








前言
更新TD3 和SAC 的实现,及其做的一些笔记。
顺便水一个1024徽章。
代码:https://github.com/wild-firefox/FreeRL/tree/main/SAC_file
TD3实现
TD3笔记
TD3: Twin Delayed Deep Deterministic policy gradient algorithm
论文: https://arxiv.org/abs/1802.09477 代码:https://github.com/sfujim/TD3/blob/master/TD3.py
论文认为:使用高斯噪音比使用OUNoise更好。
创新点:
1.双截断Q网络 a clipped Double Q-learning variant Q高估时也能近似真值 论文中:CDQ
2.目标策略加噪声 policy noise (目标策略平滑正则化) target policy smoothin 论文中:TPS
3.延迟更新策略网络和目标网络 delaying policy updates 论文中:DP
可借鉴参数:
hidden:256-256
actor_lr = 1e-4
critic_lr = 1e-3
buffer_size = 1e6
batch_size = 256
gamma = 0.99
tau = 0.005
std = 0.1 # 高斯noise
TD3独有
policy_std = 0.2 # 目标策略加噪声
noise_clip = 0.5 # 噪声截断
policy_freq = 2 # 延迟更新策略网络和目标网络
另外:论文中提出:可能使用组合的技巧,如:CDQ+TPS+DP 才会取得更好的效果,并在附录F中给出了消融实验。
在实验中可看出TD3作者写出的ourddpg(AHE),即DDPG_file中的DDPG_simple,比DDPG稍好一点(4个环境中1个环境落后一点,1个环境相差不大,一个环境领先一点,一个环境遥遥领先)
实验1中, 可得出单单加入创新点1,2,3 对于原算法,效果都有可能下降。
实验2中, 可得出同时加入创新点1,3,(1,2)(2,3) 对于原算法,效果都有提升。
实验3中, 可得出同时加入创新点2,3 对于原算法,效果有提升。
个人感悟
对于论文中的认为:1.使用高斯噪音比使用OUNoise更好。
个人在DDPG的实现中,发现两者的效果差不多,(一个使用高斯噪声,一个使用OUNoise)
但DDPG作者提到的4个细节技巧确实有对原DDPG有一些提升。
而TD3是DDPG上去掉这4个细节实现再加上自己的三个创新点,论文实验效果上是大幅超过DDPG。
个人感觉是有点效果,但效果不大。
对于论文的认为:可能使用组合的技巧才会取得更好的效果。
个人认同,具体我在DQN中加入不同trick后也发现了此问题。见:FreeRL】Rainbow_DQN的实现和测试
对比实验
我在MountainCarContinuous-v0 环境下进行了对比实验:
DDPG(有4个细节trick:具体见:【深度强化学习】DDPG实现的4个细节(OUNoise等))
在参数均一致的情况下
其中TD3独有参数如下:

两者的噪音均不进行衰减时,效果如下:
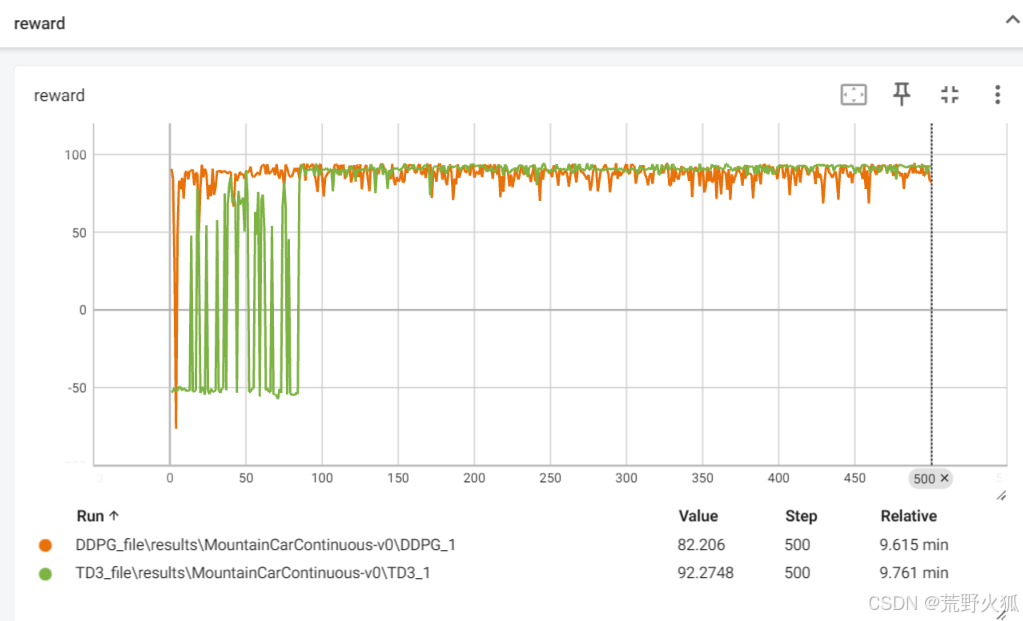
发现前期DDPG收敛较快,可后面震荡比TD3大。
在DDPG上加入OUNoise的噪声衰减后,效果如下:效果就比不加高斯噪声衰减的TD3好了。
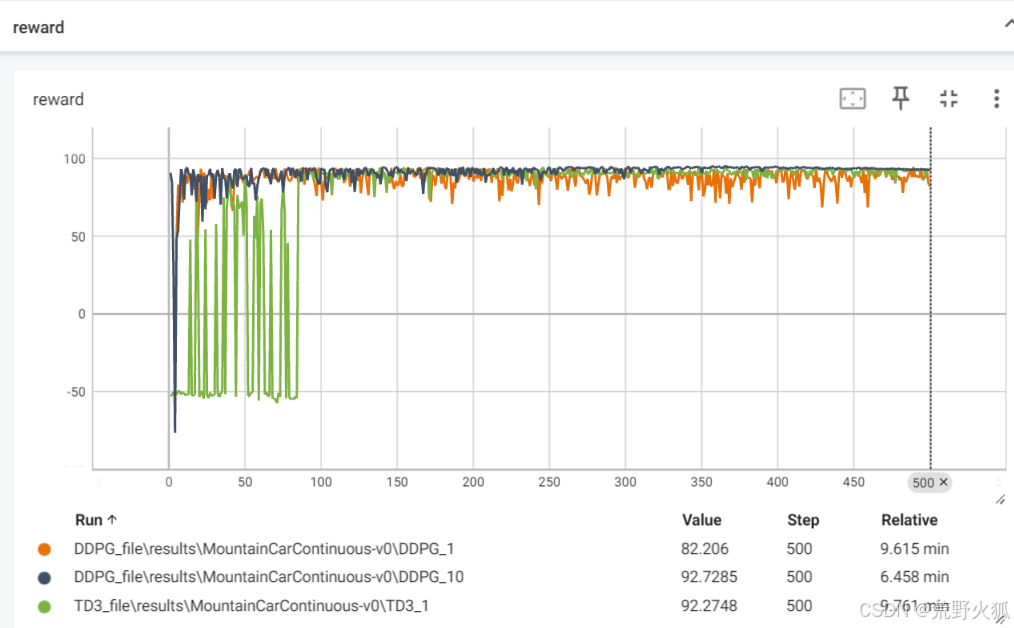
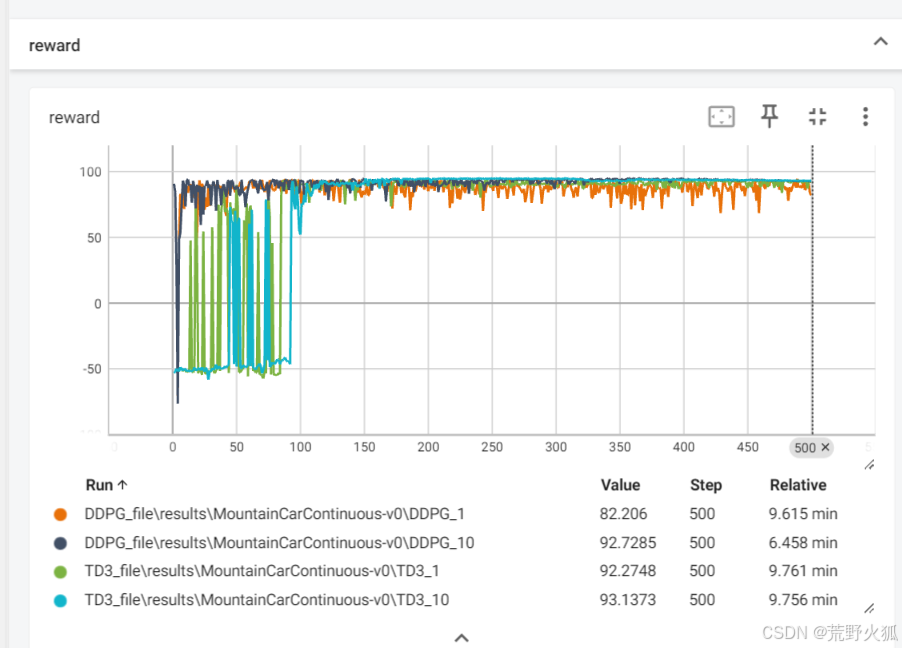
在TD3上也加入高斯噪音衰减后:
效果如下,比ddpg的稍微好一点。
转折
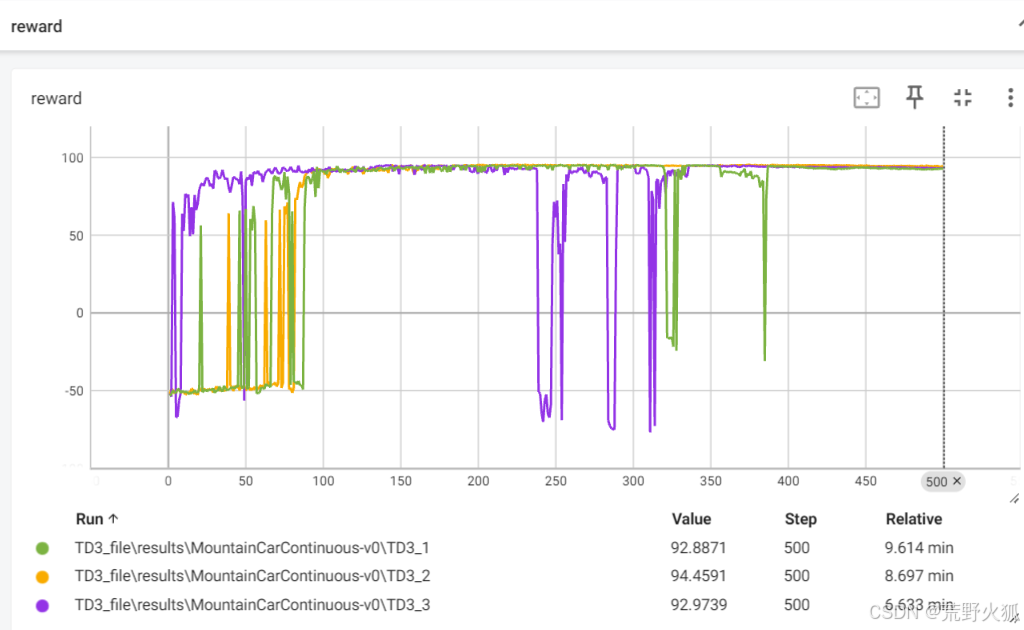
上述实验均在seed=0时实验(此时policy_noise = 0.2)
后续在其他seed上实验时,seed=10 ,100时,就不能收敛了,将policy_noise = 0.1 后又继续能收敛了。
个人认为TD3需要更多的调参。
seed=0,10,100的结果如下:
SAC实现
SAC笔记
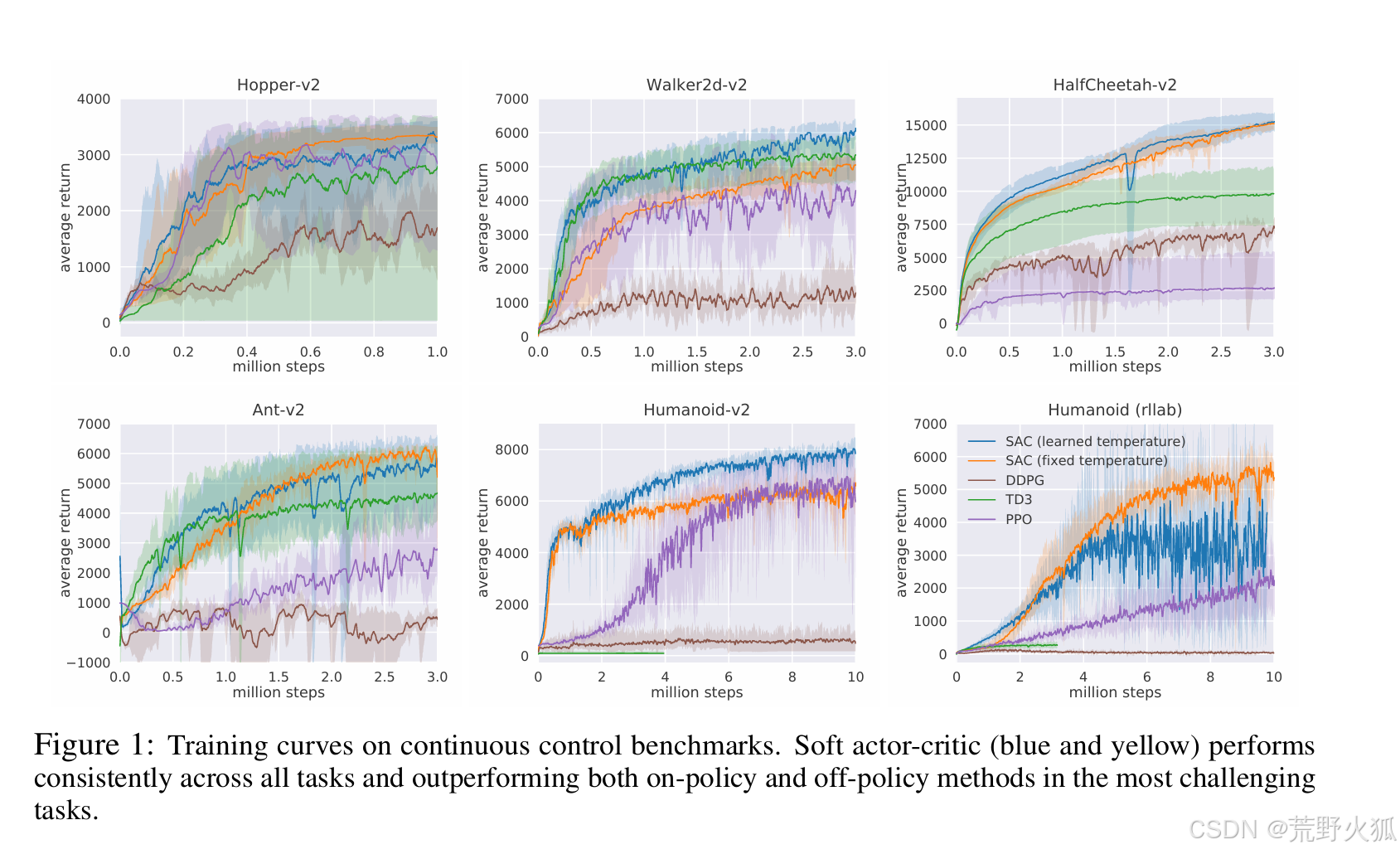
SAC 论文:https://arxiv.org/pdf/1812.05905 代码:https://github.com/rail-berkeley/softlearning/blob/master/softlearning/algorithms/sac.py
提出的sac有三个关键要素:1.独立的AC框架 2.off-policy 3.最大化熵以鼓励稳定性和探索
###此代码仅为continue的实现###
注:论文及代码做了continue环境下的实现,并未实现discrete环境下的实现。
创新点(或建议):
1.基于梯度的自动温度调整方法
2.使用类似于TD3一样的双截断Q网络来加速收敛
可参考参数:
hidden_dim 256-256
actor_lr = 3e-4
critic_lr = 3e-4
buffer_size = 1e6
batch_size = 256
gamma = 0.99
tau = 5e-3
sac独有
alpha_lr = 3e-4
entropy target = - dim(A)
‘’’
给出找到的两种discrete方法 这里实现了1
1.hangs-on 上的方法:https://hrl.boyuai.com/chapter/2/sac%E7%AE%97%E6%B3%95
补充:
2.与1类似但entropy的计算有所不同 https://zhuanlan.zhihu.com/p/438731114
个人感悟
actor部分 ppo与sac的相同和区别
相同:
1.测试时均是使用 action = tanh(mean)
2.高斯分布时 均是输出mean和std
不同:
1.sac需要对策略高斯分布采样(即使用重参数化技巧),而ppo不需要,因为ppo是更新替代策略(surrogate policy)
2.采样时sac action = tanh(rsample(mean,std)) ppo action = sample(mean,std)
3.计算log_pi时 1… sac的log_pi 是对tanh的对数概率,而ppo的log_pi是对动作的对数概率
(重要) 2… sac的log_pi 是直接对s_t得出的a_t计算的,而ppo的log_pi是对buffer中存储的s和a计算的(具体而言s->dist dist(a).log->log_pi)
critic部分 ppo与sac区别
区别:sac中critic输出Q1,Q2,而ppo中只输出V
离散实现
hands_on_discrete
1.策略网络的输出修改为在离散动作空间上的 softmax 分布;
2.价值网络直接接收状态和离散动作空间的分布作为输入。
对于2:相当于Q = probs * min(V)
对于论文中的讲述的双Q-learning方法,本质相当于TD3中的双Q截断法,有一点的区别是:
在更新target_Q时sac原论文代码中使用的是min,这点和TD3一致;
但在更新pi时TD3选取的是Q1,sac原论文代码取mean,网上一般做法是取min(比如hands_on上的方法)。
此论文基本上是认为加入此方法(双Q)会加快收敛。
从原理上来看,确实会减少高估,我持赞同态度。
对比实验
同样参数在MountainCarContinuous-v0 下进行实验。
经过实验,发现在此环境下,不使用自动调温度系数的方法,并且使用Batch_ObsNorm方法(在DDPG实现的4个细节(OUNoise等)实现)。
才会取得较好收敛。
原因猜测:探索不足,PPO在此环境下,也会出现和SAC类似的曲线(曲线在PPO的复刻和7个trick实现出现),由于ppo是online算法,所以只能是加上ObsNorm后,得到收敛到最优的结果。
而DDPG会比较好收敛的原因:是因为可以将探索的标准差调节的很大,容易探索到最优解(std=1);而std=0.1时,则也不能很好收敛。
实现如下:
蓝色:adaptive_alpha:False(默认alpha=0.01),Batch_ObsNorm:True
紫色:adaptive_alpha:True (默认alpha=0.01),Batch_ObsNorm:True
橙色:adaptive_alpha:False(默认alpha=0.01),ObsNorm:True
黑色:adaptive_alpha:True(默认alpha=0.01),ObsNorm:True
粉色:adaptive_alpha:False(默认alpha=0.01),Norm:False
绿色:adaptive_alpha:True(默认alpha=0.01),Norm:False
(其中部分我只运行了部分episodes,是推测后面也不会收敛,故切断)
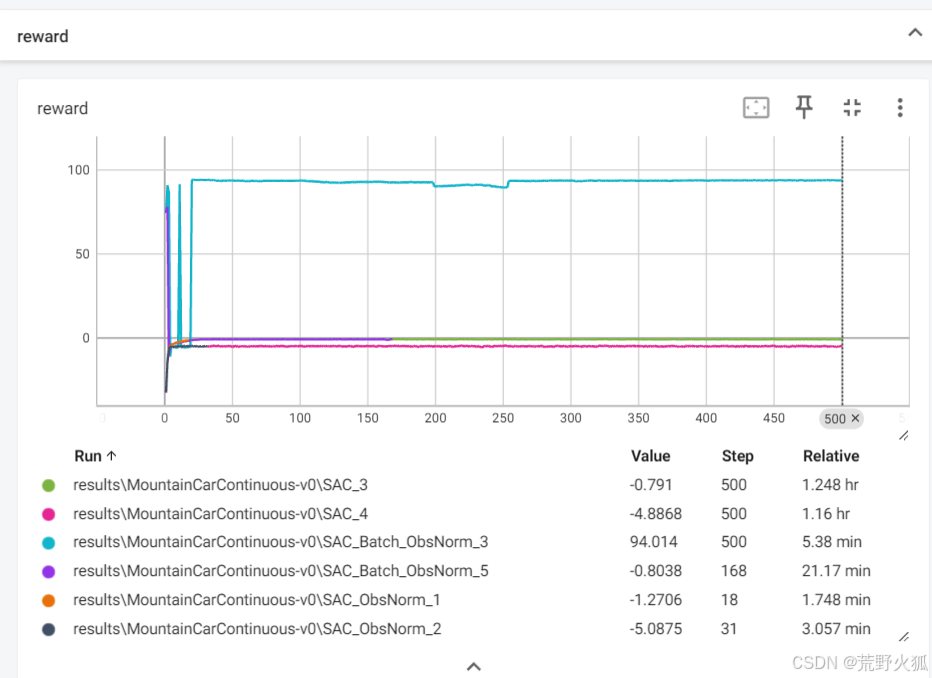
按理来说,使用adaptive_alpha 也能比较好收敛才对(论文里提到,使得超参数的影响减小),但是上述情况出现相反的情况,可能是因为在不同环境下,效果不同,在论文中出现的实验中也有fixed alpha 比 adaptive_alpha 的情况 (如sac论文中的Figure 1)
转折
然后我以为使用了Batch_ObsNorm 就会使得在其他种子下也能实现收敛时,我错了,在seed=10,100时均未能收敛,后查找原因:https://github.com/rail-berkeley/softlearning/issues/76,在此看到了解答,此外我在sb3的SAC上也看到此技巧,就是在探索过程中加入OUNoise后,稳定收敛了。
此是加入OUNoise并衰减,不使用Norm,绿色:fixed alpha 黄色:adaptive alpha
此时黄色要好一点,选取adaptive alpha,为后续最优比较对象。
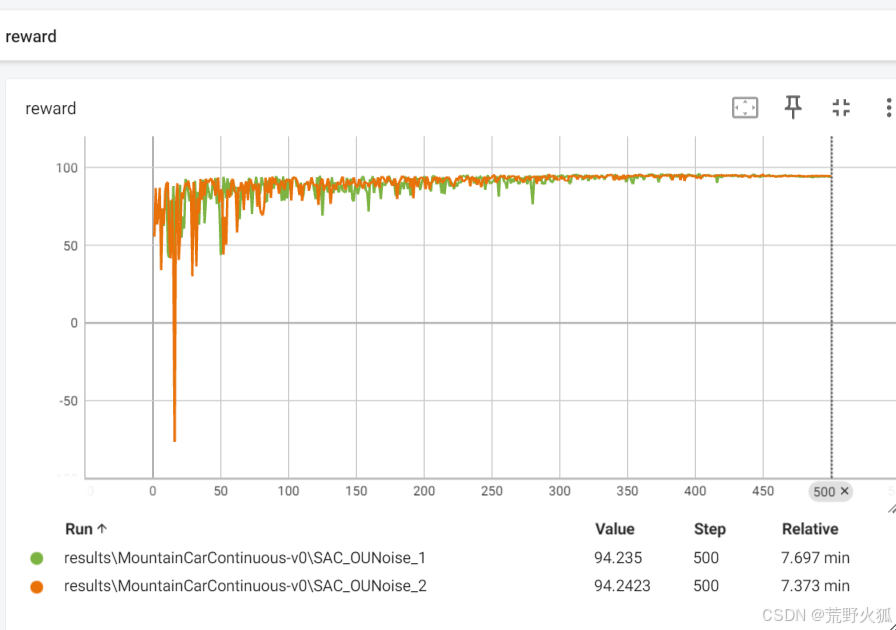
由于TD3算法中说,高斯噪声也能取得比较好的结果,我又对高斯噪声进行了三组seed测试:
seed = 100,10,0
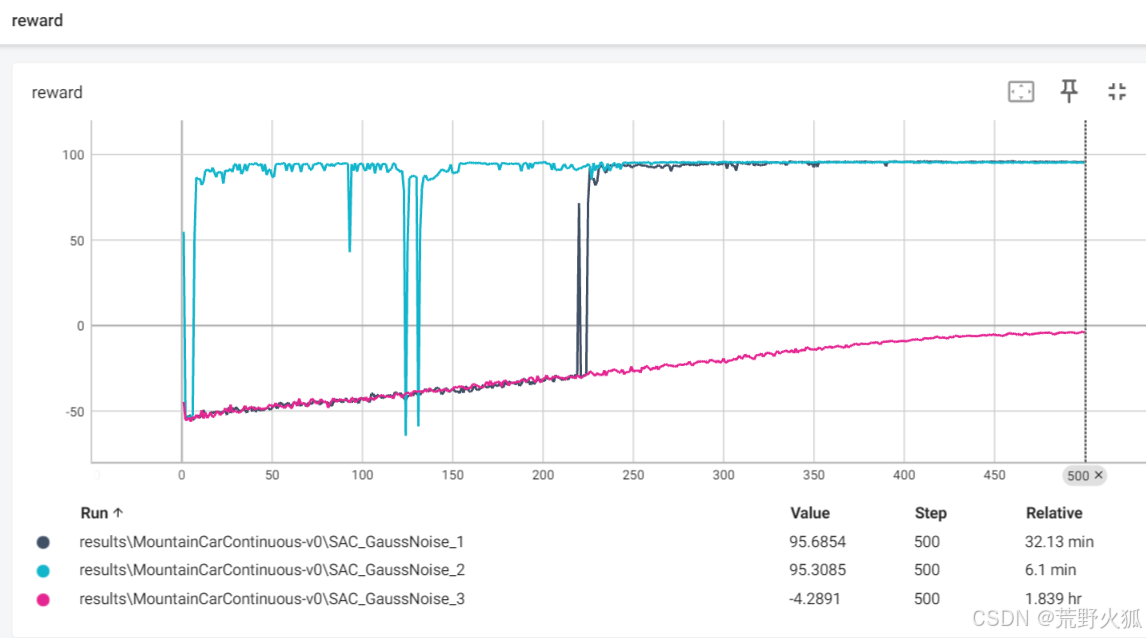
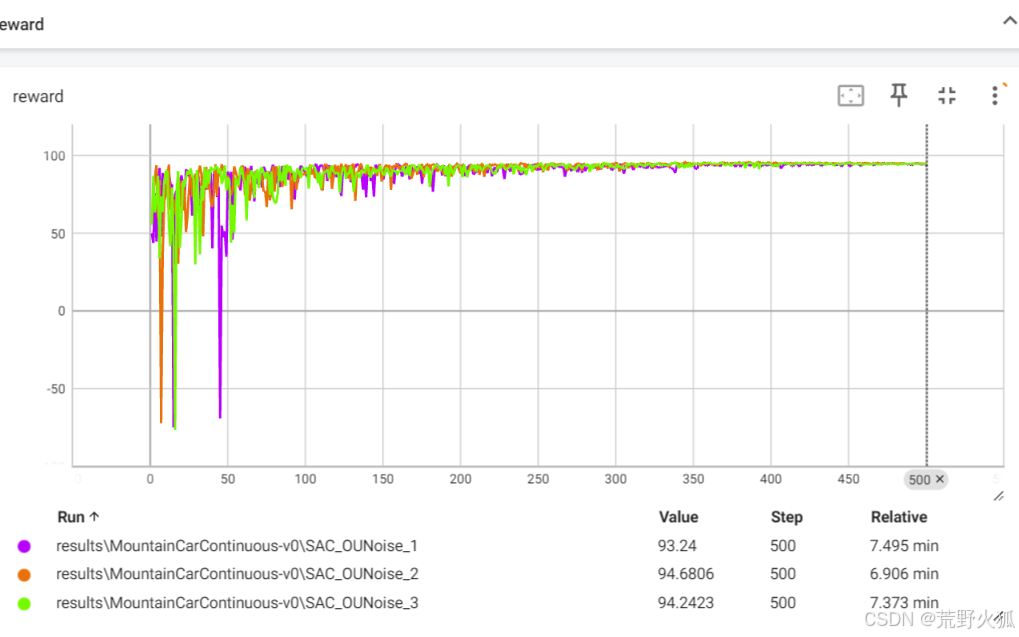
而OUNoise的三组测试如下:
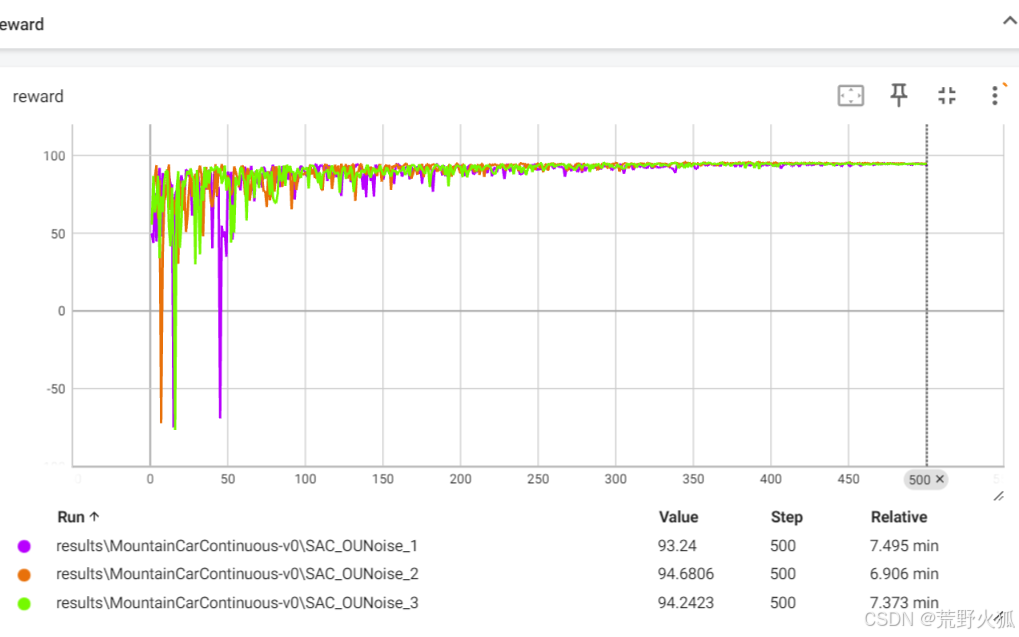
确实比高斯噪声稳定,从这也可以看出OUNoise确实是有效果的。
DDPG、PPO、TD3、SAC算法比较
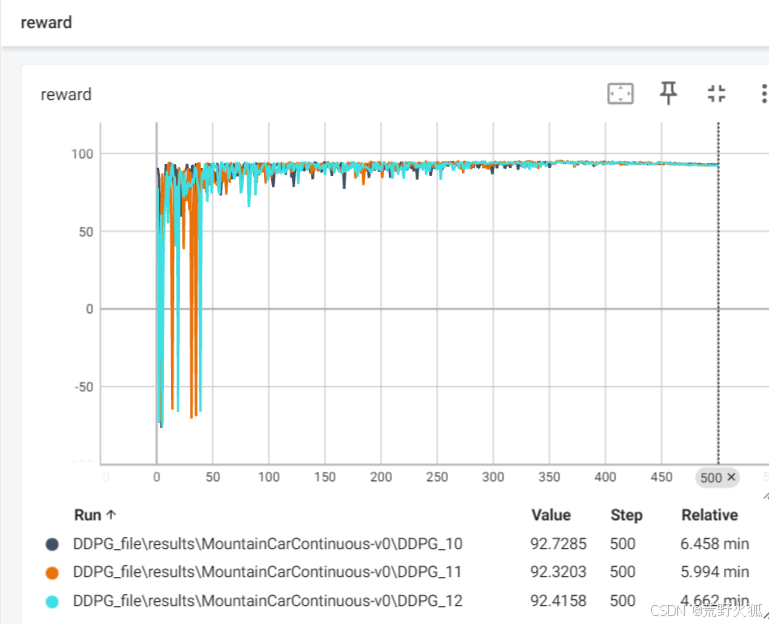
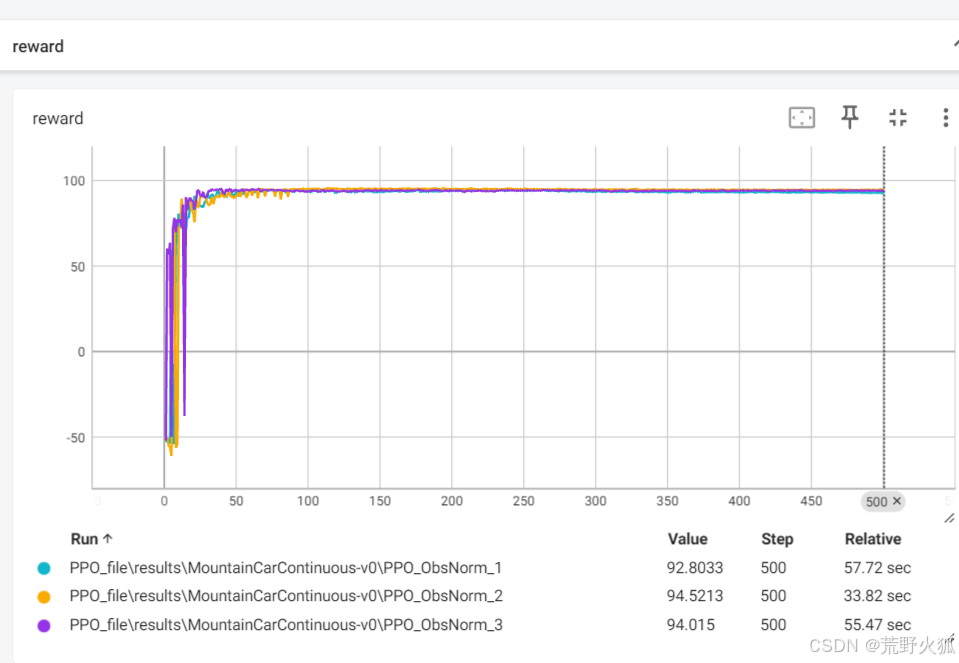
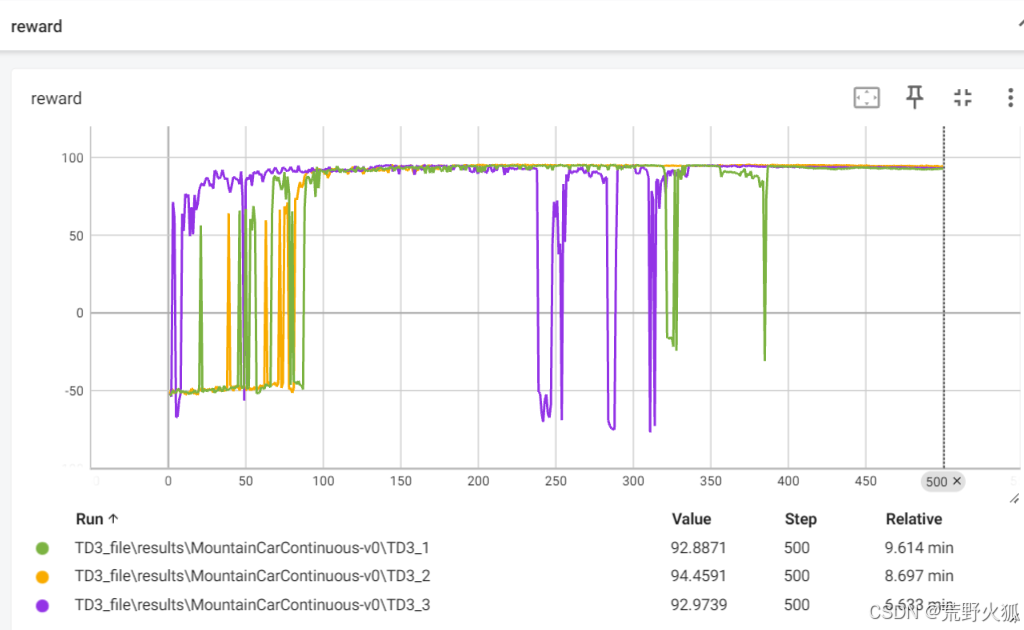
如果共有参数一致,且特有参数均按其特有参数调节到最好值时:seed = 0 10 100
效果如下:
PPO用时最短:由于是online算法,更新次数少,收敛到的效果也很好
TD3用时最多:由于算法的复杂最高,效果也一般,可能参数没调到最优还。
DDPG反而是收敛较快的(相对步数下,不加算法没提及的trick),由于探索较大。
SAC相对比较折中,比DDPG稍慢,但能收敛到比较好的值。
DDPG:
PPO:
加入ObsNorm才收敛
TD3:
SAC:
加入了OUNoise

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









