






深度学习的思想被提出后, 卷积神经网络在计算机视觉等领域取得了快速的应用, 有很多经典、有意思的网络框架也应然而生.
1. LeNet-5
LeNet-5卷积网络是由LeCun在1998年发表的《Gradient-Based Learning Applied to Document. Recognition》中提出的网络框架. 这是最早的一类卷积神经网络, 其在数字识别领域的应用方面取得了巨大的成功 (手写字体识别).
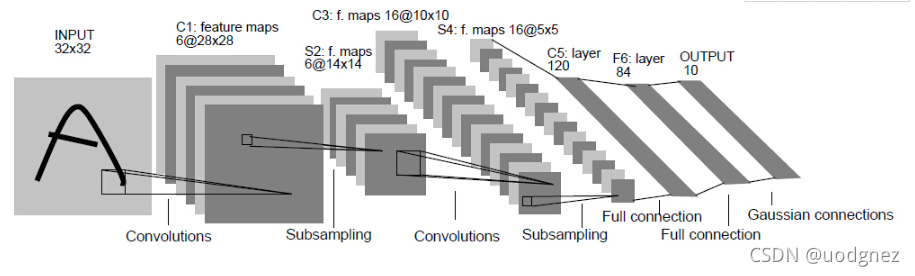
在LeNet-5中, 输入为 32×3232 \times 3232×32 的灰度图像, 经过两个卷积层、两个池化层以及两个全连接层, 最后连接一个输出层.
LeNet-5的第一层使用了 666 个 5×55 \times 55×5 的卷积核对图像进行卷积运算, 且在卷积操作时不使用填补操作, 这样针对一张 32×3232 \times 3232×32 的灰度图像会输出 666 个 28×2828 \times 2828×28 的特征映射. 第二层为池化层, 使用 2×22 \times 22×2 的池化核, 步长大小为 222 ,从而将 666 个 28×2828 \times 2828×28的特征映射转化为 666个 14×1414 \times 1414×14 的特征映射, 该层主要是对数据进行下采样. 第三层为卷积层, 有 161616 个大小为 5×55 \times 55×5的卷积核, 同样在卷积操作时不使用填补操作, 将 666 个 14×1414 \times 1414×14 的特征映射卷积运算后输出为 161616 个 10×1010 \times 1010×10 的特征映射. 第四层为池化层, 使用大小为 2×22 \times 22×2 的池化核, 步长为 222 ,从而将 161616 个 10×1010 \times 1010×10 的特征映射转化为 161616 个 5×55 \times 55×5 的特征映射. 第五和第六层均为全连接层, 且神经元的数量分别为 120120120 和 848484. 最后一层为包含 101010 个神经元的输出层.
2. AlexNet
2012年, AlexNet卷积神经网络结构被提出, 并且以高于第二名 10%10 \%10% 的准确率在2012届ImageNet图像识别大赛中获得冠军, 成功地展示了深度学习算法在计算机视觉领域的威力, 使得CNN成为图像分类上的核心算法模型, 引爆了深度神经网络的应用热潮.
AlexNet模型是一个只用了 888 层的卷积神经网络, 有 555 个卷积层、 333 个全连接层, 在每一个卷积层中包含了一个激活函数ReLU (首次应用) 以及局部相应归一化 (LRN) 处理, 卷积计算后通过最大值池化层对特征映射进行降维处理.
AlexNet的网络结构在设计之初是通过两个GPU进行训练的, 所以其结构中包含两块GPU通信的设计. 但是随着计算性能的提升, 现在完全可以使用单个GPU进行训练.
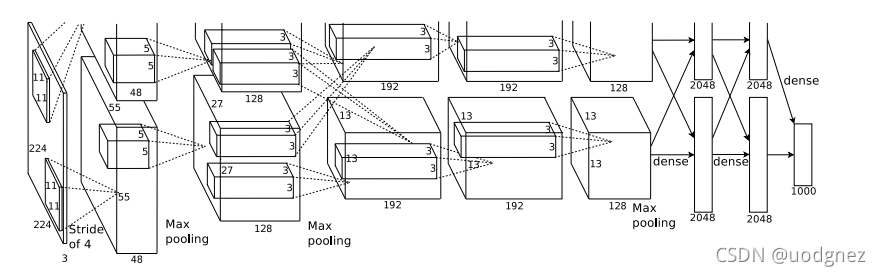
AlexNet网络中输入大小为 227×227227 \times 227227×227 的RGB三通道图像, 在图中 s=4s=4s=4 表示卷积核或者池化核的移动步长为 444 , 在AlexNet中卷积层使用的卷积核从 111111 逐渐减小到 333 , 最后三个卷积层使用的卷积核为 3×33 \times 33×3 , 而池化层则使用了大小为 3×33 \times 33×3 , 步长为 222 , 有重叠的池化, 两个全连接层分别包含 409640964096 个神经元, 最后的输出层使用softmax分类器, 包含 100010001000 个神经元.
3. VGG-Nets
VGG-Nets是由牛津大学计算机视觉组 (Visual Geometry Group) 与2014年提出, 并取得了ILSVRC2014比赛分类项目的第二名. 在其发表的文章《Very Deep Convolutional Networks for Large-Scale Image Recognition》中, 一共提出了四种不同深度层次的卷积神经网络.
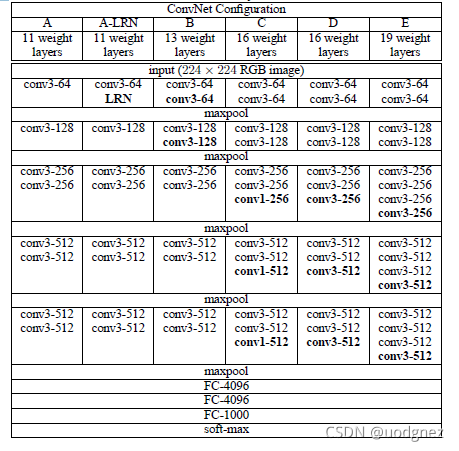
conv3-64表示使用 646464 个 3×33 \times 33×3 的卷积核, maxpool表示使用 2×22 \times 22×2 的最大值池化, FC-4096表示具有 409640964096 个神经元的全连接层.
其中最常使用的VGG网络结构分别是VGG16 (type D) 和VGG19 (type E).
在VGG-Nets中, 通过使用多个较小卷积核 (3×3)( 3 \times 3)(3×3) 的卷积层, 来代替一个卷积核比较大的卷积层. 小卷积核是VGG的一个重要特点, VGG的作者认为 222 个 3×33 \times 33×3 的卷积堆叠获得的感受野大小相当于一个 5×55 \times 55×5 的卷积; 而 333 个 3×33 \times 33×3 卷积的堆叠获取到的感受野相当于一个 7×77 \times 77×7 的卷积. 使用小卷积核一方面可以减少参数, 另一方面相当于及逆行了更多的非线性映射, 可以进一步增加网络的拟合能力.
相比AlexNet使用 3×33 \times 33×3 的池化核, 在VGG-Nets总全部采用 2×22 \times 22×2的池化核. 并且VGG-Nets 中具有更多的特征映射, 网络第一层的通道数为 646464 , 后面每层都进行了翻倍, 最多到 512512512 个通道, 随着通道数的增加, 使得VGG-Nets能够从数据中提取更多的信息. 并且VGG-Nets具有更深的层数, 得到的特征映射更宽.
4. GoogLeNet
GoogLeNet最早出现在2014年的《Going deeper with convolutions》, 取得了ILSVRC2014比赛分类项目的第一名. GoogLeNet共有 222222 层, 并且没有用全连接层, 所以使用了更少的参数, 在GoogLeNet前的AlexNet、VGG等结构, 均通过增大网络的层数来获得更好的训练结果, 但更深的层数同时会带来较多的负面效果, 如过拟合、梯度消失、梯度爆炸等问题.
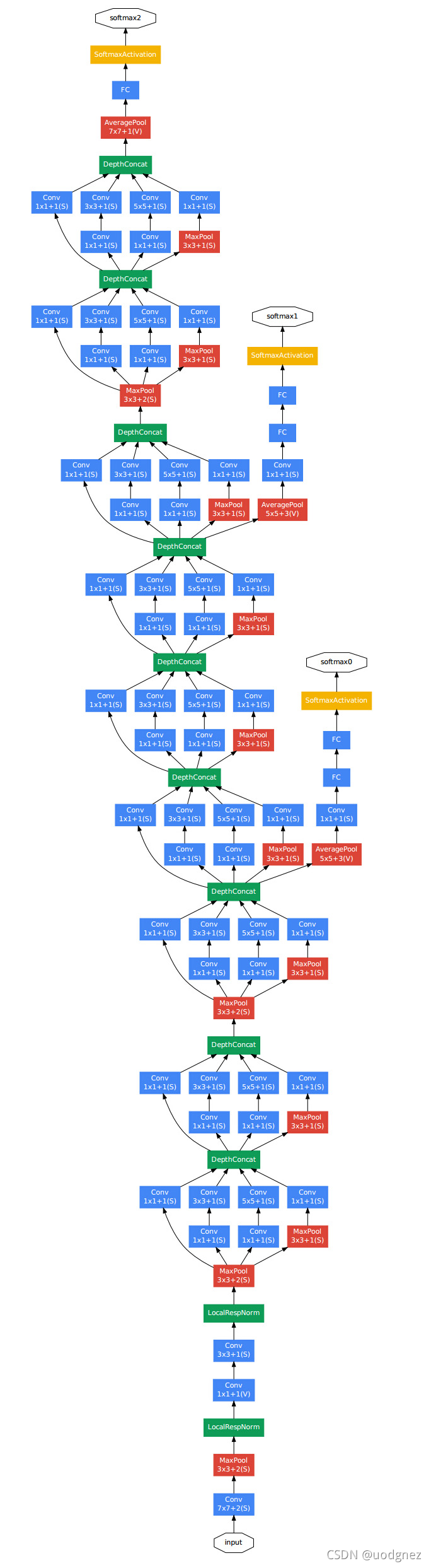
GooLeNet则在保证算力的情况下增大网络的宽度和深度, 尤其是其提出的Inception模块.
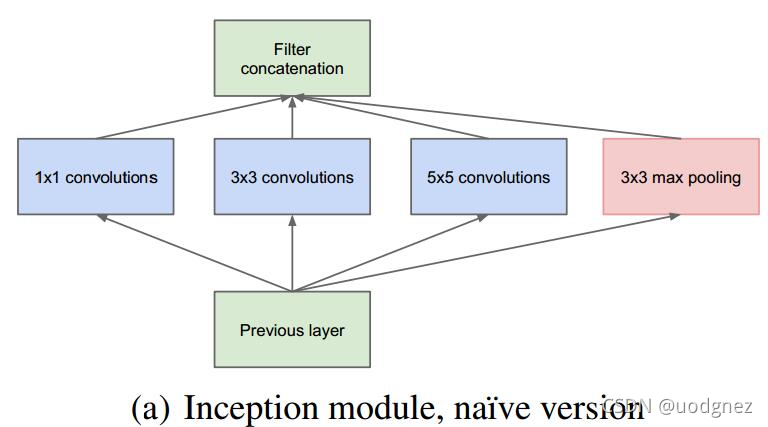
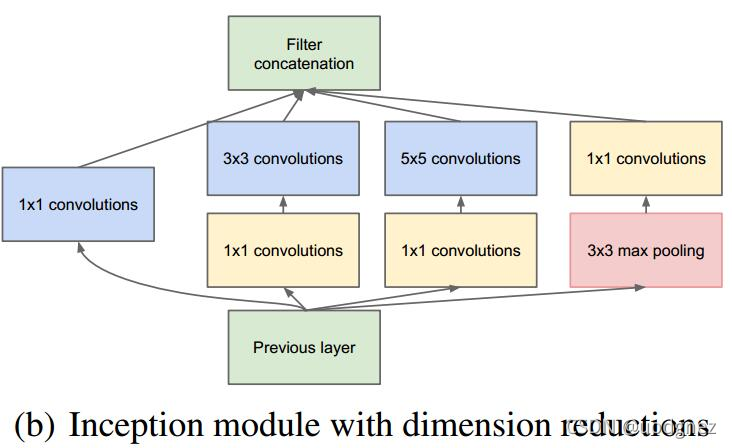
在GoogLeNet中, 前几层中是正常的卷积层, 后面则全部用Inception堆叠而成. 在《Going deeper with convolutions》中给出了两种Inception模块, 分别是简单的Inception模块 (a)(a)(a) 和维度减小的Inception模块 (b)(b)(b) . 与简单的相比, 维度减小的Inception模块在 3×33 \times 33×3 卷积的前面、 5×55 \times 55×5 卷积前面和池化层后面添加 1×11 \times 11×1 卷积进行降维, 从而使维度变得可控并减少计算量.
在GoogLeNet中不仅提出了Inception模块, 还在网络中添加了两个辅助分类器, 起到增加地层网络的分类能力、防止梯度消失、增加网络正则化的作用.
5. ResNet
在介绍ResNet之前, 需要了解下残差学习的概念.
5.1 残差学习
通过实验发现, 深度网络出现了退化问题 (Degradation problem): 网络深度增加时, 网络准确度出现饱和, 甚至出现下降. 这个退化问题至少说明了深度网络不容易训练. 但是我们考虑这样一个事实: 现在你有一个浅层网络, 你想通过向上堆积新层来建立深层网络, 一个极端情况是这些增加的层什么都不学习, 仅仅复制浅层网络性能一样, 也不应该出现退化现象.
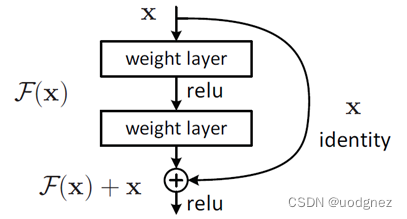
这个有趣的假设让 Dr. He 灵感爆发, 他提出了残差学习来解决退化问题. 对于一个堆积层结构, 当输入为 xxx 时其学习到的特征是 H(x)H(x)H(x), 现在我们希望其可以学习到残差 F(x)=H(x)−xF(x) = H(x) -xF(x)=H(x)−x, 这样其实原始的学习特征是 F(x)+xF(x) +xF(x)+x.之所以这样是因为残差学习相比原始特征更容易直接学习. 当残差为 000 时, 此时堆积层仅仅做了恒等映射, 至少网络性能不会下降, 实际上残差不会为 000, 这也会使得堆积层在输入特征基础上学习到新的特征, 从而拥有更好的性能. 残差学习的结构如下图所示. 有点类似于电路中的“短路连接”.
ResNet网络是参考了VGG19网络, 在其基础上进行了修改, 并通过短路机制加入了残差单元. 如下图所示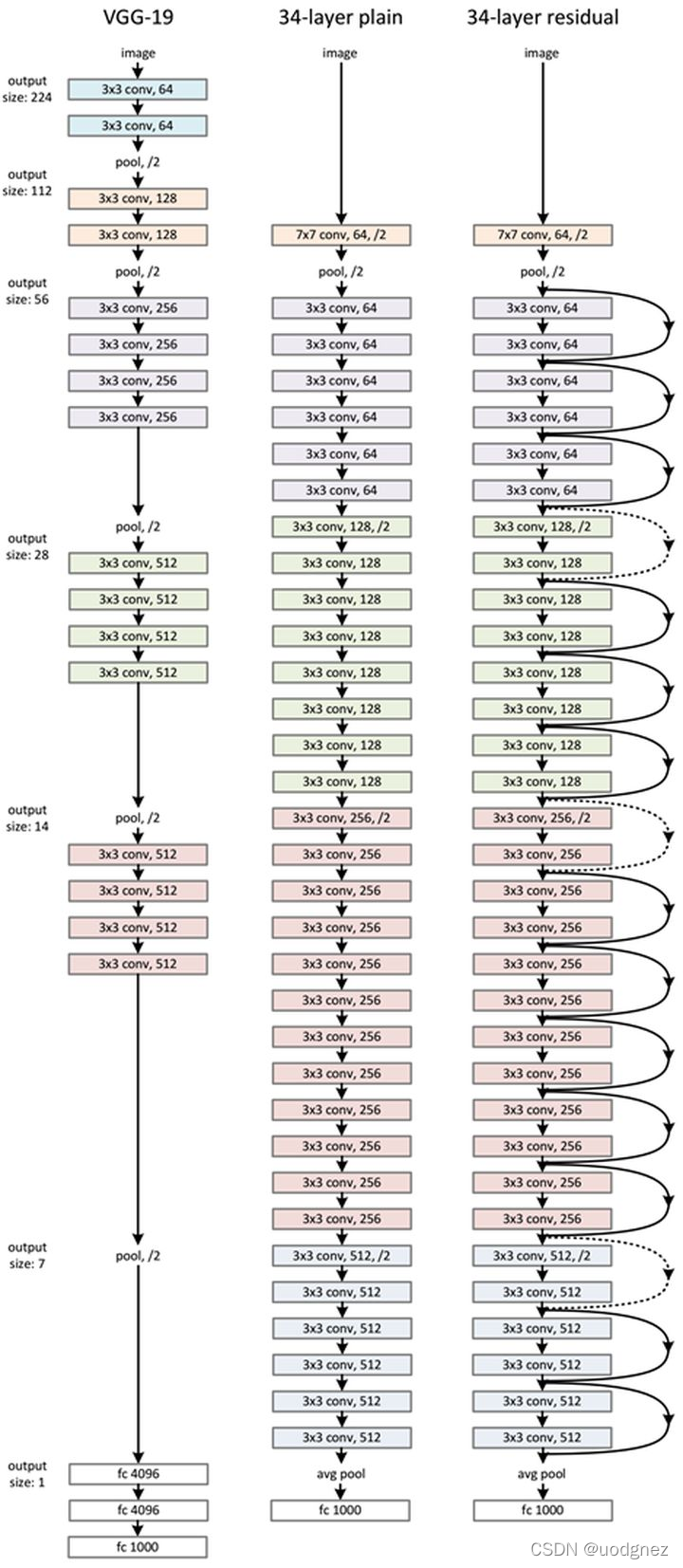
变化主要体现在ResNet直接使用步长为 222 的卷积做下采样, 并且用global average pool层替换了FC层. ResNet的一个重要设计原则是: 当feature map 大小降到一半时, feature map的数量增加一倍, 这保持了网络层的复杂度. 从图中可以看出, ResNet相比普通网络每两层间增加了短路机制, 这就形成了残差学习, 其中虚线表示feature map数量发生了改变.
《深度学习入门与实践》
https://www.cnblogs.com/skyfsm/p/8451834.html
https://blog.youkuaiyun.com/shuzfan/article/details/50738394
https://zhuanlan.zhihu.com/p/31852747

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









