







在搭建好hive后,我们接下来看看hive的使用。
一、连接hive,查看现有多少个数据库;
show databasese;
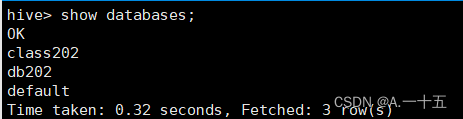
以上可以看出我有3个数据库;
二、创建数据库;数据库会以文件夹.db的形式存在hdfs里;
create database tb202;
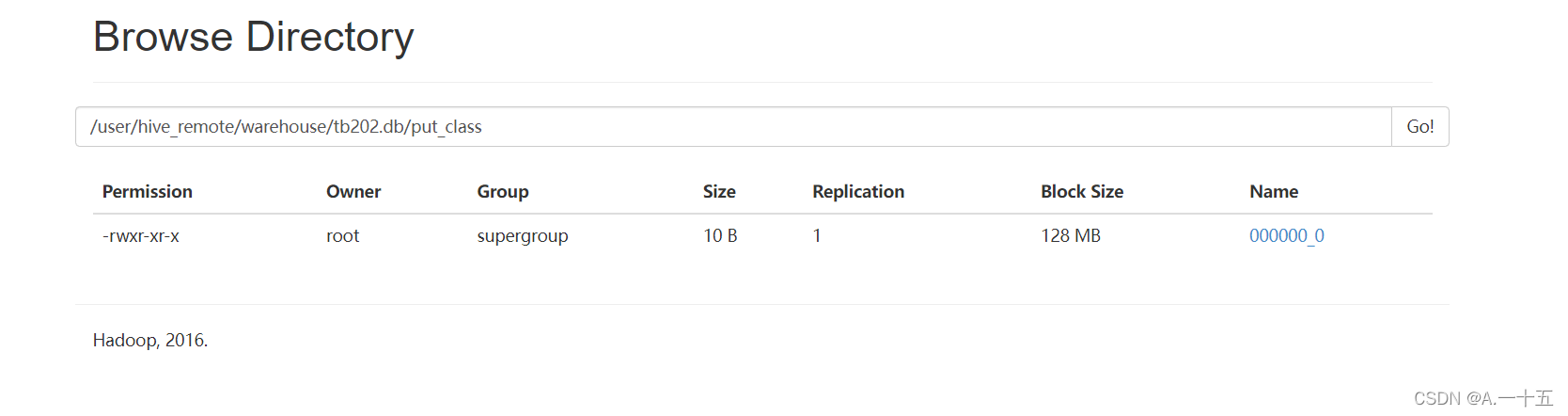
三、创建表;表会文件夹的形式存在;
前提是要先使用你创建的数据库。
create table put_class(id string,amount float);

四、在表里插入数据,可以看见会自动运行mapreduce。
insert into put_class values("cup","200");

五、查看表的内容;
在这里可以看出我们刚刚插入的数据已经创建ok了,hdfs上也有了数据;但是这个数据中间有一个符号所以我们把他换成","号创建表。
select * from put_class;


接下来创建一个没有这个符号的表命令如下

创建完成后在插入数据运行一下;
![]()
接下来我们上hdfs上看下文件;

六、我们也可以使用写好文件插入数据,创建好文件利用hadoop命令上传到
G_class文件里面,可以看到我吧bak放在了G_class文件里。

七、我们使用命令查看这个文件里的数据。
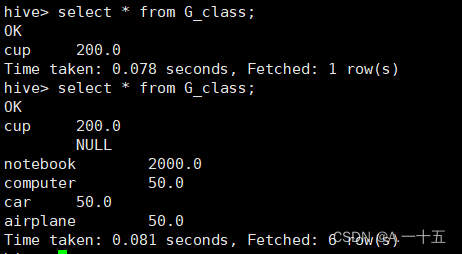
可以看到多出了5组数据。
八、 查询计数命令产生mapreduce命令;
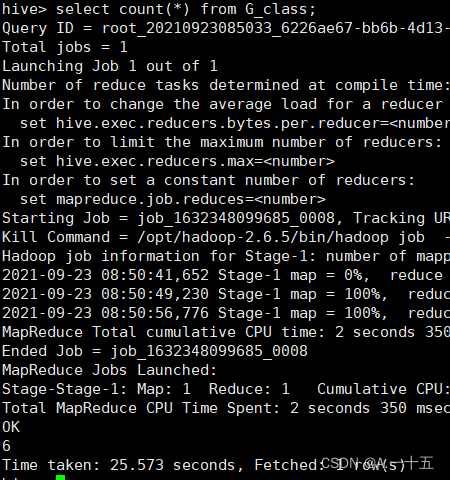
与第七条那个命令不同的就是这次只出现了数据的数量;
今天的任务就是这些,小编持续更新中..........


















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











