







 本文介绍了四个著名的深度学习网络模型:AlexNet, VGGNet, GoogleNet 和 ResNet。AlexNet开启了深度学习在图像识别领域的应用;VGGNet通过小尺寸卷积核实现网络加深;GoogleNet使用Inception模块和1x1卷积减少计算量,摒弃全连接层;ResNet通过残差学习解决深度网络的退化问题,引入快捷连接加速训练。这些模型对深度学习的发展产生了深远影响。
本文介绍了四个著名的深度学习网络模型:AlexNet, VGGNet, GoogleNet 和 ResNet。AlexNet开启了深度学习在图像识别领域的应用;VGGNet通过小尺寸卷积核实现网络加深;GoogleNet使用Inception模块和1x1卷积减少计算量,摒弃全连接层;ResNet通过残差学习解决深度网络的退化问题,引入快捷连接加速训练。这些模型对深度学习的发展产生了深远影响。
一、AlexNet

二、VGGNet
Smaller filters, Deeper networks.

1、VGGNet中用到的卷积核都是3 * 3的,尺寸非常小,为何???
答:对于三个3 * 3的卷积核(步长为1),其感受野(effective respective field)和一个7 * 7的卷积核是一样的,都是7 * 7的感受野。但小卷积核可以使网络更深(本来一层7 by 7 layer,现在变成3层3 by 3 layers),这样可以有更多的非线性函数nonlinearity;同时小卷积核组合整体所需的参数比相同感受野的大卷积核要少。

注:对卷积过程的理解:假设我当前的矩阵是28 by 28 by 256的,我有128个3 by 3的卷积核(实际上是3 by 3 by 256,256作为深度会被省略掉),那么我每算一次卷积,都是做了一个3 by 3 by 256和3 by 3 by 256的点积和(对应位置相乘,所有通道都一起算),得到一个数值结果。假设stride是1且无padding,那么最后得到的结果是一个26 by 26 by 128的矩阵。
三、GoogleNet
没有全连接层,用了inception module作为网络的基础模块,并使用1 by 1卷积核(也叫bottleneck layer瓶颈层)来减少inception module中的计算量。


四、ResNet残差网络
1、普通深层卷积神经网络的问题
如果单纯的在普通卷积神经网络上增加深度,那么网络的训练准确率和测试准确率都会变得比层数少的网络差(且不是由于过拟合造成的)。ResNet的提出者认为这实际上是一个优化问题,因为深层的网络会更难优化。
2、残差网络思想
残差神经网络的主要贡献是发现了“退化现象(Degradation)”(ResNet团队把退化现象归因为深层神经网络难以实现“恒等变换(y=x)”),并针对退化现象发明了 “快捷连接(Shortcut connection)”,极大的消除了深度过大的神经网络训练困难问题。
instead of直接学习目标函数H(x),(即我有一个输入x,然后我要学习网络的参数来得到输出H(x)),我们可以将H(x)转化为F(x) + x的形式,也就是相当于x加上一个Δx,于是在每一层网络中我只需要学习这层网络对输入x做了什么修改,即增量,也就是对原有的输入x做了什么改动,也会使得堆积层在输入特征基础上学习到新的特征,这样可以让网络学习起来更容易(只需要找增量即可),同时也保证我这一层的输出至少不会比输入x差。
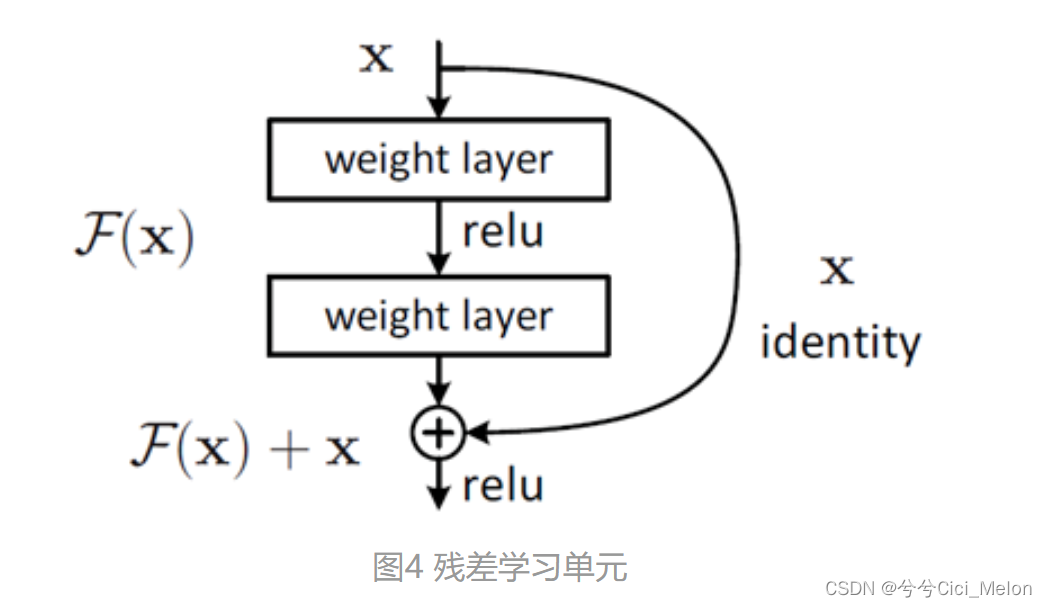

3、残差网络的两个优点
(1)残差网络中,如果某层的权值是零,那么就说明这层是一个恒等映射。而通常正则化方法我们会选择L2正则化,L2正则化有一个趋势就是它会驱使所有权值趋向于0,这在经典的CNN网络中是说不通的,但是在残差网络里,权值为0是可以解释得通的,这就促使模型在那些它不需要的层上直接做恒等映射。
(2)另一个优点体现在梯度的反向传播中。当上游梯度经过一个加法门时,它会分叉然后走过两个不同的路径。而在残差网络中,当上游梯度传过来时,它会走一条卷积块的路径,也会走过残差连接的路径,而很明显的,残差连接的路径是很简单的,在反向传播的过程中也不需要很大的计算量,这相当于给梯度提供了一个高速传播的通道,可以让模型训练得更快更容易。

















 4804
4804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









