






关注我们 - 数字罗塞塔计划 -
PART.01
创作背景及思路
随着DeepSeek的横空出世,AIGC(Artificial Intelligence in Generation of Content,人工智能生成内容)概念又被推向了新一轮的高潮。相对于静态的图文阅读,动态的微视频在新媒体平台的传播力和影响力更大,以此同时,当下长短视频创作需求攀升,创作者面临周期紧、成本高、创意受限难题,需要通过各种途径在网上搜集素材,去现实场景中拍摄,以及设计师的后期制作,耗时耗力,借助AIGC技术辅助创作者降本增效,快速获得市场竞争优势已经是必然的选择。
将AIGC用于微视频制作本号也已经探索了将近一年,在去年的两篇文章《大运河申遗十周年,AI科技再现千年繁华》和《AIGC赋能红色档案微视频制作实践》中,我们已经发布过利用AIGC技术辅助制作而成的微视频成果。特别是在后一篇文章中,详细介绍了如何利用AIGC技术一步步通过“文生图、图生图、图生视频”的方式,尝试制作红色档案微视频《人民音乐家冼星海》的过程。
微视频
详细视频请在公众号文章中观看
随着AI技术的飞速发展,上面这个视频在今天看来已经有很多可以改进的地方,在本文中我们就将介绍以更加优化的方式制作本号文章《赤道南北两总星图:星汉灿烂,中西合璧》的介绍微视频,生动还原“两总星图”的创作过程。

PART.02
软硬件设备及工具
与上期AIGC制作的视频所不同的是,此次我们采用了免费开源、且对设备要求不高(本地只需8G显存),1分钟内就能产出4-8秒左右视频的快速制作方法。这种方法优势明显,不仅能够大幅提升效率,快速生成内容,实现流程自动化,还能激发创意,打造独特的视觉效果,满足个性化创作需求。同时,还能减少人力和设备投入,降低创作门槛,让更多人有机会参与到视频创作中来。
01、AIGC平台及工具
此次工具的选择主要遵循“开源、免费、快速、简单易上手”的原则。
· LLM模型:DeepSeek,通义千问,豆包等;
· 图像模型:ComfyUI的Flux.1;
· 视频模型:LTX-Video;
· 插件:Stable Diffusion的Deforum;
· 配音&剪辑:剪映。
02、设备配置
普通PC机即可,本地只需8G显存!
PART.03
制作步骤
01、AI提炼总结文章并生成视频分镜
首先,将文章通过大语言模型处理生成视频脚本,大语言模型不需要本地搭建,直接使用在线免费的如DeepSeek、通义千问、豆包等模型即可。
示例
将文章交给DeepSeek并输入指令:
“帮我把这个文档改写成一个时长2-3分钟的分镜脚本,脚本结构包括序号、景别、风格、画面内容、镜头时长、镜头运动、台词。用表格的形式列出来。”
AI快速根据源文档生成了一份适合制作视频的分镜脚本:

AI生成视频分镜脚本
02、AI根据分镜脚本生成图片
视频采用“先通过文生图,再用图生视频”的方式制作,之所以不直接通过脚本生成视频,主要在于AI文生视频的随机性强、可控性较差。
“文生图”可以采用在线或本地运行两种方法,在线方式更便捷,本地运行更灵活,两者可以结合使用。
方法一:
使用在线平台通过AI生成需要的图片
主流的AI平台大多提供免费的“文生图”服务,直接在线使用即可。由于视频中有大量中国古代元素的人物、建筑,国产模型相较于国外模型更合适。
示例
以豆包的文生图为例,输入指令:
“帮我生成图片:图片风格为「电影写真」场景是一个远景,中国明朝皇帝身穿黄色龙袍,在皇宫里欣赏一副屏风,屏风由8块组成。傍边有侍女跟众多文武大臣,画面从背面看去。比例「16:9」”
AI根据这些提示词生成相应图片。
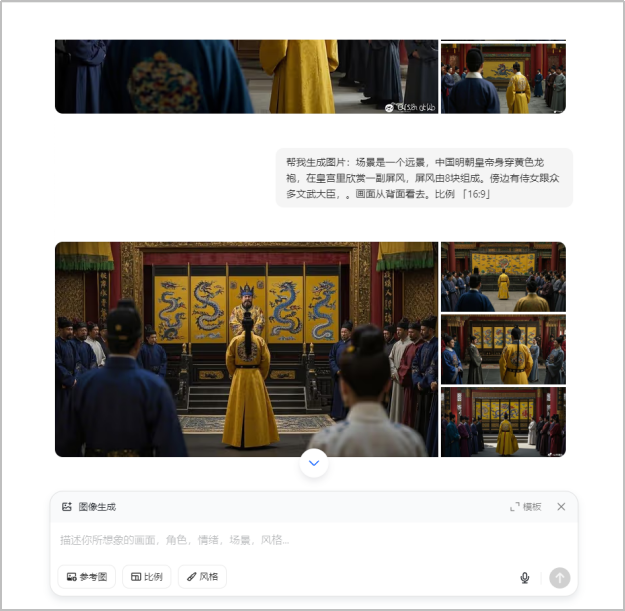
AI根据提示词生成图片

AI生成图片效果
方法二:
通过本地搭建环境,使用AI来写提示词,再到开源的Flux.1中去生成图片
Flux.1是由Black Forest Labs开发的前沿AI图像生成模型,由Stability AI前核心成员主导开发。这个模型在细节丰富度、风格多样性和文本理解能力上表现出色,能生成高质量的图像,某些方面甚至能和Midjourney等知名模型相媲美。Flux模型有3个,分别是Flux Pro、Flux Dev、Flux Schnell,目前ComfyUI已支持该模型,更新到最新版就能使用。
示例
先通过大语言模型生成英文提示词,如与DeepSeek对话:
“为图片生成器制作详细的提示语。当我提供一个描述时,将其转换为能体现电影般品质的提示语,重点关注场景、风格、氛围、灯光和具体的视觉细节。确保提示语能够营造一种丰富且沉浸式的氛围,突出纹理、深度和真实感。保持用词精准又富有描述性,直接可用,旨在实现高质量且具有电影风格的效果,提示词用英文给我,了解回复收到即可。”
简单描述需求后,AI会自动生成提示词。之后在ComfyUI中使用官方的文生图工作流,把提示词写入文本编码器就能生成图片。
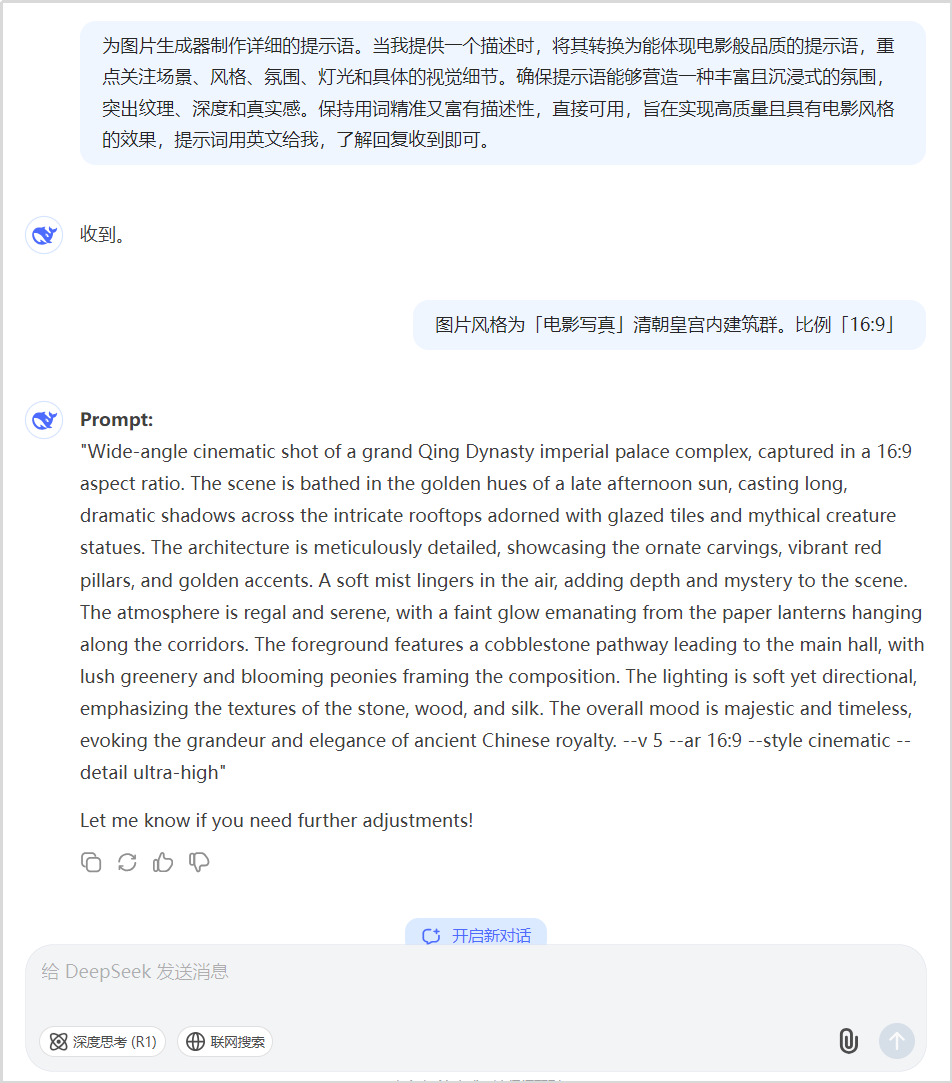
AI生成英文提示词
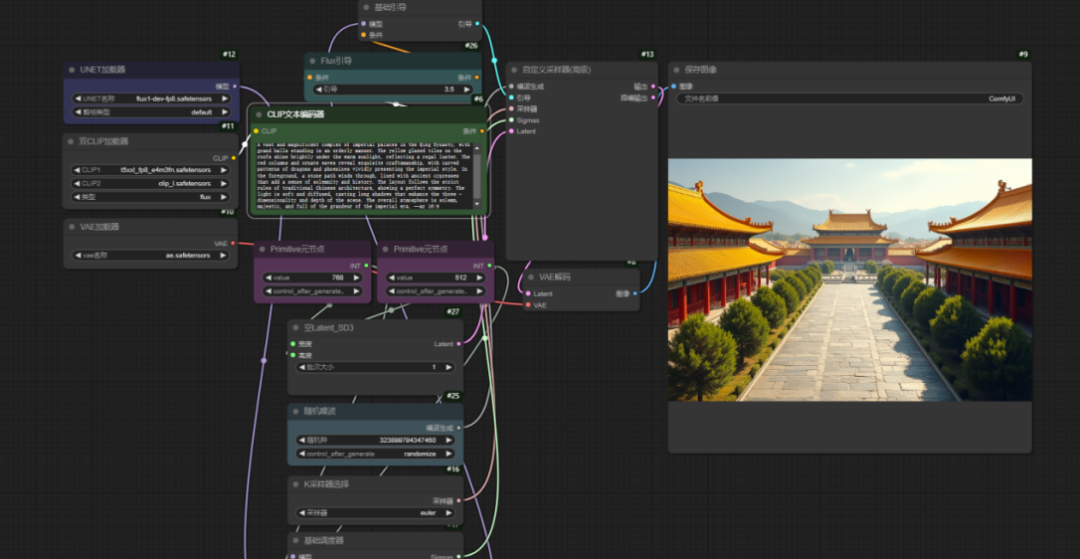
模型根据英文提示词生成图片
通过上述两种方法,生成视频分镜所需的所有图片素材:
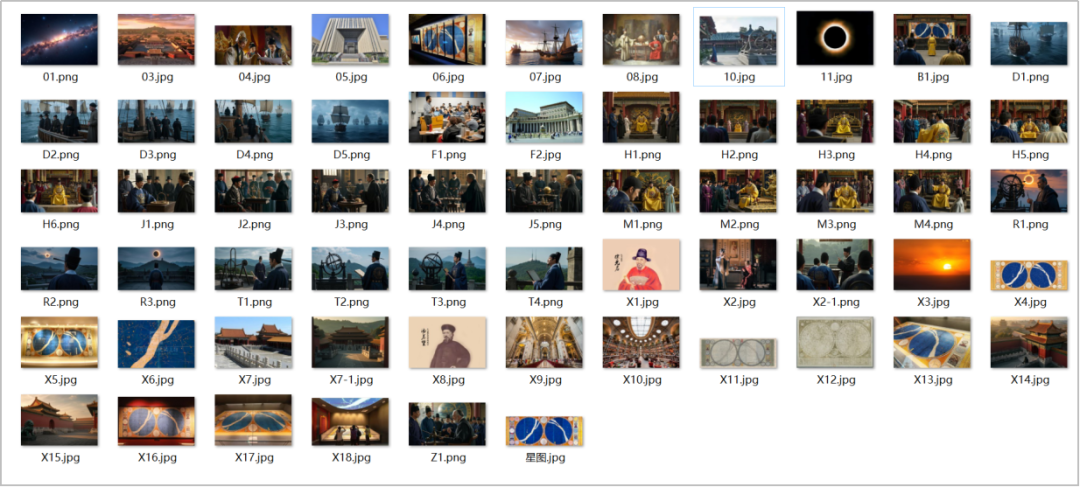
AI生成所有分镜所需的图片素材
03、AI通过图片生成视频
接下来,便到了本文介绍的重点——LTX - Video,这是由Lightricks公司推出的开源AI视频生成模型,基于Diffusion Transformer(DiT)架构,能实时生成高品质视频。它支持文本到视频以及图像到视频的转换,短时间内就能产出高质量内容,并且其最大优势就是生成速度快。
LTX - Video对提示词的要求较为严格,要是生成的视频和创作者预期有偏差,比如画面重点不突出、场景元素缺失,可以通过反推提示词,能精准找到需要调整和补充的关键信息,优化视频内容。而人工写提示词既繁琐又不符合本文追求的“增效”原则。我们可以在ComfyUI工作流中引入DeepSeek大语言模型。让AI根据图片反推提示词,得到相关描述后,再用图片加提示词的方式生成视频。我们只需在节点中简单描述想要的运镜动画和人物动作,LTX - Video就能快速生成视频。
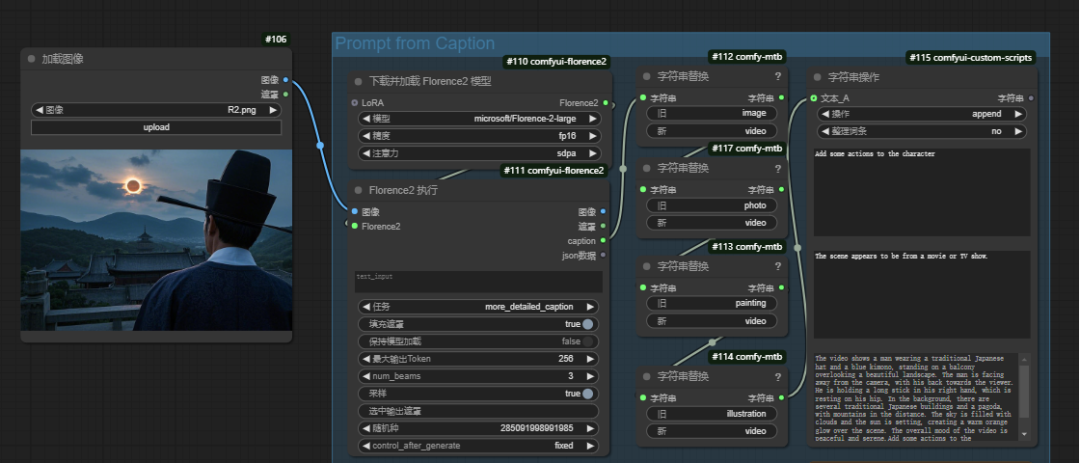
AI反推提示词工作流
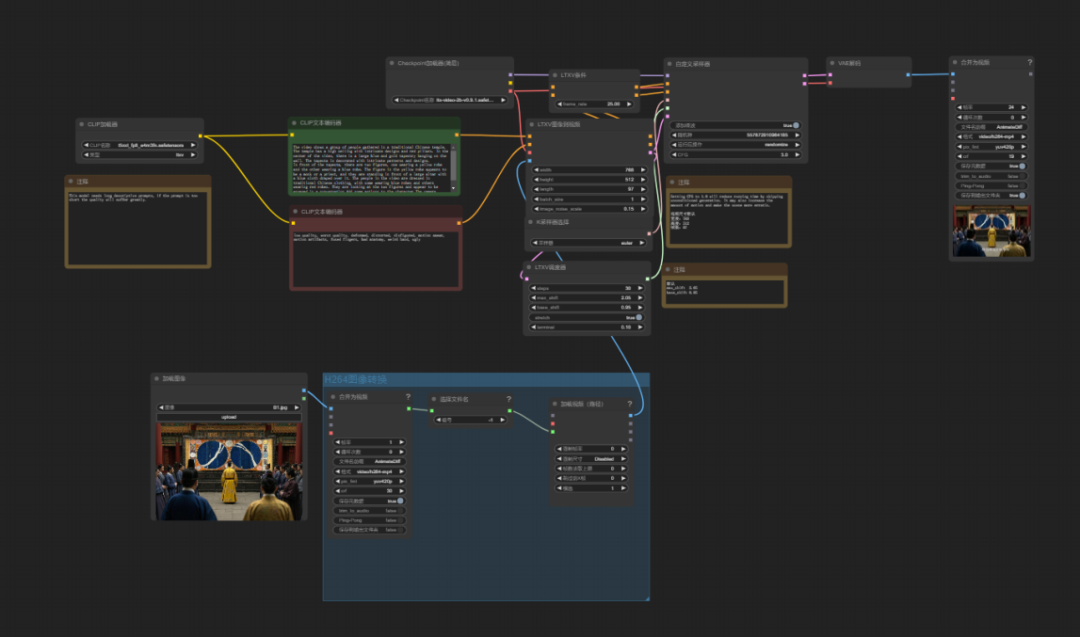
AI生成视频工作流
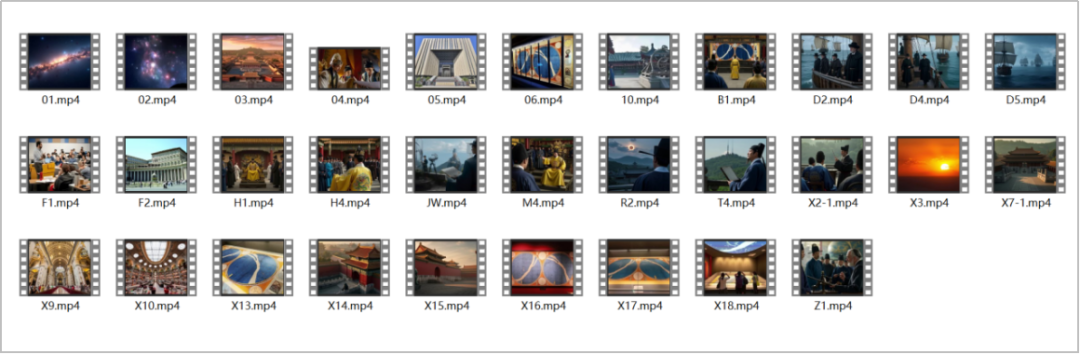
AI生成所有视频片段
此外,若想实现类似视频结尾处“瞬息全宇宙”的特效(该效果在“小央视频”出品的“AI我中华”中广受好评),可以使用Stable Diffusion的Deforum插件。

《AI我中华》视频截图
通过引导图像和简单提示词,Deforum就能根据文本描述或参考图生成连续图像序列并拼接成视频,还能对图像帧序列进行微小变换生成下一帧,从而形成连续的视频效果。
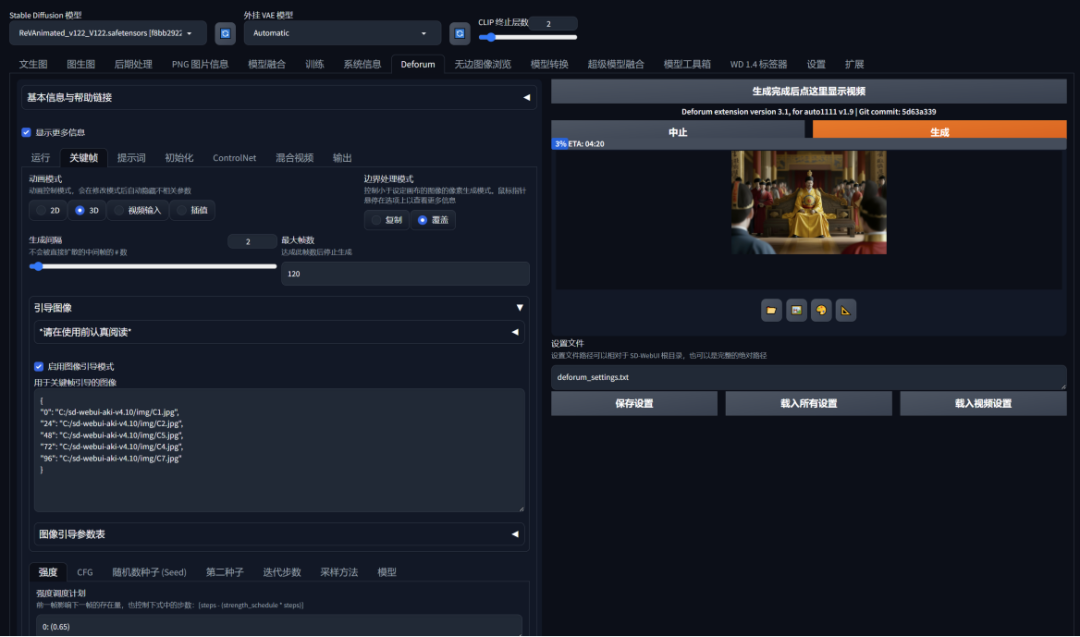
利用Deforum插件生成“瞬息全宇宙”特效
04、AI自动配音、字幕、剪辑
所有视频素材生成完毕,接下来就是将其按顺序组合,剪辑成内容连贯的视频,并添加配音和字幕。对此,我们采用了剪映的文本朗读功能生成配音,并利用剪映自带功能根据配音自动生成字幕。完成这些操作后,再把所有视频片段合并拼接,视频的内容部分就制作完成了。
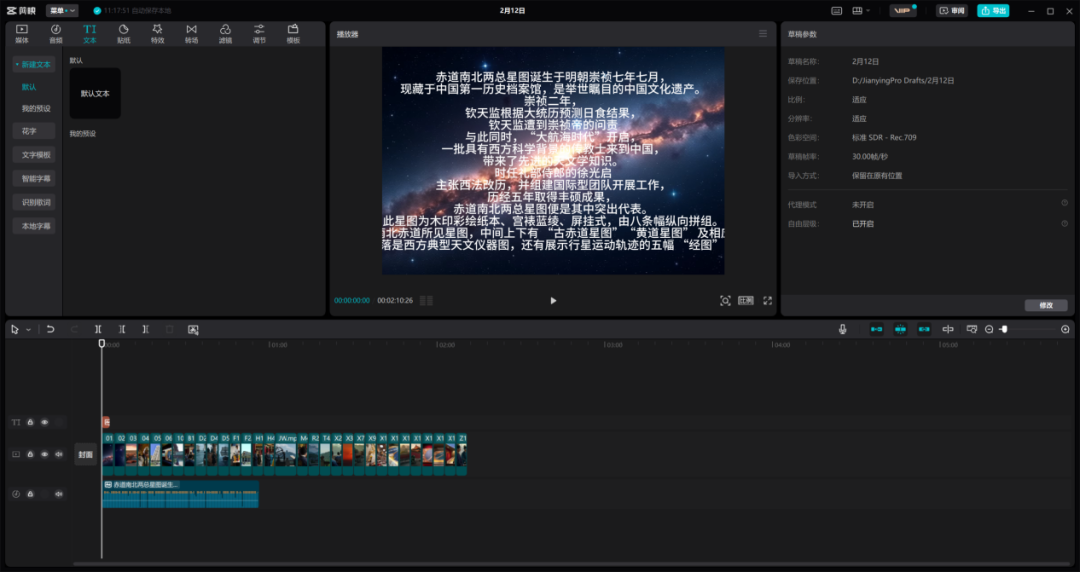
文本朗读功能生成配音
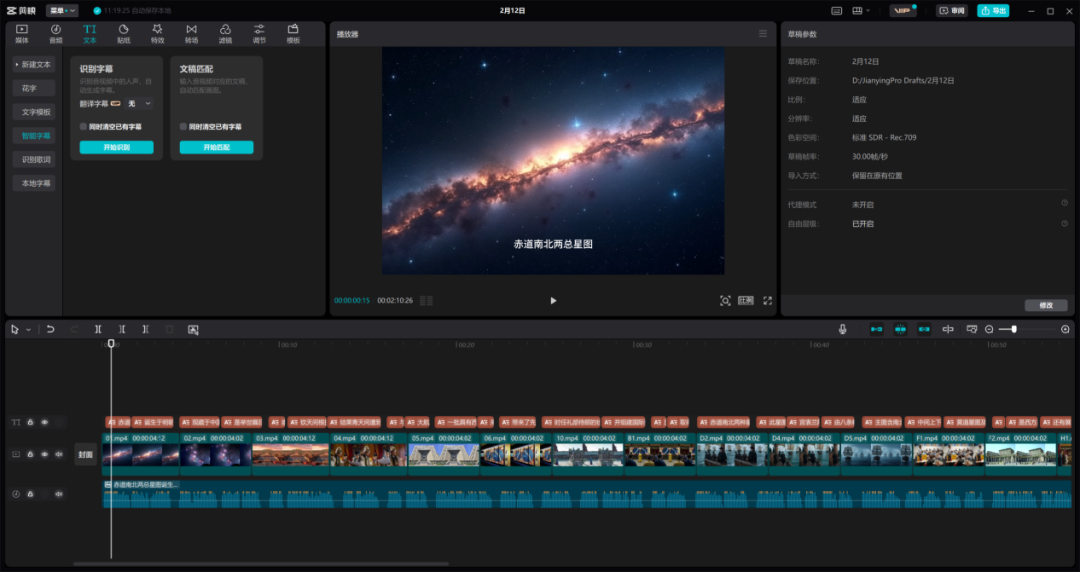
配音自动生成字幕
05、加入片头片尾
最后,在视频的片头和片尾加入数字罗塞塔计划小塔的开场白介绍和结束语总结,整个视频便大功告成了。
PART.04
总结与反思
相比于上一期的AIGC微视频制作,本期在以下几个方面进行了优化改进:
1、分别采用开源免费的AI图像生成模型和视频生成模型,对设备的要求低,简单易上手的同时降低了创作成本。
2、利用AI生成完整的视频分镜脚本,精确到风格、画面内容、镜头时长和运动、台词等细节,为创作者提供创作思路,同时提高了内容的逻辑严密性。
3、在画面流畅度以及人物动作的细节处理上,通过反推出AI生成视频的提示词,补充或调整关键信息,再次生成新的视频。通过反复操作完善,使视频画面的连贯性和动态感得到大幅度提升。
4、由于AIGC视频制作效率比以往提升了一个数量级,极大地解放了人力,创作者能更专注于内容本身的优化处理,进一步提高视频质量。
不过,虽然此次视频制作具有开源、免费、简单易上手等优点,但仍有许多方面需要深入探索。例如如何塑造整体视频人物形象的一致性、训练Lora模型、对人物手部和面部进行高清修复、放大视频,以及通过图片首尾帧拼接生成更长时长的视频等等,仍有待进一步研究和解决。
本号将进一步深入探索AIGC技术赋能微视频制作,今后也会继续将研究成果及时分享给大家,敬请期待~
数字罗塞塔计划公众号致力于作为中立的第三方客观公正地表达自己对于档案信息化领域的看法和观点。真理越辩越明,我们也衷心欢迎越来越多的人投身到档案数字资源管理和保存这一领域的研究中来并发表真知灼见,共同为人类文明的传承而努力奋斗!
关注我们 - 数字罗塞塔计划 -


















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











