



下载Llama需要两步走
- 申请参数
- 下载模型
申请参数
首先我在github上找到llama项目,链接:Llama3
权限申请我推荐使用huggingface。这是因为用meta llama官网申请的时候,我把信息都填好了,结果按accept and continue它没动静。但huggingface申请参数就很顺利。
我们在huggingface上找到了meta-llama项目,找到我们要下载的模型:比如Llama-3.2-1B
我们需要注册才能下载模型:
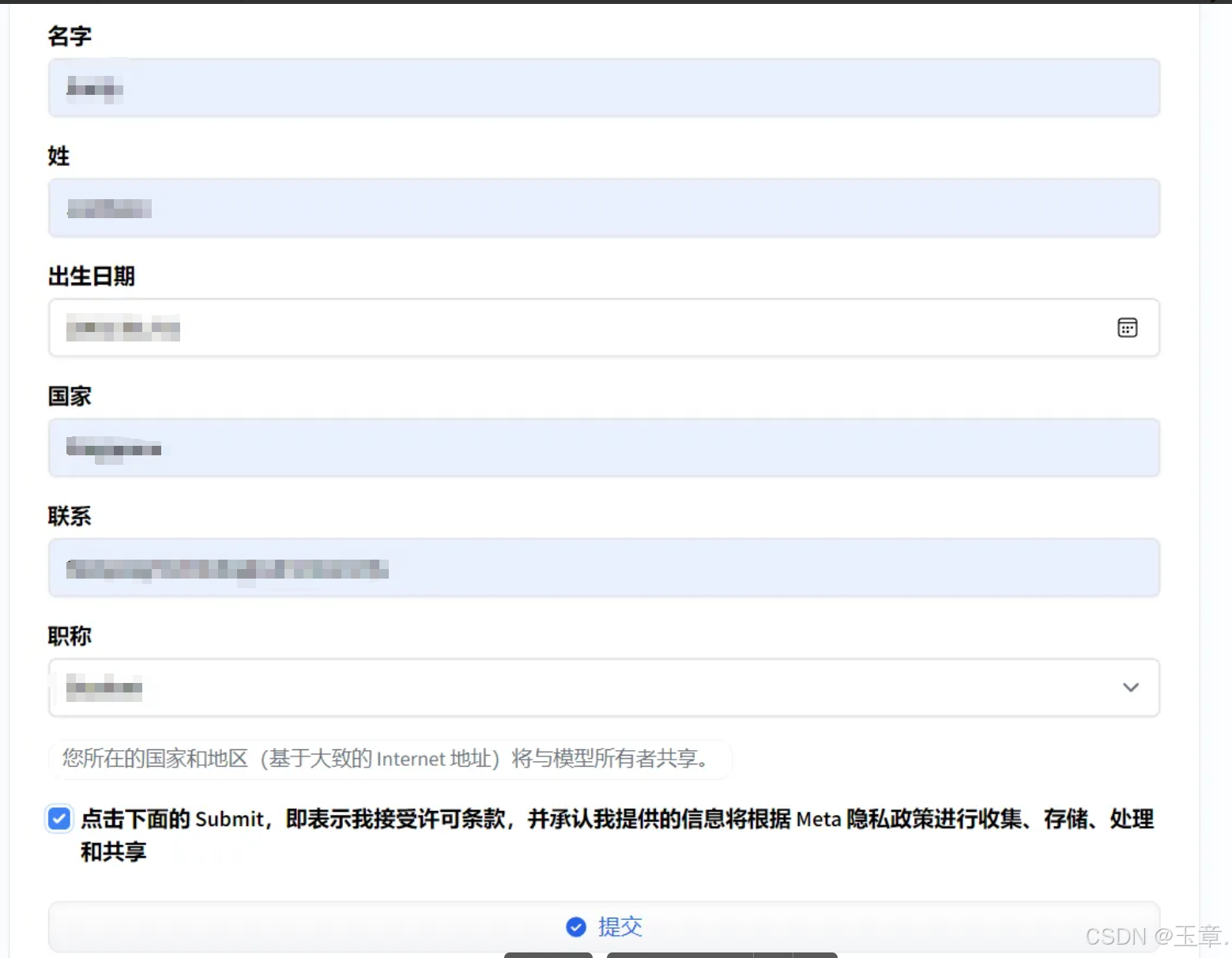
注册完了以后填信息,注意这里有个坑。这个table填China是批准不了的,可以天别的国家(学校等可以填别的国家的学校),邮箱我用的是个人邮箱。
填完了以后它审批好会发邮件给你(huggingface注册用的邮箱)这个时候你就能下载了。
下载模型
-
huggingface access token
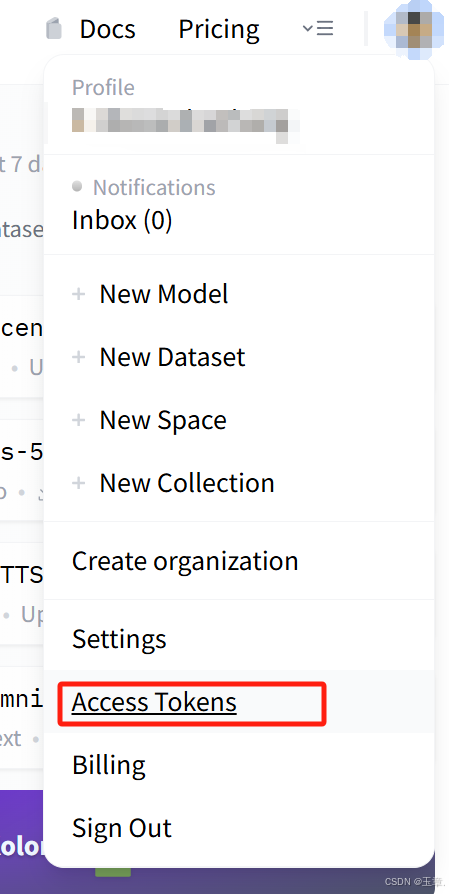
创建token,token是write类别,然后把api key复制下来 -
设置镜像源 (可以将它写入~/.bashrc)
# 这个是设置镜像源的环境变量,建议将上面这一行写入 ~/.bashrc。若没有写入,则每次下载时都需要先输入该命令
export HF_ENDPOINT=https://hf-mirror.com
- linux登录huggingface:
这里我用的是huggingface-hub==0.23.4
如果没有install的可以pip install 一下
huggingface-cli login
之后输入你的api key,你就成功登录了
- 用命令行进行下载
huggingface-cli download --resume-download meta-llama/Llama-3.2-1B --local-dir meta-llama/Llama-3.2-1B
# local dir代表本地存储的位置
参考链接:
api key的获取
huggingface login 的方式
国内镜像源使用方法
huggingface申请方法借鉴


















 6637
6637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









