






大一学的mysql已经忘得一干二净了,由于使用需要,从头整理学习所得,看的B站课程BV1Kr4y1i7ru
目录
1.简介
1)SQL语法:
- 大小写不敏感:SQL关键字(如
SELECT)通常不区分大小写,但表名和列名可能受数据库配置影响。一般建议使用大写- 分号结尾:多数数据库要求以分号
;结束语句。- 注释:使用
--(单行注释)或/* */(多行注释)。- 启动:mysql -u root -p,启动后用可视化界面才能显示连接
2)SQL分类:
分类 功能 主要命令 DQL 数据查询 SELECTDML 数据增删改 INSERT,UPDATE,DELETEDDL 定义或修改结构 CREATE,ALTER,DROPDCL 权限控制 GRANT,REVOKETCL 事务管理 COMMIT,ROLLBACK
2.具体语法实现
DDL:(表的定义和结构修改)
数据库的基本操作
CREATE DATABASE :创建
DROP DATABASE:删除
USE:使用某个数据库
SELECT DATABASE();查看当前使用的数据库
create database test charset utf8mb4
#CHARACTER SET 和 CHARSET 是等价的
#MySQL 允许使用 CHARACTER SET 或 CHARSET 指定字符集,两者无区别。
CREATE DATABASE IF NOT EXISTS mydb;
#当不存在指定数据库时才去创建
DROP DATABASE IF EXISTS mydb;
USE test
表的基本操作:
①表的查询
SHOW TABLES:查询当前数据库当中的所有表
DESC +表名:查询表结构
SHOW CREATE TABLE 表名:查询指定表的建表语句
②表的创建

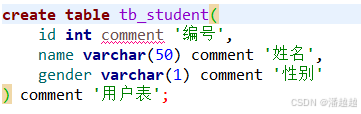
数据类型:
存储无符号数时,需要多加一个unsigned在数据类型后面指明
类型名称 存储大小 无符号范围(unsigned) 用途说明 TINYINT 1 字节 0 ~ 255 小整数(如年龄、状态码) SMALLINT 2 字节 0 ~ 65,535 中等整数 MEDIUMINT 3 字节 0 ~ 16,777,215 较大整数(如城市人口) INT 4 字节 0 ~ 4,294,967,295 常用大整数(如订单ID、用户ID) BIGINT 8 字节 0 ~ 18,446,744,073,709,551,615 极大整数(如天文数据) FLOAT 4 字节(单精度) 无符号范围不适用 小范围浮点数(近似值,科学计算) DOUBLE 8 字节(双精度) 无符号范围不适用 大范围浮点数(高精度近似值) **DECIMAL(M,D)** 变长(每4字节存9位数字) 无符号范围不适用 精确小数(如金额、科学测量值)
字符类型:
CHAR(M) 255字符 M×字符字节数 定长 依赖校对规则 定长字符串,如国家代码 VARCHAR(M) 最多65535字节 实际长度 +1或2字节 变长 依赖校对规则 变长字符串,如用户名 TINYTEXT 255字节 长度 +1字节 变长 依赖校对规则 短文本 TEXT 65,535字节 长度 +2字节 变长 依赖校对规则 文章内容
char的性能高于varchar,变长是指随着内容的变化,长度发生变化,需要额外计算存储内容的长度,因此性能较差,而char是定长的,不会发生变化。
日期类型:
类型 存储空间 范围 格式 是否包含时区 自动更新功能 适用场景 DATE 3字节 '1000-01-01' 到 '9999-12-31' 'YYYY-MM-DD' 否 无 存储日期(如生日、订单日期) TIME 3字节 '-838:59:59' 到 '838:59:59' 'HH:MM:SS' 否 无 存储时间(如任务耗时、事件持续时间) DATETIME 5-8字节 '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' 'YYYY-MM-DD HH:MM:SS' 否 无(需手动设置) 固定日期和时间(如会议时间、预约时间)
③ 表的修改
操作类型 语法 说明 示例 重命名字段 ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [约束]修改字段名称和/或数据类型,必须同时指定新数据类型。 ALTER TABLE user CHANGE username name VARCHAR(100) NOT NULL;修改字段数据类型 ALTER TABLE 表名 MODIFY 字段名 新数据类型 [约束]仅修改字段数据类型或约束,不改变名称。 ALTER TABLE user MODIFY age SMALLINT UNSIGNED DEFAULT 18;删除字段 ALTER TABLE 表名 DROP 字段名删除表中指定字段。 ALTER TABLE user DROP phone;修改表名 ALTER TABLE 表名 rename to 新表名修改表的名字 ALTER TABLE user Rename to student;删除表 DROP TABLE [IF EXISTS] 表名 删除表,不想报错可以加上if exists DROP TABLE IF EXISTS student 添加新字段 ALTER TABLE 表名 ADD 字段名 字段类型添加新的字段 ALTER TABLE user ADD id char(10)修改字段注释 ALTER TABLE 表名 MODIFY 字段名 数据类型 COMMENT '新注释' [约束]更新字段的注释内容。
ALTER TABLE user MODIFY id INT COMMENT '用户唯一标识';
DML:增删改
INSERT (插入操作)
写法 语法示例 说明 省略列名 INSERT INTO 表名 VALUES (值1, 值2, ...);必须按表中所有列的顺序提供值,且值的数量与列数量一致。 指定列名 INSERT INTO 表名 (列1, 列2, ...) VALUES (值1, 值2, ...);仅需为指定列提供值,其他列可以是默认值或 NULL(需允许为空)。
写法 语法示例 说明 省略列名添加多项 INSERT INTO 表名 VALUES (值1, 值2, ...),(值1, 值2, ...);必须按表中所有列的顺序提供值,且值的数量与列数量一致,多个数据直接用逗号隔开即可
UPDATE
UPDATE更新的是列,当想要删除某列数据时,将全部信息置为NULL即可
其中WHERE 条件可以省略不写, 如果省略不写默认对全表进行更新
| 方法名称 | 描述 | 语法示例 | 示例 |
|---|---|---|---|
| UPDATE | 更新表中符合条件的数据。 | UPDATE 表名 SET 列1=新值1, 列2=新值2 [WHERE 条件]; | UPDATE users SET age = 26, status = 'active' WHERE name = 'Alice'; |
DELETE
把匹配条件的那一行直接给删除掉,如果没有指定条件,整个表数据全部删除。
| 方法名称 | 描述 | 语法示例 | 示例 |
|---|---|---|---|
| DELETE | 删除表中符合条件的数据。 | DELETE FROM 表名 [WHERE 条件]; | DELETE FROM users WHERE id = 1;(删除id=1的记录) |
DQL:表的查询
数据的查询
| 语法结构 | 描述 | 语法示例 | 示例 |
|---|---|---|---|
| 基础查询 | 查询表中的数据。 | SELECT 列1, 列2 FROM 表名; | SELECT name, age FROM users; |
| 条件过滤 | 按条件筛选数据。 | SELECT 列 FROM 表名 WHERE 条件; | SELECT * FROM users WHERE age > 18 AND status = 'active'; |
| 排序 | 按指定列排序结果。 | SELECT 列 FROM 表名 ORDER BY 列 [ASC/DESC]; | SELECT name, age FROM users ORDER BY age DESC;(按年龄降序) |
| 分组聚合 | 对数据进行分组并应用聚合函数(如COUNT、SUM等)。 | SELECT 列, 聚合函数() FROM 表名 GROUP BY 列; | SELECT department, COUNT(*) FROM employees GROUP BY department; |
| 分组后过滤 | 对分组后的结果进行条件过滤(需与GROUP BY一起使用)。 | SELECT 列 FROM 表名 GROUP BY 列 HAVING 条件; | SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 5000; |
| 连接查询 | 关联多张表查询数据。 | SELECT 列 FROM 表1 JOIN 表2 ON 表1.列 = 表2.列; | SELECT users.name, orders.amount FROM users JOIN orders ON users.id = orders.user_id; |
| 子查询 | 在查询中嵌套另一个查询。 | SELECT 列 FROM 表名 WHERE 列 IN (SELECT 列 FROM 表名); | SELECT name FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount > 100); |
| 组合查询 | 合并多个查询结果(需列数量和类型一致)。 | SELECT 列 FROM 表1 UNION [ALL] SELECT 列 FROM 表2; | SELECT name FROM users UNION SELECT name FROM admins;(去重)UNION ALL(保留重复) |
| 分页查询 | 限制返回的行数及偏移量。 | SELECT 列 FROM 表名 LIMIT 行数 OFFSET 偏移量; | SELECT * FROM users LIMIT 10 OFFSET 20;(跳过前20行,取10行) |
| 窗口函数 | 对结果集进行窗口计算(如排名、累计和等)。 | SELECT 列, 窗口函数() OVER (PARTITION BY 列 ORDER BY 列) FROM 表名; | SELECT name, salary, RANK() OVER (ORDER BY salary DESC) FROM employees;(按工资排名) |
小细节:
1.查询时给列或表起别名,AS关键字可以不写,直接写别名
| 别名类型 | 语法 | 描述 |
|---|---|---|
| 列别名 | SELECT 列名 AS 别名 FROM 表名; | 为查询结果的列指定一个临时名称(可读性更强)。 |
| 表别名 | SELECT 列 FROM 表名 AS 别名; | 为表指定一个临时名称(常用于简化多表查询或子查询)。 |
2. 查询时去重
| 场景 | 示例 | 说明 |
|---|---|---|
| 单列去重 | SELECT DISTINCT city FROM users; | 返回唯一的城市列表。 |
| 多列组合去重 | SELECT DISTINCT name, age FROM students; | 返回name和age组合不同的记录。 |
3.WHERE后的条件列表
| 条件类型 | 操作符/语法 | 描述 | 示例 |
|---|---|---|---|
| 比较运算 | =, <>/!=, >, <, >=, <= | 基础数值或字符比较。 | SELECT * FROM users WHERE age > 18; |
| 逻辑组合 | AND, OR, NOT | 组合多个条件。 | SELECT * FROM products WHERE price < 100 AND stock > 0; |
| 范围匹配 | BETWEEN ... AND ... | 判断值是否在某个区间内(闭区间)。 | SELECT * FROM orders WHERE amount BETWEEN 50 AND 200; |
| 集合匹配 | IN (值1, 值2, ...) | 判断值是否在指定集合中。 | SELECT * FROM users WHERE city IN ('Beijing', 'Shanghai'); |
| 模糊匹配 | LIKE | 使用通配符%(任意字符)和_(单个字符)匹配文本。 | SELECT * FROM books WHERE title LIKE '__';//表示匹配书名为两个字的行 |
| 空值判断 | IS NULL, IS NOT NULL | 判断列是否为NULL。 | SELECT * FROM employees WHERE email IS NULL; |
| 子查询条件 | EXISTS, ANY/SOME, ALL | 结合子查询进行条件过滤。 | SELECT * FROM users WHERE EXISTS (SELECT 1 FROM orders WHERE user_id = users.id); |
| 正则表达式 | REGEXP | 使用正则表达式匹配文本(MySQL支持)。 | SELECT * FROM users WHERE name REGEXP '^A[a-z]+'; |
| JSON数据查询 | ->, ->> | 查询JSON类型字段中的值(MySQL 5.7+)。 | SELECT * FROM products WHERE info->'$.price' > 100; |
4.聚合函数:
| 函数 | 语法 | 描述 | 示例 |
|---|---|---|---|
| COUNT() | COUNT(列名或*) | 统计行数(*统计所有行,包括NULL;列名忽略NULL)。 | SELECT COUNT(*) FROM users;(总用户数) |
| SUM() | SUM(数值列) | 计算数值列的总和(忽略NULL)。 | SELECT SUM(sales) FROM orders;(总销售额) |
| AVG() | AVG(数值列) | 计算数值列的平均值(忽略NULL)。 | SELECT AVG(score) FROM exams;(平均分) |
| MAX() | MAX(列) | 返回列中的最大值(适用于数值、日期、字符)。 | SELECT MAX(price) FROM products;(最高价格) |
| MIN() | MIN(列) | 返回列中的最小值(适用于数值、日期、字符)。 | SELECT MIN(create_time) FROM logs;(最早记录时间) |
| GROUP_CONCAT() | GROUP_CONCAT(列 [SEPARATOR 分隔符]) | 将多行值合并为一个字符串(默认逗号分隔)。 | SELECT GROUP_CONCAT(name SEPARATOR '; ') FROM students;(合并姓名) |
5.GROUP BY的细节(分组查询)
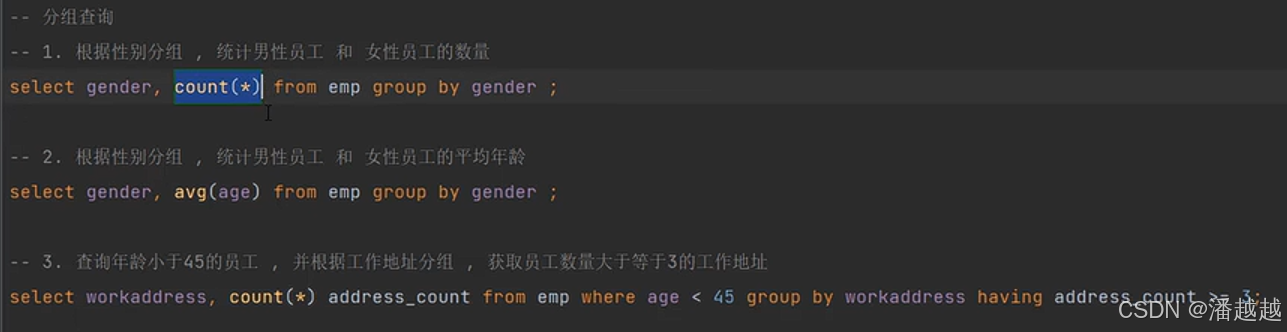
| 特性 | WHERE | HAVING |
|---|---|---|
| 作用阶段 | 在分组前过滤行(行级过滤)。 | 在分组后过滤组(组级过滤)。 |
| 适用对象 | 直接操作表中的原始列。 | 操作分组后的聚合结果或分组列。 |
| 能否使用聚合函数 | 不能直接使用聚合函数(需结合子查询)。 | 可以直接使用聚合函数(如SUM, AVG)。 |
| 执行顺序 | 先于GROUP BY和HAVING执行。 | 在GROUP BY之后执行。 |
| 性能影响 | 高效(先过滤掉无关行,减少分组计算量)。 | 相对较低(需先分组再过滤)。 |
6.ORDER BY的使用(排序查询)
| 分类 | 使用技巧 | 示例/说明 |
|---|---|---|
| 排序方向 | 1. 默认升序(ASC),降序需显式指定 DESC。2. 可对不同字段分别指定排序方向。 | ORDER BY age DESC, name ASC(优先按年龄降序,年龄相同按名字升序) |
| 多字段排序 | 按字段优先级排序:先按第一个字段排序,相同值再按第二个字段排序,依此类推。 | ORDER BY department, salary DESC(先按部门升序,部门相同按薪资降序) |
| 表达式排序 | 支持对字段进行运算或函数处理后排序(如计算字段、字符串处理等)。 | ORDER BY salary * 12 DESC(按年薪降序) ORDER BY SUBSTRING(name, 1, 3)(按名字前3字符排序) |
| 别名排序 | 若 SELECT 中为字段或表达式指定了别名,可直接用别名排序。 | SELECT salary * 12 AS annual_salary ... ORDER BY annual_salary |
7.LIMIT的使用(分页查询)
| 类 | 使用技巧 | 示例/说明 |
|---|---|---|
| 基本语法 | 1. 单参数写法:LIMIT n(返回前n条结果)2. 双参数写法: LIMIT offset, count(从offset行开始,返回count条) | LIMIT 5 → 取前5条LIMIT 10, 5 → 跳过前10条,取第11-15条(注意:偏移量从0开始) |
| 分页公式 | 分页公式:LIMIT (页码-1)*每页数量, 每页数量 | 第3页,每页10条 → LIMIT 20, 10(跳过20条,取10条) |
DQL总结:
| 子句 | 作用说明 | 是否必填 |
|---|---|---|
| SELECT | 指定查询的字段列表 | ✔️ 必填 |
| FROM | 指定查询的数据来源(表/视图) | ✔️ 必填 |
| WHERE | 设置行级过滤条件 | ❌ 可选(按需添加) |
| GROUP BY | 对结果按字段分组 | ❌ 可选(需分组时添加) |
| HAVING | 对分组后的结果进行过滤 | ❌ 可选(需过滤组时添加) |
| ORDER BY | 对结果按字段排序 | ❌ 可选(需排序时添加) |
| LIMIT | 设置分页参数(偏移量,数量) | ❌ 可选(需分页时添加 |
- 执行顺序:
FROM→WHERE→GROUP BY→HAVING→SELECT→ORDER BY→LIMIT(所以,在select当中起的别名只有order by和limit当中可以使用) - WHERE vs HAVING:WHERE 在分组前过滤行,HAVING 在分组后过滤组
- LIMIT分页:常用写法
LIMIT (页码-1)*每页数量, 每页数量
DCL(控制用户访问权限)
不怎么用,知道怎么创建新用户,修改权限,查看权限即可
| 创建用户 | CREATE USER '用户名'@'主机' IDENTIFIED BY '密码'; | 创建新用户并设置密码(主机可指定为%表示任意IP)。 | 新增数据库访问账号(如开发人员、应用服务账号)。 |
| 授予权限 | GRANT 权限 ON 对象 TO '用户'@'主机';例: GRANT SELECT, INSERT ON db1.* TO 'user1'@'localhost'; | 授予用户对指定数据库对象的操作权限(权限可细化到表、列)。 |
| 查看用户权限 | SHOW GRANTS FOR '用户名'@'主机'; | 查看用户的当前权限列表。 |
3.函数的使用
结合DML语句可以实现一系列复杂的数值填入。结合DQL语句,可以实现对原有数据进行更改后的查询结果
字符串函数
| 函数名 | 作用 | 示例 | 返回值 | |
|---|---|---|---|---|
**CONCAT** | 连接多个字符串 | SELECT CONCAT('Hello', ' ', 'World'); | Hello World | |
**SUBSTRING** | 提取子字符串 | SELECT SUBSTRING('SQL Tutorial', 1, 3); | SQL | |
**UPPER** | 转大写 | SELECT UPPER('sql'); | SQL | |
**LOWER** | 转小写 | SELECT LOWER('SQL'); | sql | |
**TRIM** | 去除两端空格或指定字符 | SELECT TRIM(' SQL '); | SQL | |
**REPLACE** | 替换字符串中的子串 | SELECT REPLACE('abc', 'b', 'd'); | adc | |
**LEFT/RIGHT** | 提取左/右侧指定长度字符 | SELECT LEFT('SQL', 2);SELECT RIGHT('SQL', 1); | SQL | |
**INSTR** | 返回子串首次出现的位置 | SELECT INSTR('SQL', 'Q'); | 2 | |
**LPAD/RPAD** | 左/右填充字符串至指定长度 | SELECT LPAD('7', 3, '0'); | 007 | |
**REVERSE** | 反转字符串 | SELECT REVERSE('SQL'); | LQS | |
**FORMAT** | 格式化字符串(如数字、日期) | SELECT FORMAT(1234.567, 2); | 1,234.57 |
字符串函数和UPDATE结合使用可以实现对原有数据进行格式化的更改,比如将某列值set为指定的格式,清除首位空格,控制为指定位数等
UPDATE 表名 SET 列1=字符串函数, 列2=字符串函数 [WHERE 条件];
数值函数:
| 函数名 | 作用 | 示例 | 返回值 | 兼容性说明 |
|---|---|---|---|---|
**ROUND** | 四舍五入到指定小数位 | ROUND(123.4567, 2) | 123.46 | 通用(MySQL、SQL Server、PostgreSQL),注意不同数据库的舍入规则可能略有差异。 |
**CEIL/CEILING** | 向上取整(返回≥原数的最小整数) | CEILING(3.2)CEIL(-2.7) | 4-2 | MySQL: CEILSQL Server: CEILINGPostgreSQL: 两者均支持。 |
**FLOOR** | 向下取整(返回≤原数的最大整数) | FLOOR(3.7)FLOOR(-2.3) | 3-3 | 通用 |
**ABS** | 取绝对值 | ABS(-15) | 15 | 通用 |
**POWER** | 幂运算(x的y次方) | POWER(2, 3) | 8 | 通用 |
**SQRT** | 平方根 | SQRT(25) | 5 | 通用(参数需≥0) |
**MOD** | 取模运算(求余数) | MOD(10, 3) | 1 | MySQL/PG: MODSQL Server: %运算符(如10 % 3) |
**RAND** | 生成0~1之间的随机数 | RAND() | 0.123... | 通用,可指定种子(如RAND(42)) |
**TRUNCATE** | 截断到指定小数位(不四舍五入) | TRUNCATE(123.4567, 2) | 123.45 | MySQL: TRUNCATEPostgreSQL: TRUNCSQL Server: 需用 ROUND配合FLOOR替代 |
日期函数:
| 函数名 | 作用 | 示例 | 返回值示例 | 兼容性说明 |
|---|---|---|---|---|
**CURDATE()/CURRENT_DATE** | 获取当前日期 | SELECT CURDATE(); | 2023-08-23 | MySQL/PG: CURRENT_DATESQL Server: GETDATE()(返回日期+时间) |
**NOW()/CURRENT_TIMESTAMP** | 获取当前日期和时间 | SELECT NOW(); | 2023-08-23 14:30:45 | 通用 |
**DATE_FORMAT** | 格式化日期为字符串 | DATE_FORMAT(NOW(), '%Y-%m') | 2023-08 | MySQL: DATE_FORMAT(date, format)PG: TO_CHAR(date, format)SQL Server: FORMAT |
**DATEDIFF** | 计算两个日期的天数差 | DATEDIFF('2023-08-25', '2023-08-23') | 2 | MySQL/PG/SQL Server均支持,参数顺序可能不同(如SQL Server为DATEDIFF(day, start, end)) |
**DATE_ADD/DATE_SUB** | 日期加减 | DATE_ADD(CURDATE(), INTERVAL 7 DAY) | 2023-08-30 | MySQL/PG: INTERVAL语法SQL Server: DATEADD(day, 7, GETDATE()) |
**EXTRACT** | 提取日期部分(年、月、日等) | EXTRACT(YEAR FROM '2023-08-23') | 2023 | 通用(参数为YEAR/MONTH/DAY/HOUR等) |
使用场景举例:
1.按日期过滤数据:
-- 查询最近7天的订单
SELECT order_id, total_price
FROM orders
WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
AND order_date < CURDATE();2.处理时间间隔:
-- 查询即将过期的会员(有效期剩余3天内)
SELECT user_id, expire_date
FROM members
WHERE DATEDIFF(expire_date, CURDATE()) BETWEEN 0 AND 3;流程函数:
| 函数/语法 | 作用 | 示例 | 返回值示例 | 兼容性说明 |
|---|---|---|---|---|
**CASE WHEN** | 多条件分支判断 |
| 根据分数返回等级 | 通用(所有SQL数据库支持,兼容性最佳) |
**IF** | 简单条件判断(三元运算符) | SELECT IF(score >= 60, '及格', '不及格') FROM exam; | 根据条件返回不同结果 | MySQL特有,其他数据库用CASE WHEN替代 |
**IFNULL** | 判断字段是否为NULL并替换 | SELECT IFNULL(address, '未知') FROM users; | 若address为NULL返回'未知' | MySQL特有,其他数据库用COALESCE替代 |
4.约束:
| 约束类型 | 定义 | 作用 | 语法示例 | 使用场景 | 注意事项 |
|---|---|---|---|---|---|
| 主键约束 | 唯一标识表中的每一条记录 | 确保列值唯一且非空,每个表只能有一个 | CREATE TABLE 表名 (id INT PRIMARY KEY, ...);ALTER TABLE 表名 ADD PRIMARY KEY (列); | 用户ID、订单号等唯一标识字段 | 1. 主键列不允许NULL 2. 支持复合主键(多列组合) |
| 外键约束 | 维护表间的引用完整性 | 确保外键列的值必须在主表对应列中存在 | CREATE TABLE 表1 (<br> user_id INT,<br> FOREIGN KEY (user_id) REFERENCES 表2(id)<br>); | 订单表引用用户表的用户ID | 1. 需使用InnoDB引擎 2. 列的数据类型必须一致 3. 自动创建索引 |
| 唯一约束 | 确保列中的值唯一(允许NULL) | 防止重复值,但允许多个NULL | CREATE TABLE 表名 (email VARCHAR(255) UNIQUE);ALTER TABLE 表名 ADD UNIQUE (列); | 用户邮箱、手机号等需唯一但非必填的字段 | 1. 允许单个NULL值(多个NULL可能因版本而异) 2. 可定义多个唯一约束 |
| 非空约束 | 强制列不允许存储NULL值 | 确保字段必填 | CREATE TABLE 表名 (name VARCHAR(50) NOT NULL); | 用户名、创建时间等必填字段 | 1. 插入时必须提供值 2. 可搭配DEFAULT使用 |
| 默认约束 | 插入未指定值时自动填充默认值 | 简化插入操作,避免遗漏非必填字段 | CREATE TABLE 表名 (status VARCHAR(20) DEFAULT 'pending'); | 订单状态默认"pending"、创建时间默认当前时间 | 1. 默认值需符合数据类型 2. 支持函数如 CURRENT_TIMESTAMP |
| 检查约束 | 限制列值必须满足指定条件 | 确保数据符合业务规则 | CREATE TABLE 表名 (<br> age INT,<br> CHECK (age >= 18)<br>); | 年龄≥18、性别仅限"男"/"女" | 1. MySQL 8.0.16+ 强制支持 2. 早期版本可定义但不生效 |
外键行为类型:
| 行为类型 | 更新时动作 | 删除时动作 | 适用场景 | 注意事项 |
|---|---|---|---|---|
| RESTRICT | 阻止主表更新(若从表存在关联记录) | 阻止主表删除(若从表存在关联记录) | 严格维护关联关系,禁止主表主动变更 | 默认行为;需手动处理关联数据 |
| CASCADE | 主表更新主键值时,自动更新从表外键字段为新的主键值 | 主表删除记录时,自动删除从表关联记录 | 主从表强依赖场景(如日志表) | 数据可能被级联删除,需谨慎使用 |
| SET NULL | 主表更新主键值时,自动将从表外键字段设为NULL | 主表删除记录时,自动将从表外键字段设为NULL | 允许从表记录独立存在(如用户注销后保留订单但解除关联) | 从表外键字段需允许NULL |
| NO ACTION | 与RESTRICT相同,阻止主表更新/删除操作 | 与RESTRICT相同,阻止主表更新/删除操作 | 兼容SQL标准,行为同RESTRICT | MySQL中实际效果等同于RESTRICT |
| SET DEFAULT | 主表更新主键值时,自动将从表外键字段设为默认值 | 主表删除记录时,自动将从表外键字段设为默认值 | 需要外键字段回退到预设值(如部门删除后员工自动归为“未分配”状态) | 1. 从表外键字段需定义默认值 2. MySQL中可能无效(需确认引擎支持) |
在具体设计时,可能并不需要用外键去关联多个表,而是通过假连接的方式,只要从表当中的名称能够表明数据与那个表相互连接即可。
5.多表查询
| 分类 | 子类/类型 | 定义 | 语法示例 | 使用场景 | 注意事项 |
|---|---|---|---|---|---|
| 连接查询 | 内连接 (INNER JOIN) | 返回两表中匹配条件的行(交集) | 显示写法:SELECT * FROM 表1 INNER JOIN 表2 ON 表1.id = 表2.id;或隐式写法: SELECT * FROM 表1, 表2 WHERE 表1.id = 表2.id; | 需要获取两表关联数据的场景(如订单与用户信息关联) | 1. 默认不写INNER时仍为内连接2. 注意避免笛卡尔积(未加条件时) |
| 左外连接 (LEFT JOIN) | 返回左表全部行 + 右表匹配的行(不匹配的右表字段为NULL) | SELECT * FROM 表1 LEFT JOIN 表2 ON 表1.id = 表2.id; | 需保留左表所有数据,即使右表无匹配(如统计所有用户及其订单,包括未下单用户) | MySQL不支持RIGHT JOIN时可用LEFT JOIN反向操作替代 | |
| 右外连接 (RIGHT JOIN) | 返回右表全部行 + 左表匹配的行(不匹配的左表字段为NULL) | SELECT * FROM 表1 RIGHT JOIN 表2 ON 表1.id = 表2.id; | 需保留右表所有数据,即使左表无匹配 | 实际中较少使用,通常用LEFT JOIN替代 | |
| 子查询 | 标量子查询 | 返回单个值的子查询(一行一列) | SELECT name FROM 用户 WHERE id = (SELECT MAX(user_id) FROM 订单); | 获取聚合值或特定条件值(如最大值、平均值) | 确保子查询返回唯一值,否则可能报错 |
| 行子查询 | 返回一行多列的子查询 | SELECT * FROM 产品 WHERE (价格, 库存) = (SELECT MAX(价格), MIN(库存) FROM 产品); | 同时比较多个列的条件 | 较少使用,需确保子查询结果与外部条件列数一致 | |
| 列子查询 | 返回一列多行的子查询 | SELECT * FROM 用户 WHERE id IN (SELECT user_id FROM 订单 WHERE amount > 100); | 使用IN、ANY、ALL等操作符筛选数据 | 避免返回过多数据导致性能下降 | |
| 表子查询 | 返回多行多列的子查询(作为临时表) | SELECT * FROM (SELECT id, name FROM 用户 WHERE age > 18) AS 成年用户; | 复杂查询中分步处理数据 | 必须为子查询指定别名 | |
| 相关子查询 | 子查询依赖外部查询的值(逐行执行) | SELECT name FROM 用户 u WHERE EXISTS (SELECT 1 FROM 订单 o WHERE o.user_id = u.id); | 基于外部查询结果逐行验证(如存在订单的用户) | 性能较低,避免在大数据量中使用 | |
| 联合查询 | UNION | 合并多个SELECT的结果集(去重) | SELECT 列1 FROM 表1 UNION SELECT 列1 FROM 表2; | 合并结构相同的数据(如不同年份的销售数据合并) | 1. 列数和数据类型必须一致 2. 默认去重,可用 UNION ALL保留重复 |
| UNION ALL | 合并多个SELECT的结果集(不去重) | SELECT 列1 FROM 表1 UNION ALL SELECT 列1 FROM 表2; | 需要保留重复数据的合并操作 | 性能优于UNION,但需确认业务是否需要重复数据 |
内连接的效率往往大于外连接,因为内连接的数据量往往小于外连接,且执行效率较高,外连接需要不停比对
自连接区别于子连接
| 对比维度 | 自连接 | 子查询 |
|---|---|---|
| 适用场景 | 需要基于同一表内的关联关系查询数据(如父子关系、数据比较)。 | 需要逐行处理或基于聚合结果过滤数据。 |
| 性能 | 通常优于子查询(尤其是关联列有索引时)。 | 可能因逐行执行导致性能较低。 |
| 可读性 | 逻辑清晰,但需理解别名机制。 | 嵌套结构可能降低可读性。 |
子查询当中使用到的关键字:
| 关键字 | 定义 | 适用场景 | 语法示例 | 注意事项 |
|---|---|---|---|---|
**ANY** | 比较运算符,若某列值满足与子查询结果的至少一个值的匹配条件,则返回真。 | 需要判断主查询的某个值是否满足子查询结果中的任意一个值。 | SELECT * FROM products WHERE price > ANY (SELECT price FROM competitors); | 1. ANY 和 SOME 完全等价,可互换。2. 子查询结果需与主查询列类型兼容。 |
**SOME** | 与ANY功能相同,是ANY的别名。 | 与ANY完全一致,用于提高代码可读性。 | SELECT * FROM employees WHERE salary > SOME (SELECT salary FROM interns); | 某些数据库(如MySQL)更推荐使用ANY。 |
**ALL** | 比较运算符,若某列值满足与子查询结果的所有值的匹配条件,则返回真。 | 需要判断主查询的某个值是否严格满足子查询结果中的每一个值。 | SELECT * FROM orders WHERE amount > ALL (SELECT amount FROM refunds); | 1. 子查询结果为空时,ALL自动返回真。2. 需谨慎处理空值逻辑。 |


















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









