







文章目录
一.阿克


知识点:微扰排序:
理解
微扰排序通常可以解决这样一类问题:我们需要对所求解的问题求出一个最优顺序,可以通过 临项交换 法确定一个 cmp 函数,然后对于求出序列顺序进行解答即可。
对本题的分析
首先明确题意:要我们对于每个询问 k k k ,将前 k k k 个人以任意顺序排序,然后根据这个顺序求出一个答案,最后输出答案的最小值。
第一步:考虑如果有一个排列顺序,我们该怎样求出这个顺序的答案。 我们设 i d [ k ] id[k] id[k] 存储的是人的 编号顺序。 设 f [ i ] f[i] f[i] 表示从第 i i i 个人处理到最后一个人所需要的最小体重。 考虑转移 f [ i − 1 ] = m a x ( b [ i d [ i − 1 ] ] + f [ i ] , a [ i d [ i − 1 ] ] ) f[i - 1] = max(b[id[i - 1]] + f[i], a[id[i - 1]]) f[i−1]=max(b[id[i−1]]+f[i],a[id[i−1]])。因为 所有人都加上 b [ i d [ i − 1 ] ] b[id[i - 1]] b[id[i−1]] 等价于当前体重减去 b [ i d [ i − 1 ] ] b[id[i - 1]] b[id[i−1]]。减去这个体重后还要大于等于 f [ i ] f[i] f[i], 并且当前体重至少要为 a [ i d [ i − 1 ] ] a[id[i - 1]] a[id[i−1]]。所以可以想到这个转移方程。
第二步:考虑如何确定一个最优顺序。我们考虑 临项交换。及对于一个已经有的编号序列, 我们考虑在其他元素的顺序不改变,相邻两项 x x x 和 y y y 在什么情况下 x x x 应该放在 y y y 的左边。

我们设从 编号u到pn的最小体重是 c c c。我们考虑 当 x x x 放在 y y y 左边时 从 x x x 到 p n pn pn 的答案, 以及 当 y y y 放在 x x x 左边时从 x x x 到 p n pn pn 的答案。当前边小于等于后边时,那么显然 x x x 放在 y y y 左边更优。
设
r
e
s
res
res 为考虑过
x
x
x 和
y
y
y 的最小体重。
当
x
x
x 在
y
y
y 左边时:
r
e
s
=
m
a
x
(
a
[
x
]
,
b
[
x
]
+
m
a
x
(
a
[
y
]
,
c
+
b
[
y
]
)
)
=
m
a
x
(
a
[
x
]
,
b
[
x
]
+
a
[
y
]
,
b
[
x
]
+
b
[
y
]
+
c
)
res = max(a[x], b[x] + max(a[y], c + b[y])) = max(a[x], b[x] + a[y], b[x] + b[y] + c)
res=max(a[x],b[x]+max(a[y],c+b[y]))=max(a[x],b[x]+a[y],b[x]+b[y]+c)
当
x
x
x 在
y
y
y 右边时:
r
e
s
=
m
a
x
(
a
[
y
]
,
b
[
y
]
+
m
a
x
(
a
[
x
]
,
b
[
x
]
+
c
)
)
=
m
a
x
(
a
[
y
]
,
b
[
y
]
+
a
[
y
]
,
b
[
y
]
+
b
[
x
]
+
c
)
res = max(a[y], b[y] + max(a[x], b[x] + c)) = max(a[y], b[y] + a[y], b[y] + b[x] + c)
res=max(a[y],b[y]+max(a[x],b[x]+c))=max(a[y],b[y]+a[y],b[y]+b[x]+c)
很显然,当
x
x
x 放左边更优时,则有
m
a
x
(
a
[
x
]
,
b
[
x
]
+
a
[
y
]
)
<
=
m
a
x
(
a
[
y
]
,
b
[
y
]
+
a
[
x
]
)
max(a[x], b[x] + a[y]) <= max(a[y], b[y] + a[x])
max(a[x],b[x]+a[y])<=max(a[y],b[y]+a[x])
因此我们可以写出这样一个
c
m
p
cmp
cmp 函数
bool cmp(int x, int y){
return (max(a[x], b[x] + a[y]) < max(a[y], b[y] + a[x]));
}
确定好顺序后
D
P
DP
DP求解即可。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 3100;
typedef long long LL;
int n, id[N];
LL a[N], b[N], f[N];
bool cmp(int x, int y){
return (max(a[x], b[x] + a[y]) < max(a[y], b[y] + a[x]));
}
void solve(int x){
for(int i = 1; i <= x; i++) id[i] = i;
sort(id + 1, id + x + 1, cmp);
f[x] = a[id[x]];
for(int i = x - 1; i >= 1; i--) f[i] = max(a[id[i]], b[id[i]] + f[i + 1]);
printf("%lld\n", f[1]);
}
int main(){
scanf("%d", &n);
for(int i = 1; i <= n; i++){
scanf("%lld%lld", &a[i], &b[i]);
}
for(int i = 1; i <= n; i++){
solve(i);
}
return 0;
}
这样我们就有了 70 p t s 70pts 70pts
对于
100
p
t
s
100pts
100pts:
我们考虑先确定
n
n
n 个人的最优顺序。那么对于每个前缀,它们的顺序和在这
n
n
n 个人的最优顺序中它们的相对顺序是一样的。这样我们考虑用线段树维护将一个人加入序列使其成为最优顺序的过程。时间复杂度
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n)。
#include<bits/stdc++.h>//考虑用线段树维护加入元素
using namespace std;
const int N = 5e5 + 10;
typedef long long LL;
inline int read(){
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){if(c == '-') f = -1; c = getchar();}
while(isdigit(c)){x = (x << 1) + (x << 3) + (c ^ 48); c = getchar();}
return x * f;
}
int n, id[N], pos[N];
LL a[N], b[N], INF = 5e14;
struct SegmentTree{//考虑用线段树维护
int l, r;
LL f = -INF, sumb;
#define l(x) t[x].l
#define r(x) t[x].r
#define f(x) t[x].f// f记录打败当前区间内的人所需的最小体重
#define sumb(x) t[x].sumb//sumb记录当前区间内的人b之和
}t[N * 4];
bool cmp(int x, int y){
return max(a[x], b[x] + a[y]) < max(a[y], b[y] + a[x]);
}
void build(int p, int l, int r){
l(p) = l, r(p) = r;
if(l == r) return ;
int mid = (l + r >> 1);
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
}
void update(int p){
f(p) = max(f(p << 1), f(p << 1 | 1) != -INF ? f(p << 1 | 1) + sumb(p << 1) : -INF);//进行转移
sumb(p) = sumb(p << 1) + sumb(p << 1 | 1);//转移
}
void ins(int p, int pos, LL a, LL b){
if(l(p) == r(p)){
f(p) = a; sumb(p) = b;//插入单点
return ;
}
int mid = (l(p) + r(p) >> 1);
if(pos <= mid) ins(p << 1, pos, a, b);
else ins(p << 1 | 1, pos, a, b);
update(p);
}
int main(){
n = read();
for(int i = 1; i <= n; i++) a[i] = 1LL * read(), b[i] = 1LL * read();
for(int i = 1; i <= n; i++) id[i] = i;
sort(id + 1, id + n + 1, cmp);//求出这个最优顺序
build(1, 1, n);
for(int i = 1; i <= n; i++) pos[id[i]] = i;//记录每个编号排完序后的位置
for(int i = 1; i <= n; i++){
ins(1, pos[i], a[i], b[i]);//将当前的人加入它对应的位置中
printf("%lld\n", f(1));//答案就是当前的 f(1)
}
return 0;
}
二.看题

知识点:性质题
对本题的分析
首先,因为所有边的出度之和为 总边数。所以当 m m m 为奇数时,一定无解。
当 m m m 为偶数时该怎么做?
我们考虑如果原图是 一棵树 该怎么做?
我们可以从 叶子 开始考虑, 它的 父边 肯定要指向它才能保证它的出度为偶数。考虑完叶子后,再考虑它们的父亲:如果在目前父亲的出度为 奇数,就让它的 父边 指向它的父亲, 否则就让他的父边指向自己。 这样,我们一层一层考虑,相当于 不为根 的每个节点都有一条父边 调节它出度的奇偶性。 那么如果除了根的所有节点的出度都为偶数,根的出度为
m
−
s
u
m
m - sum
m−sum,
s
u
m
sum
sum 为除了根以外节点的出度, 显然
m
m
m 为偶数时根的出度一定为偶数。
那么原图如果不是树呢?
可以想到 先构建出来一棵生成树, 考虑往生成树上加 剩下的边。 实际上,剩下的边会改变它相连的两个点之一的初始奇偶性, 当
m
m
m 为偶数时, 这条边的出度给哪一个节点都可以,我们都可以通过非根节点的父边来调节它的出度,使得最后有一组合法方案。复杂度
O
(
n
)
O(n)
O(n) ,代码很好写。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
int n, m, u[N], v[N], bin[N], Out[N], Du[N], len, head[N], tot;
queue< int > q;
struct res{
int u, v;
}r[N];
struct edge{
int v, last;
}E[N * 2];
void add(int u, int v){
E[++tot].v = v;
E[tot].last = head[u];
head[u] = tot;
}
bool vis[N];
bool cmp(res a, res b){
return ((a.u < b.u) || (a.u == b.u && a.v < b.v));
}
int Find(int x){
return bin[x] == x ? x : bin[x] = Find(bin[x]);
}
int main(){
scanf("%d%d", &n, &m);
for(int i = 1; i <= m; i++){
scanf("%d%d", &u[i], &v[i]);
}
for(int i = 1; i <= n; i++) bin[i] = i;
for(int i = 1; i <= m; i++){
if(Find(u[i]) != Find(v[i])){
add(u[i], v[i]); add(v[i], u[i]);
Du[u[i]]++; Du[v[i]]++;
int f1 = Find(u[i]), f2 = Find(v[i]);
bin[f1] = f2;
}
else{//给谁都无所谓
Out[u[i]]++;
r[++len] = (res){u[i], v[i]};
}
}
if(m & 1){
printf("-1\n");
return 0;
}
else{
bool flag = 0;
for(int i = 1; i <= n; i++)
if(Du[i] == 1) q.push(i);
while(!q.empty()){
int u = q.front(); q.pop();
vis[u] = 1;
for(int i = head[u]; i; i = E[i].last){
int v = E[i].v;
if(vis[v]) continue;
if(Out[u] & 1) Out[u]++, r[++len] = (res){u, v};
else Out[v]++, r[++len] = (res){v, u};
Du[v]--;
if(Du[v] == 1) q.push(v);
}
}
}
sort(r + 1, r + len + 1, cmp);
for(int i = 1; i <= len; i++){
printf("%d %d\n", r[i].u, r[i].v);
}
return 0;
}
三. Power Tree
题面:Power Tree
这题考场上想到了正解思路,但是有细节没有调出来 。
分析
实际上想要调控所有叶子的点权都可以任意调控,那么每个叶子都应该有一个对应的 调控点 :每一个叶子的调控点就是它到根的路径上 深度最大的被选中的点 , 并且任意两个叶子不能有共同的一个调控点。基于这个性质,我们可以得到两个结论:
1. 设有 n n n 个叶子有一个共同的父亲,那么对于这 n n n 个叶子而言,至少要选中 n − 1 n - 1 n−1 个 叶子。
2.剩下的一个叶子可与它的父亲合并成一个新的叶子。
那么这 n − 1 n - 1 n−1 个叶子肯定要选择代价最小的几个,剩下那个代价最大的叶子可与它的父亲合并成一个新的叶子,新叶子的代价为 m i n ( c [ x ] , c [ f a x ] ) min(c[x], c[fa_x]) min(c[x],c[fax])。
这样我们就可以从下往上做,最后求出答案即可。
至于输出方案,我们可以对每个节点开一个 待选 集合,每次选中一个点将它的待选集合中的点打上标记,合并可以将父亲的编号插入儿子的集合,并交换集合的指针即可。时间复杂度
O
(
n
)
O(n)
O(n)
CODE:
#include<bits/stdc++.h>// 啥都不会
using namespace std;
const int N = 2e5 + 10;
typedef long long LL;
int n, u, v, head[N], tot, leaf;
int w[N];
inline int read(){
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){if(c == '-') f = -1; c = getchar();}
while(isdigit(c)){x = (x << 1) + (x << 3) + (c ^ 48); c = getchar();}
return x * f;
}
struct edge{
int v, last;
}E[N * 2];
vector< int > res;
void add(int u, int v){
E[++tot] = (edge){v, head[u]};
head[u] = tot;
}
int p[N];//指针
vector< int > g[N];//存储编号
vector< int > son[N];
bool flag[N];//可能被选到的数
LL val[N], Sum;//存每个点的权值
inline bool cmp(int x, int y){
return val[x] < val[y];
}
void dfs(int x, int fa){
val[x] = w[x], g[x].push_back(x), p[x] = x; int len = 0;//权重和点
int Maxn = 0, id = -1, maxnum = 0;
for(int i = head[x]; i; i = E[i].last){
int v = E[i].v;
if(v == fa) continue;
len++;
dfs(v, x);
if(val[v] > Maxn) Maxn = val[v], id = v, maxnum = 1;
else if(Maxn == val[v]) maxnum++;
}
if(len == 0) return ;
for(int i = head[x]; i; i = E[i].last){
int v = E[i].v;
if(v == fa) continue;
if(v == id) continue;
Sum += 1LL * val[v];
for(int j = 0; j < g[p[v]].size(); ++j) flag[g[p[v]][j]] = 1;
}
if(maxnum > 1){
for(int j = 0; j < g[p[id]].size(); ++j) flag[g[p[id]][j]] = 1;
vector< int > V;
swap(V, g[p[id]]);
}
if(val[id] < val[x]){//比它小
val[x] = val[id];
p[x] = p[id];//更换指针
}
else if(val[id] == val[x]){
p[x] = p[id];
g[p[id]].push_back(x);//加入x
}
}
inline void solve(){//每一层都至少选成一条链之后合并??
dfs(1, 0);
Sum += 1LL * val[1];
for(int i = 0; i < g[p[1]].size(); ++i) flag[g[p[1]][i]] = 1;
int num = 0;
for(int i = 1; i <= n; ++i){
if(flag[i]) num++;
}
printf("%lld %d\n", Sum, num);
for(int i = 1; i <= n; ++i){
if(flag[i]) printf("%d ", i);
}
}
int main(){
n = read();
for(int i = 1; i <= n; ++i) w[i] = read();
for(int i = 1; i < n; ++i){
u = read(), v = read();
add(u, v); add(v, u);
}
solve();
return 0;
}
四.让他们在一起

考场上看错了
T
T
T 的范围
分析:
可以想到,如果合并两只兔子最多需要 n 2 n^2 n2 步(状态最多 n 2 n^2 n2个),我们从前往后依次合并两只兔子,并按操作移动其他兔子的位置即可。最多 ( k ∗ n 2 ) (k * n^2) (k∗n2) 步,时间复杂度 O ( n 2 k 2 ) O(n^2k^2) O(n2k2)。合并可以用 bfs 搜索状态,并回溯记录操作即可。
CODE:
#include<bits/stdc++.h>//O(n^2 * k^2)
using namespace std;
typedef pair< int, int > PII;
const int N = 1010;
int n, k, T, u[N], d[N], l[N], r[N], pos[N], op[N];
vector< int > ans;
vector< int > tans;
int read(){
int x = 0, f = 1; char c = getchar();
while(!isdigit(c)){if(c == '-') f = -1; c = getchar();}
while(isdigit(c)){x = (x << 1) + (x << 3) + (c ^ 48); c = getchar();}
return x * f;
}
bool vis[N][N];//vis[x][y] 表示 x 和 y这个状态是否搜过
PII lst[N][N];//lst[i][j] 表示这个状态是有哪个状态跳过来的
int opr[N][N];
queue< PII > q;
void rec(int sx, int sy, int x, int y){//记录答案
if(x == sx && y == sy) return ;
rec(sx, sy, lst[x][y].first, lst[x][y].second);
tans.push_back(opr[x][y]);
}
void Merge(int x, int y){//将x和y合并
memset(vis, 0, sizeof(vis));
while(!q.empty()) q.pop();
q.push(make_pair(pos[x], pos[y])); vis[pos[x]][pos[y]] = 1;
while(!q.empty()){
PII f = q.front(); q.pop();
int nx = f.first, ny = f.second;
if(nx == ny){
tans.clear();
rec(pos[x], pos[y], nx, ny);
break;
}
int tx, ty; PII t = make_pair(nx, ny);
tx = u[nx], ty = u[ny];
if(!vis[tx][ty]) q.push(make_pair(tx, ty)), vis[tx][ty] = 1, lst[tx][ty] = t, opr[tx][ty] = 1;
tx = d[nx], ty = d[ny];
if(!vis[tx][ty]) q.push(make_pair(tx, ty)), vis[tx][ty] = 1, lst[tx][ty] = t, opr[tx][ty] = 2;
tx = l[nx], ty = l[ny];
if(!vis[tx][ty]) q.push(make_pair(tx, ty)), vis[tx][ty] = 1, lst[tx][ty] = t, opr[tx][ty] = 3;
tx = r[nx], ty = r[ny];
if(!vis[tx][ty]) q.push(make_pair(tx, ty)), vis[tx][ty] = 1, lst[tx][ty] = t, opr[tx][ty] = 4;
}
}
void jump(){//往后跳
for(int i = 1; i <= k; i++){
int np = pos[i];
for(auto x : tans){
if(x == 1) pos[i] = u[pos[i]];
if(x == 2) pos[i] = d[pos[i]];
if(x == 3) pos[i] = l[pos[i]];
if(x == 4) pos[i] = r[pos[i]];
}
}
}
int main(){
n = read(), k = read(), T = read();
for(int i = 1; i <= k; i++) pos[i] = read();
for(int i = 1; i <= n; i++){
u[i] = read(), d[i] = read(), l[i] = read(), r[i] = read();
if(u[i] == 0) u[i] = i;
if(d[i] == 0) d[i] = i;
if(l[i] == 0) l[i] = i;
if(r[i] == 0) r[i] = i;//没有就是本身
}
for(int i = 1; i < k; i++){
Merge(i, i + 1);
for(auto x : tans){
ans.push_back(x);
}
jump();
}
for(auto x : ans){
if(x == 1) putchar('N');
if(x == 2) putchar('S');
if(x == 3) putchar('W');
if(x == 4) putchar('E');
}
return 0;
}
五.讨厌的线段树
知识点:有关线段树的技巧
分析
若两个节点长度一样,那么区间在它们内部可能的覆盖情况是一模一样的。我们可以考虑 按长度给节点分类,然后 DP 即可。
设 d p [ n ] [ c ] [ 1 / 0 ] [ 1 / 0 ] dp[n][c][1/0][1/0] dp[n][c][1/0][1/0] 表示节点长度为 n n n,在它内部(包含它自己)涉及了 c c c 个节点,是/否与左端点贴合,是/否与右端点贴合的方案数。答案 d p [ n ] [ k ] [ 0 ] [ 0 ] + d p [ n ] [ k ] [ 0 ] [ 1 ] + d p [ n ] [ k ] [ 1 ] [ 0 ] + d p [ n ] [ k ] [ 1 ] [ 1 ] dp[n][k][0][0] + dp[n][k][0][1] + dp[n][k][1][0] + dp[n][k][1][1] dp[n][k][0][0]+dp[n][k][0][1]+dp[n][k][1][0]+dp[n][k][1][1]。 转移分讨即可:
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 130;
typedef long long LL;
map< int, LL > dp[N][2][2];
int n, k;
LL calc(int n, int c, int l, int r){//在长度为n的节点内,经过c个节点, 是否贴合左右端点的方案数
if(c <= 0) return 0;
if(dp[c][l][r].count(n)) return dp[c][l][r][n];//如果已经被访问过,直接返回 .count代表查找mp里是否有这个key
if(l && r){//左右都贴合
if(c == 1) return dp[c][l][r][n] = 1;
else return dp[c][l][r][n] = 0;
}
if(n == 1) return dp[c][l][r][n] = 0;//如果没有左右都贴合,直接返回0
LL ret = 0;
if(!l && !r){//都没有贴合
ret += calc((n + 1) / 2, c - 1, 0, 0) + calc(n / 2, c - 1, 0, 0);
ret += calc((n + 1) / 2, c - 1, 0, 1) + calc(n / 2, c - 1, 1, 0);
for(int i = 1; i < c; i++){//枚举左边有的
ret += calc((n + 1) / 2, i, 0, 1) * calc(n / 2, c - 1 - i, 1, 0);
}
}
if(!l && r){//左不贴右贴
ret += calc(n / 2, c - 1, 0, 1) + calc(n / 2, c - 1, 1, 1);//不夸过中间点
ret += calc((n + 1) / 2, c - 2, 0, 1);//过中间点
}
if(l && !r){//左贴右不贴
ret += calc((n + 1) / 2, c - 1, 1, 0) + calc((n + 1) / 2, c - 1, 1, 1);//不过中间点
ret += calc(n / 2, c - 2, 1, 0);//过中间点
}
return dp[c][l][r][n] = ret;
}
int main(){
cin >> n >> k;
for(int i = 1; i <= k; i++){
cout << calc(n, i, 0, 0) + calc(n, i, 0, 1) + calc(n, i, 1, 0) + calc(n, i, 1, 1);
putchar(' ');
}
return 0;
}
六.奇怪异或和
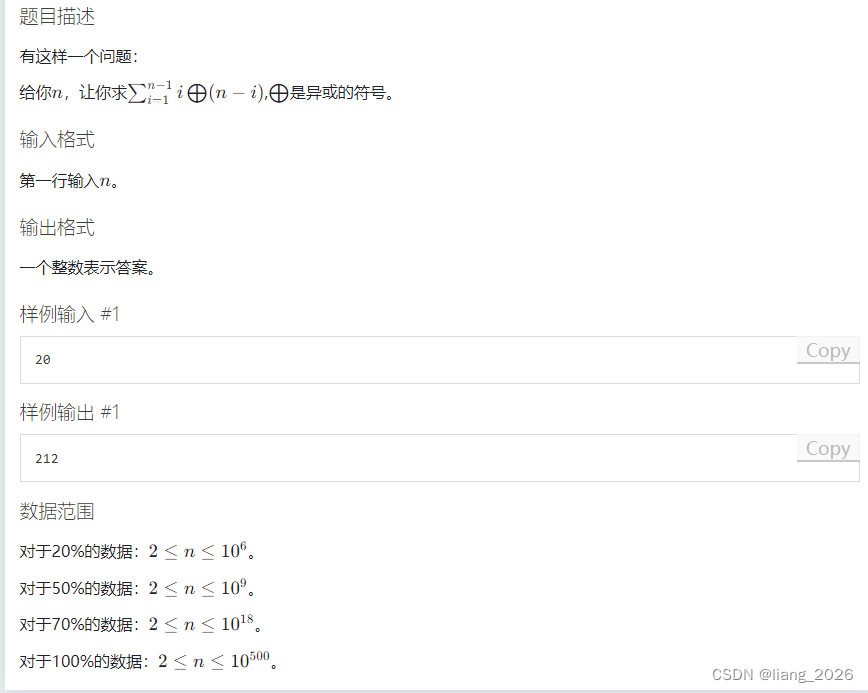
知识点:处理异或的技巧,折半思想
分析
看到数据规模 n < = 1 0 500 n <= 10^{500} n<=10500,感觉设计一个 O ( l o g 2 n ) O(log_2n) O(log2n) 的算法可以过掉。
设 f ( n ) = s u m i = 1 n − 1 i ⊕ ( n − i ) f(n) = sum_{i = 1}^{n - 1} i \oplus (n - i) f(n)=sumi=1n−1i⊕(n−i)
1. 当 n n n 为奇数时
设
n
=
2
k
+
1
n = 2k + 1
n=2k+1
f
(
n
)
f(n)
f(n)
=
∑
i
=
1
n
−
1
i
⊕
(
n
−
i
)
= \sum_{i = 1}^{n - 1} i \oplus (n - i)
=∑i=1n−1i⊕(n−i)
=
2
∗
∑
i
=
1
k
2
i
⊕
(
2
k
−
2
i
+
1
)
= 2 * \sum_{i = 1}^{k} 2i\oplus(2k-2i+1)
=2∗∑i=1k2i⊕(2k−2i+1)
=
2
∗
∑
i
=
1
k
2
i
⊕
(
2
k
−
2
i
)
+
2
k
=2*\sum_{i=1}^{k}2i\oplus(2k -2i) + 2k
=2∗∑i=1k2i⊕(2k−2i)+2k
=
4
∗
∑
i
=
1
k
i
⊕
(
k
−
i
)
+
2
k
=4*\sum_{i=1}^{k}i\oplus(k-i)+2k
=4∗∑i=1ki⊕(k−i)+2k
=
4
∗
∑
i
=
1
k
−
1
i
⊕
(
k
−
i
)
+
6
k
=4*\sum_{i=1}^{k-1}i\oplus(k-i)+6k
=4∗∑i=1k−1i⊕(k−i)+6k
=
4
f
(
k
)
+
6
k
=4f(k)+6k
=4f(k)+6k
这里的处理妙在 一个偶数异或一个偶数,等于它们分别除以2后的异或值再乘2。通过这个性质将不连续的 2 i 2i 2i 变成了连续的,从而与 f ( k ) f(k) f(k) 建立关系。
我们因此也可以收到启发:无论是奇数异或奇数,偶数异或偶数,还是奇数异或偶数。我们都可以单独考虑个位的1并把它的贡献拿出来使其变成 偶数异或偶数。基于这个性质,我们可以将 n n n 为偶数时的转移式推出来。
2.当 n n n 为偶数时
设
n
=
2
k
n = 2k
n=2k
f
(
n
)
f(n)
f(n)
=
∑
i
=
1
k
−
1
2
i
⊕
(
2
k
−
2
i
)
+
s
u
m
i
=
1
k
(
2
i
−
1
)
⊕
(
2
k
−
2
i
+
1
)
=\sum_{i=1}^{k-1}2i\oplus(2k-2i) + sum_{i=1}^{k}(2i-1)\oplus(2k-2i+1)
=∑i=1k−12i⊕(2k−2i)+sumi=1k(2i−1)⊕(2k−2i+1) //分别考虑偶数和奇数
∑ i = 1 k − 1 2 i ⊕ ( 2 k − 2 i ) = 2 s u m i = 1 k − 1 i ⊕ ( k − i ) = 2 f ( k ) \sum_{i=1}^{k-1}2i\oplus(2k-2i) = 2sum_{i=1}^{k-1}i\oplus(k-i)=2f(k) ∑i=1k−12i⊕(2k−2i)=2sumi=1k−1i⊕(k−i)=2f(k)
∑
i
=
1
k
(
2
i
−
1
)
⊕
(
2
k
−
2
i
+
1
)
\sum_{i=1}^{k}(2i-1)\oplus(2k-2i+1)
∑i=1k(2i−1)⊕(2k−2i+1)
=
∑
i
=
0
k
−
1
(
2
i
+
1
)
⊕
(
2
k
−
2
i
−
1
)
=\sum_{i=0}^{k-1}(2i+1)\oplus(2k-2i-1)
=∑i=0k−1(2i+1)⊕(2k−2i−1)
=
∑
i
=
0
k
−
1
(
2
i
+
1
)
⊕
[
2
(
k
−
1
)
−
2
i
+
1
]
=\sum_{i=0}^{k-1}(2i+1)\oplus[2(k-1)-2i+1]
=∑i=0k−1(2i+1)⊕[2(k−1)−2i+1]
=
∑
i
=
0
k
−
1
2
i
⊕
[
2
(
k
−
1
)
−
2
i
]
=\sum_{i=0}^{k-1}2i\oplus[2(k-1)-2i]
=∑i=0k−12i⊕[2(k−1)−2i]
=
2
∑
i
=
0
k
−
1
i
⊕
(
k
−
1
−
i
)
=2\sum_{i=0}^{k-1}i\oplus(k-1-i)
=2∑i=0k−1i⊕(k−1−i)
=
2
∑
i
=
1
k
−
2
i
⊕
(
k
−
1
−
i
)
+
4
k
−
4
=2\sum_{i=1}^{k-2}i\oplus(k-1-i)+4k-4
=2∑i=1k−2i⊕(k−1−i)+4k−4
=
2
f
(
k
−
1
)
+
4
k
−
4
=2f(k-1)+4k-4
=2f(k−1)+4k−4
综上所述:
f
(
n
)
=
{
4
f
(
k
)
+
6
k
n
为奇数
2
f
(
k
)
+
2
f
(
k
−
1
)
+
4
k
−
4
n
为偶数
f(n)=\left\{ \begin{array}{rcl} 4f(k)+6k & & {n为奇数}\\ 2f(k)+2f(k-1)+4k-4 & & {n为偶数}\\ \end{array} \right.
f(n)={4f(k)+6k2f(k)+2f(k−1)+4k−4n为奇数n为偶数
记忆化搜索 即可
CODE:
#include<bits/stdc++.h>
using namespace std;
typedef __int128 Int;
typedef long long LL;
map< LL, Int > f;
LL n;
Int calc(LL x){
if(f[x]) return f[x];
if(x == 1 || x == 0 || x == 2) return 0;
if(x & 1) return (f[x] = 4 * calc(x / 2LL) + (Int)(6 * (x / 2)));//奇数
else return (f[x] = (2 * calc(x / 2) + ((Int)(4 * (x / 2 - 1LL)) + 2 * calc(x / 2 - 1))));//偶数
}
void write(Int x){
if(x < 0) x = -x, putchar('-');
if(x > 9) write(x / 10);
putchar(x % 10 + '0');
}
int main(){
cin >> n;
Int a = calc(n);
write(a);
putchar('\n');
return 0;
}

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









