






 本文详细探讨了Spark中的RDD分区,包括RDD分区原则、parallelize()和textFile()方法创建RDD时的分区数量设定,以及如何通过自定义分区器实现特定的分区策略。内容涵盖默认分区数量的计算方式,以及如何通过TestMyPartitioner类创建自定义分区器并应用于数据重新分区,最后展示了项目打包和运行的过程。
本文详细探讨了Spark中的RDD分区,包括RDD分区原则、parallelize()和textFile()方法创建RDD时的分区数量设定,以及如何通过自定义分区器实现特定的分区策略。内容涵盖默认分区数量的计算方式,以及如何通过TestMyPartitioner类创建自定义分区器并应用于数据重新分区,最后展示了项目打包和运行的过程。
一、RRD分区
二、RDD分区数量
(一)RDD分区原则
(三)使用parallelize()方法创建RDD时的分区数量
1、指定分区数量
- 使用parallelize()方法创建RDD时,可以传入第二个参数,指定分区数量。
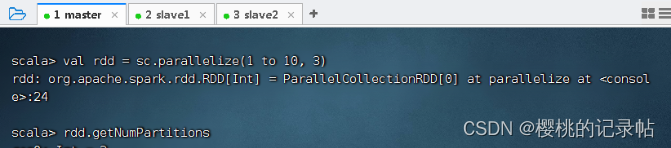
- 分区的数量应尽量等于集群中所有CPU的核心总数,以便可以最大程度发挥CPU的性能。
- 利用
mapPartitionsWithIndex()函数实现带分区索引的映射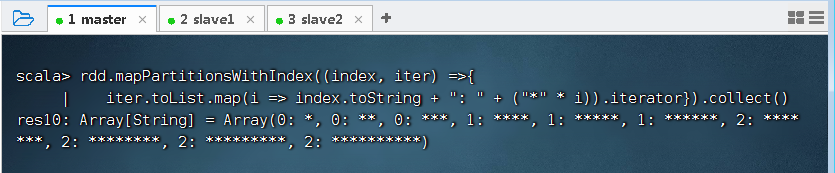
2、默认分区数量
3、分区源码分析
parallelize()方法是在SparkContext类定义的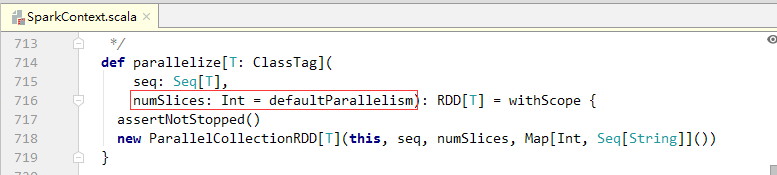
numSlices参数为指定的分区数量,该参数有一个默认值defaultParallelism,是一个无参函数

上述代码中的taskScheduler的类型为特质TaskScheduler,通过调用该特质的defaultParallelism方法取得默认分区数量,而类TaskSchedulerImpl继承了特质TaskScheduler并实现了defaultParallelism方法。
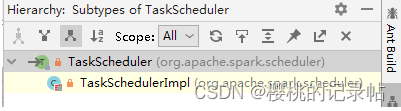
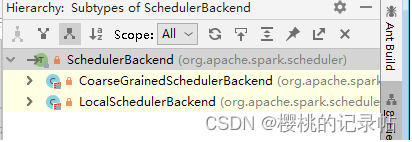
类LocalSchedulerBackend用于Spark的本地运行模式(Executor和Master等在同一个JVM中运行),其调用顺序在TaskSchedulerImpl类之后;类CoarseGrainedSchedulerBackend则用于Spark的集群运行模式。
类LocalSchedulerBackend中的defaultParallelism()方法
上述代码中的字符串spark.default.parallelism为Spark配置文件spark-defaults.conf中的参数spark.default.parallelism;totalCores为本机CPU核心总数。
类CoarseGrainedSchedulerBackend中的defaultParallelism()方法
- 上述代码中,
math.max(totalCoreCount.get(), 2)表示取集群中所有CPU核心总数与2两者中的较大值。 -
(四)使用textFile()方法创建RDD时的分区数量
-
1、指定最小分区数量
- 使用textFile()方法创建RDD时可以传入第二个参数指定最小分区数量。最小分区数量只是
期望的数量,Spark会根据实际文件大小、文件块(Block)大小等情况确定最终分区数量。 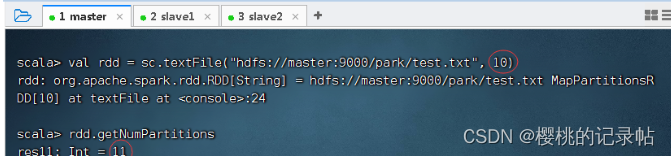
- 在HDFS中有一个文件
/park/test.txt,读取该文件,并指定最小分区数量为10,但是实际分区数量是11。 -
2、默认最小分区数量
- 若不指定最小分区数量,则Spark将采用默认规则计算默认最小分区数量。
- 查看textFile()源码
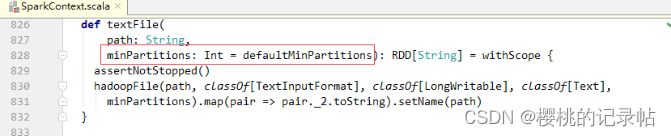
- 上述代码中的minPartitions参数为期望的最小分区数量,该参数有一个默认值defaultMinPartitions,这是一个无参函数,我们来查看其源码。

-
3、默认实际分区数量
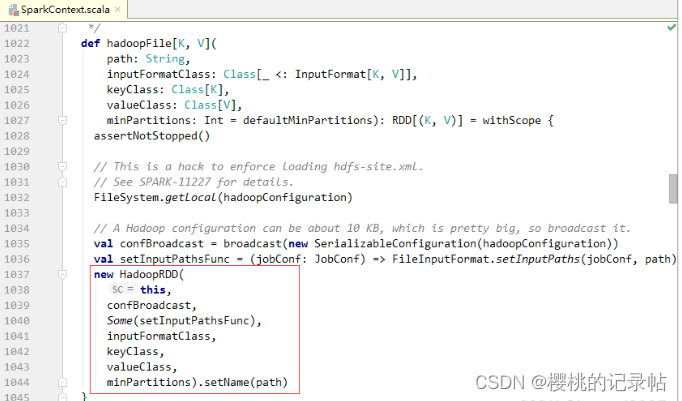
- 最小分区数量确定后,Spark接下来将计算实际分区数量。查看textFile()方法的源码可知,textFile()方法最后调用了一个hadoopFile()方法,并对该方法的结果执行了map()算子。
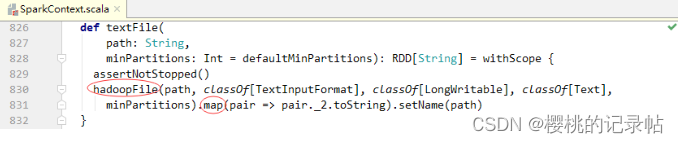
- 查看hadoopFile()方法的源码
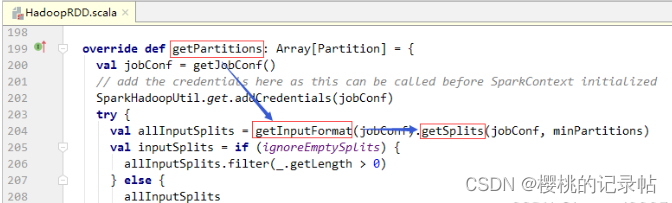
- RDD的最小分区数量。
- 查看
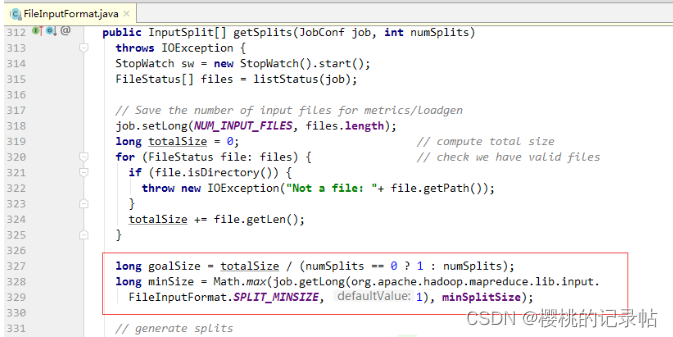
InputFormt接口getSplits()抽象方法
InputFormat有个实现类FileInputFormat,它实现了getSplits()方法
-
(二)解决问题
1、新建自定义分区器
- 创建
MyPartitioner类 
-
package net.huawei.partition import org.apache.spark.Partitioner class MyPartitioner(partitions: Int) extends Partitioner { override def numPartitions: Int = partitions override def getPartition(key: Any): Int = { val partitionId = key.toString match { case "chinese" => 0 case "math" => 1 case "english" => 2 } partitionId } }2、使用自定义分区器
- 调用RDD的partitionBy()方法传入自定义分区器类MyPartitioner的实例,可以对RDD按照自定义规则进行重新分区。
- 创建
TestMyPartitioner单例对象
-
package net.huawei.partition import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestMyPartitioner { def main(args: Array[String]): Unit = { // 创建Spark配置对象 val conf = new SparkConf() .setAppName("TestMyPartitioner") .setMaster("spark://master:7077") // 基于Spark配置创建Spark上下文 val sc = new SparkContext(conf) // 构建模拟数据 val arr = Array( "chinese,94", "math,88", "english,91" ) // 将模拟数据转成RDD,再转成键值对形式的元组 val data: RDD[(String, Int)] = sc.makeRDD(arr).map(line => { (line.split(",")(0), line.split(",")(1).toInt) }) // 将数据重新分区并保存到HDFS的/output目录 data.partitionBy(new MyPartitioner(3)) .saveAsTextFile("hdfs://master:9000/output") } }3、项目打包上传服务器
- 利用IDEA将项目打包 -
MyPartitioner.jar 
- 上传到Spark集群master节点的
/opt目录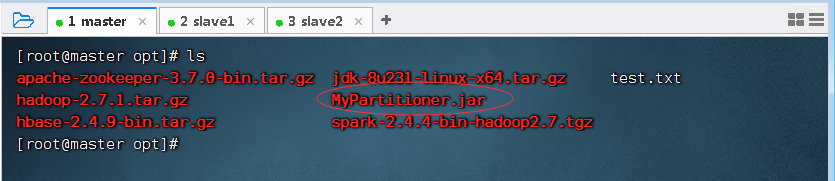
-
4、提交程序运行
- 执行命令:
spark-submit --master spark://master:7077 --class net.huawei.partition.TestMyPartitioner /opt/MyPartitioner.jar 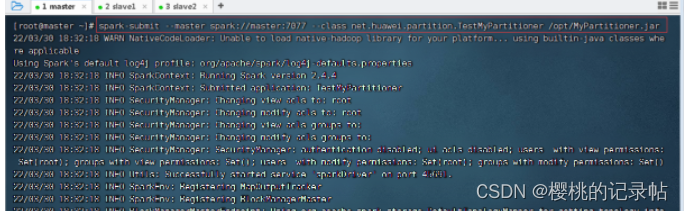
- 查看输出目录
/output 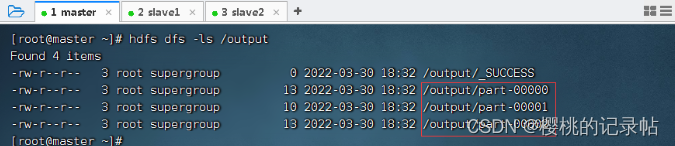
- 查看三个分区的结果文件
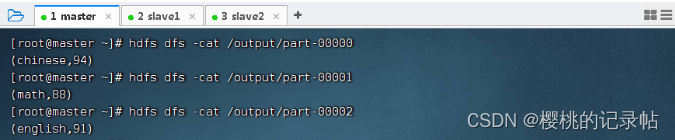

















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









