







 本文介绍了如何使用Python构建一个多线程爬虫,从彼岸桌面网站抓取指定页数的图片链接,并将图片下载到本地。通过分析页面URL规律,构建页面链接列表,使用BeautifulSoup解析HTML获取图片链接,最后利用多线程的生产者-消费者模型提高图片下载效率。
本文介绍了如何使用Python构建一个多线程爬虫,从彼岸桌面网站抓取指定页数的图片链接,并将图片下载到本地。通过分析页面URL规律,构建页面链接列表,使用BeautifulSoup解析HTML获取图片链接,最后利用多线程的生产者-消费者模型提高图片下载效率。
Python爬虫抓取图片到本地
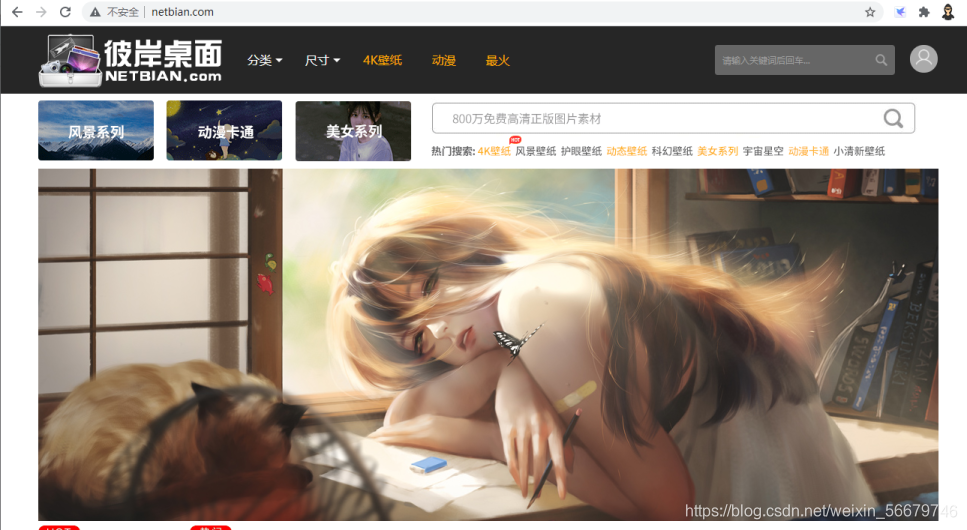
一:目标站点信息
彼岸桌面 网址为:http://www.netbian.com/
二:目标站点分析
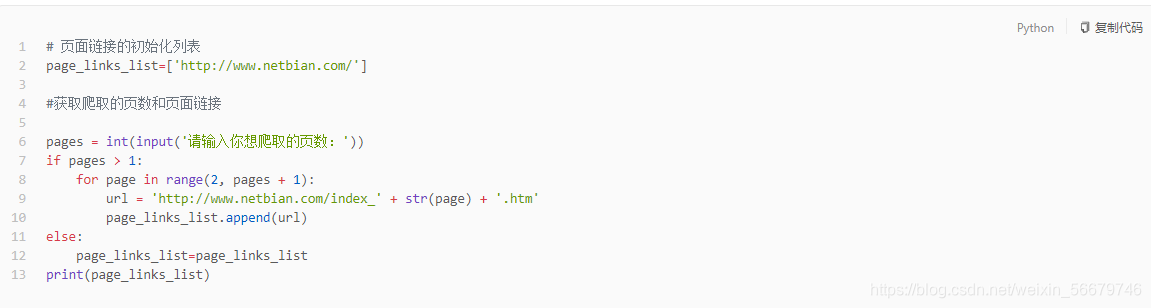
(1):构造页面的URL列表
我们需要做的是爬取网站上给定页数的图片,所以,我们首先需要的就是观察各个页面链接之间的关系,进而构造出需要爬取页面的url列表。

可以看出,从第二页开始之后的页面链接只是后面的数字不同,我们可以写个简单的代码,获取页面的url列表

(2):获取一个页面中所有的图片的链接
我们已经获取了所有页面的链接,但是没有获取每张图片的链接,所以,接下来我们需要做的就是获取一个页面中的所有图片的链接。在这里,我们以第一页为例,获取每张图片的链接,其他页面类似。
首先在页面中右键->查看元素,然后点击查看器左边的那个小光标ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









