







1 什么是 Beats
https://www.elastic.co/cn/beats/
Elastic(5.0版本之后)后面又引入了 Beats 家族。这是一系列非常轻量级的数据收集端
-
Packetbeat: 可以实时监听网卡流量,并实时解析网络协议数据,可用来做 NPM 网络数据分析。
-
Metricbeat: 可以用来收集服务器,以及服务器上部署的应用服务的各项监控指标数据(系统、进程和文件系统级别的CPU和内存使用情况等数据),这样就可以替代 Zabbix 等传统的监控软件,来做服务器的性能指标分析。
-
Filebeat: 用于日志文件的收集等
-
Winlogbeat: 用于 Windows 平台的事件日志收集
-
Auditbeat:可以实时收集服务器的行为事件,用于安全方面的入侵检测和安全日志审计分析。
-
Heartbeat:可用性监控
-
Functionbeat:云数据(Elastic Cloud on AWS and GCP)
-
Journalbeat:系统日志
2 日志的重要性
-
为什么重要
-
运维:医生给病人看病。日志就是病人对自己的陈述
-
恶意攻击,恶意注册,刷单,恶意密码猜测
-
-
挑战
-
关注点很多,任意一个节点都有可能引起问题
-
日志分散在很多机器,出了问题时,才发现日志被删了
-
很多运维人员是消防员,哪里有问题去哪里
-
-
集中化日志管理
- 日志收集 - 格式化分析 - 检索与可视化 - 风险警告
3 什么是Filebeat
Filebeat是一个开源的文本日志收集器,它是 elastic 公司 Beats 数据采集产品的一个子产品,采用 Go 语言开发,一般安装在业务服务器上作为代理来监测日志目录或特定的日志文件,并把它们发送到 Logstash、Elasticsearch、Redis 或 Kafka 等。
读取日志文件,Filebeat 不做数据的解析,加工处理
-
日志是非结构化数据
-
需要进行处理后,以结构化的方式保存到 Elasticsearch
保证数据至少被读取一次
处理多行数据,解析 JSON 格式,简单的过滤
# Filebeat 参考
https://www.elastic.co/guide/en/beats/filebeat/current/index.html
4 Filebeat架构与运行原理
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
Filebeat是一个轻量级的日志监测、传输工具,它最大的特点是性能稳定、配置简单、占用系统资源很少
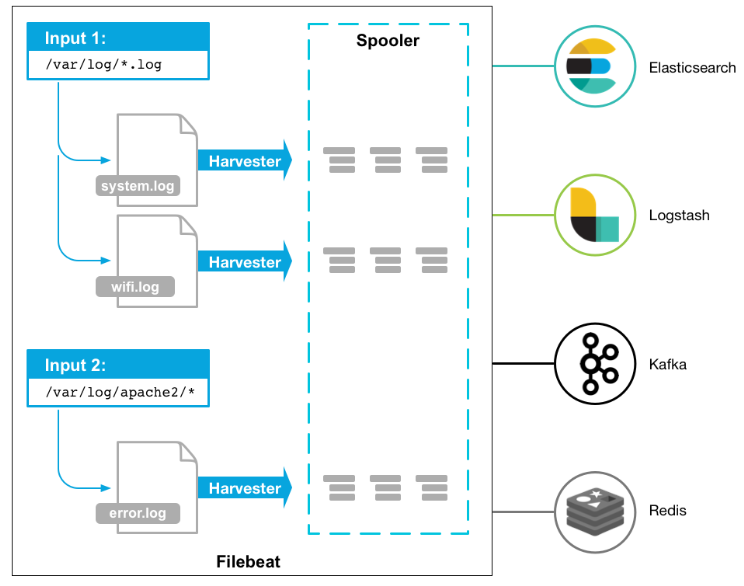
Filebeat 由两个主要组件组成:Prospectors(探测器)和 Harvesters(收集器)。这两个组件协同工作将文件变动发送到指定的输出中。
Filebeat 执行流程
-
定义数据采集:Prospector 配置。通过 filebeat.yml
-
建立数据模型:Index Template
-
建立处理处理流程:Ingest Pipeline
-
存储并提供可视化分析:ES + Kibana Dashboard
4.1 Harvester(收割机)
负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到指定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。
所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。
例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
4.2 Prospector(勘测者)
负责管理Harvester并找到所有读取源
filebeat.prospectors:
- input_type: log
paths:
- /apps/logs/*/info.log
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
综上所述,filebeat的工作流程为:当开启filebeat程序的时候,它会启动一个或多个探测器(prospector)去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat会启动收集进程(harvester),每一个收集进程读取一个日志文件的内容,然后将这些日志数据发送到后台处理程序(spooler),后台处理程序会集合这些事件,最后发送集合的数据到output指定的目的地。
4.3 Filebeat如何记录文件状态
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。
每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
4.4 Filebeat如何保证事件至少被输出一次
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。
若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置 shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
5 用 ELK 来做日志管理
# 安装 filebeat
tar -zxvf /search/software/filebeat-7.1.0-linux-x86_64.tar.gz -C /usr/local
mv /usr/local/filebeat-7.1.0-linux-x86_64 /usr/local/filebeat
./filebeat modules list # 查看 filebeat 提供的 modules
./filebeat modules enable system # 启用系统日志 system
./filebeat modules enable nginx # 启用系统日志 nginx
./filebeat modules enable elasticsearch # 启用 elasticsearch
./filebeat modules list # 再次查看
# 进 modules.d 编辑相应的文件,修改 log 路径
vim modules.d/nginx.yml
# 在 kibana 里面帮你设置好 filebeats 相关的 dashboard
./filebeat setup --dashboards
./filebeat export template | more
./filebeat -e

















 2595
2595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









