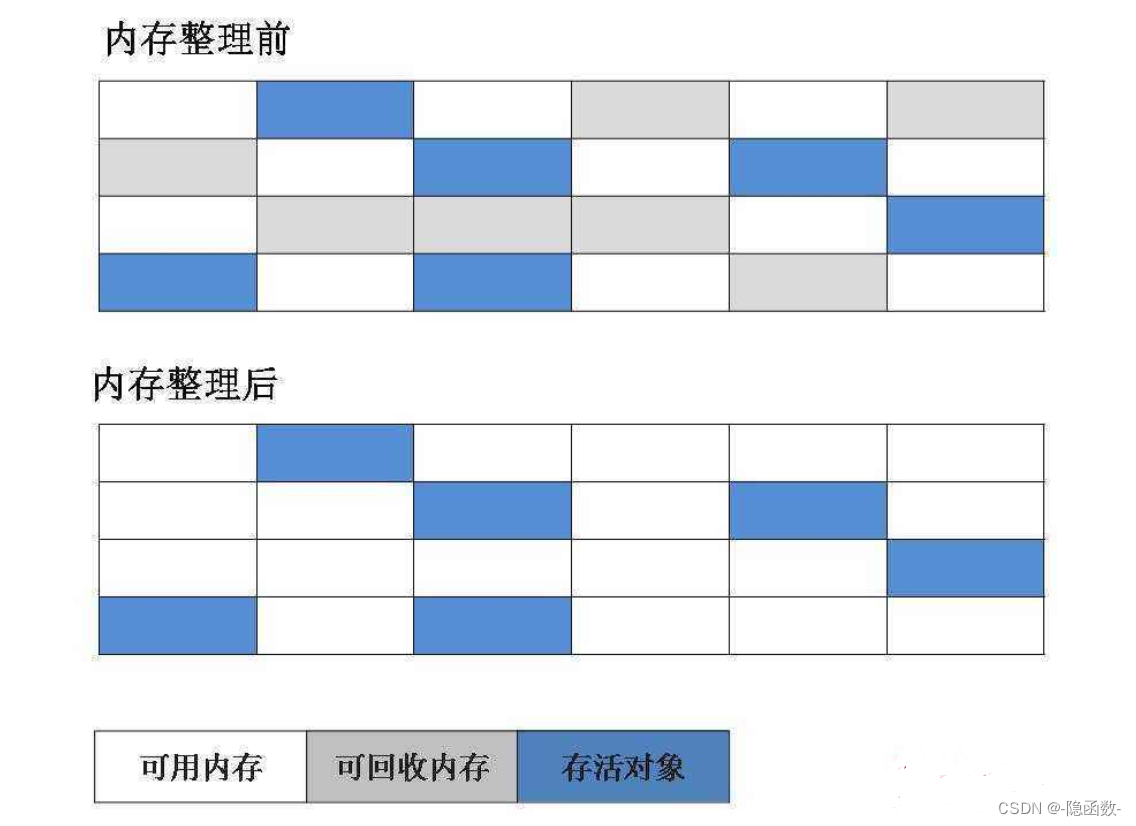
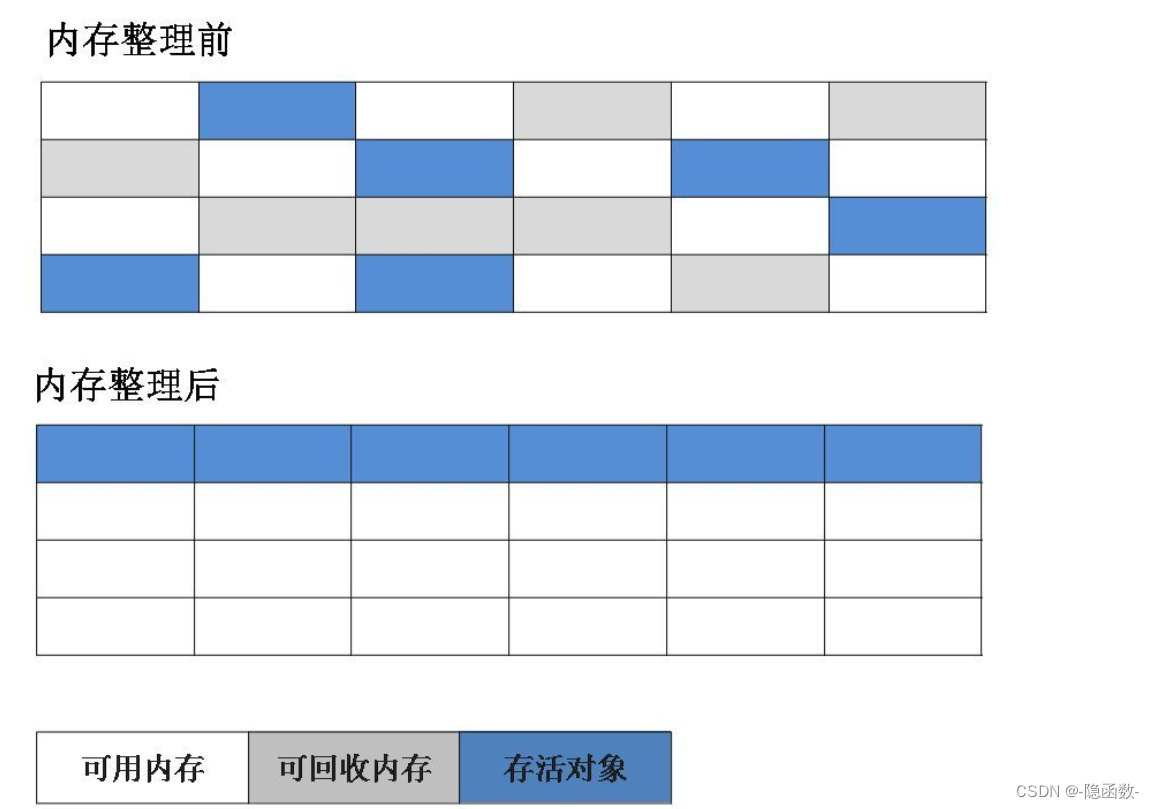
标记-压缩算法
压缩算法和清除算法类似,先通过标记找出等待回收的对象,然后在清除之前将存活的对象都整理整齐放到一边,然后再清除掉边界以外的内存,更适合老年代
8、JVM调优
JVM的调优,调的就是启动参数

jvm调优就是使用较小的内存占用来获得较高的吞吐量或者较低的延迟,当cpu过载太高,请求延迟特别慢,并发处理量降低,内存泄露等


















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









