







k近邻模型(KNN)
k近邻法定义:
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。
如下图为k=5时,Xu的预测过程:选取最近的5个点,取其中数量最多的w1。

距离度量定义:

其中p=1时,称为曼哈顿距离;p=2时,称为欧式距离。
下图给出了二维空间中p取值不同时,与远点Lp距离为1(Lp=1)的点的图像。
k值的选择
k值的选择会对k近邻法的结果产生重大影响。
较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差会减小,只有与输入实例较近的训练实例,才会对预测结果起作用。但缺点是“学习”的估计误差会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合。
较大的k值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远,的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整,体的模型变得简单。
在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。
k近邻法的实现:kd树
构造kd树
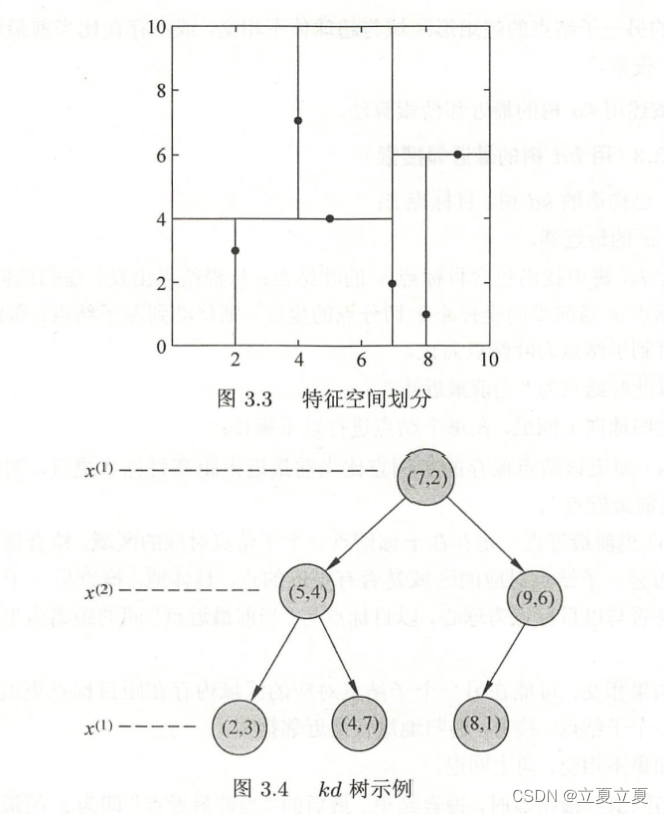
kd树(k-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。

构造kd树的流程如下图。

图3.4 为具体划分案例
搜索kd树

图3.5 为通过kd树搜索最近邻的案例。

KNN算法小结
KNN算法是很基本的机器学习算法了,它非常容易学习,在维度很高的时候也有很好的分类效率,因此运用也很广泛,这里总结下KNN的优缺点。
KNN的主要优点有:
1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归
2) 可用于非线性分类
3) 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
4) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
5) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
KNN的主要缺点有:
1)计算量大,尤其是特征数非常多的时候
2)样本不平衡的时候,对稀有类别的预测准确率低
3)KD树,球树之类的模型建立需要大量的内存
4)使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
5)相比决策树模型,KNN模型可解释性不强
以上就是KNN算法原理的一个总结,希望可以帮到朋友们,尤其是在用scikit-learn学习KNN的朋友们。
参考:
[1]李航.统计学习方法[M].北京:清华大学出版社,2012年3月.
[2]刘建平博客:K近邻法(KNN)原理小结


















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











