







在学习Hadoop之前,我们看看典型的大数据平台架构图:
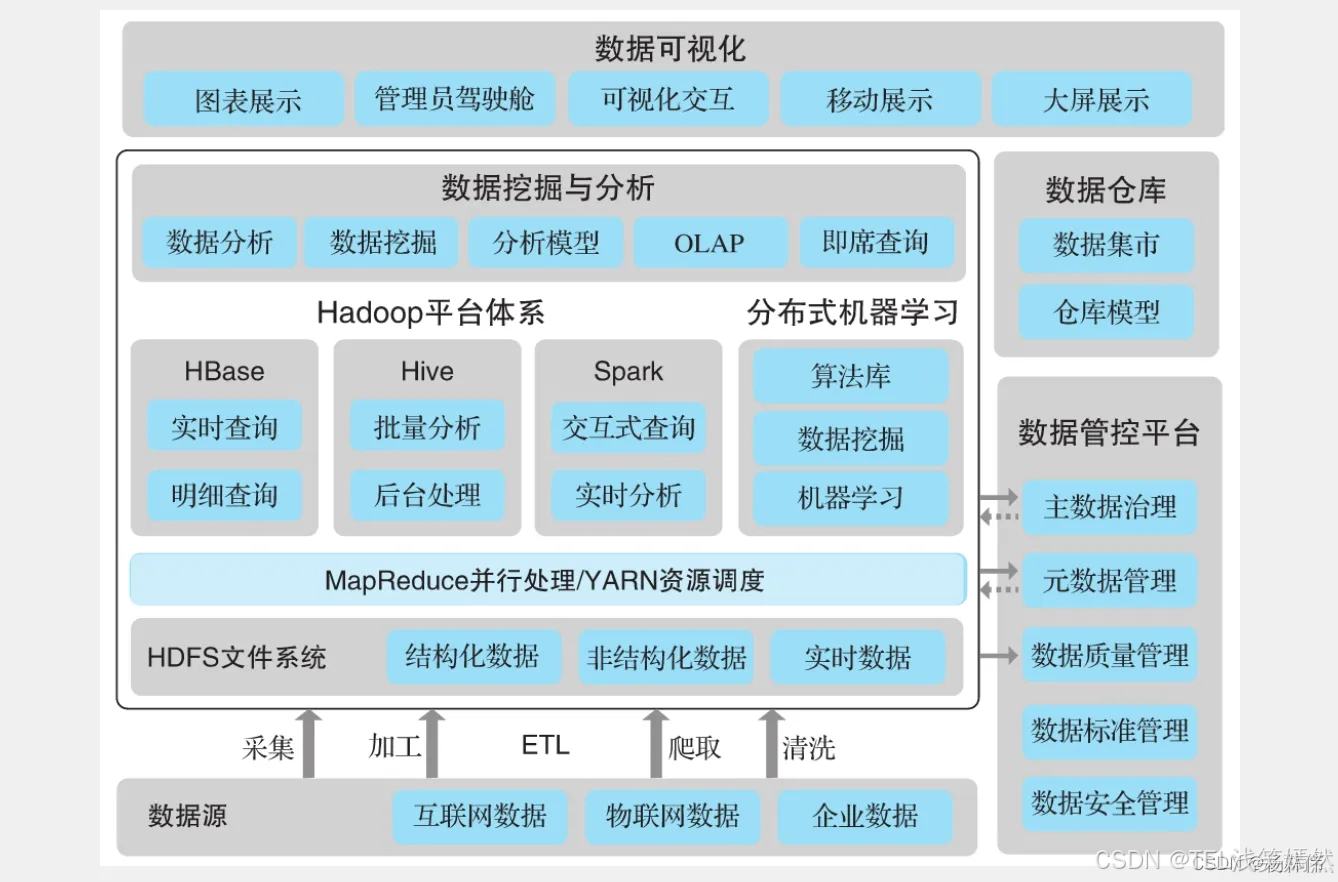
可以看到Hadoop在大数据平台里处于一个技术核心的地位,本文来讲解下。
02 Hadoop概述
2.1 Hadoop定义
Hadoop :是使用 Java 编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache 的开源框架。
2.2 Hadoop优势
Hadoop的优势:
- Hadoop 是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
- Hadoop可以用单节点模式安装,但是只有多节点集群才能发挥 Hadoop 的优势,我们可以把集群扩展到上千个节点,而且扩展过程中不需要先停掉集群。
2.3 Hadoop组成
看看Hadoop由哪些组件组成:
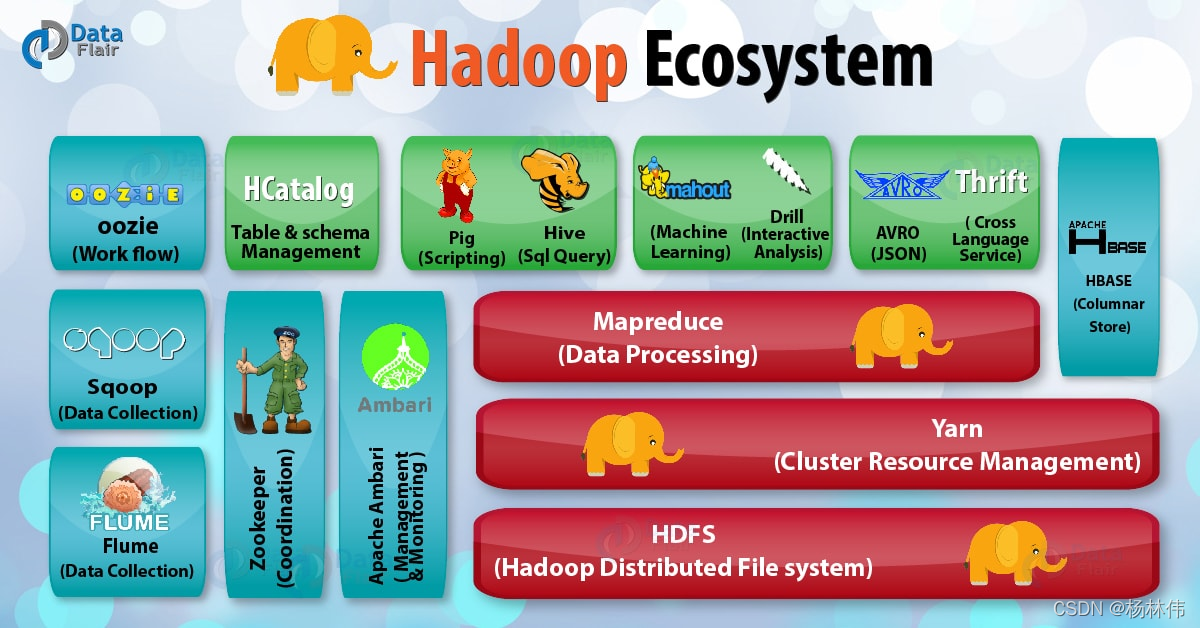
以上的各个组件都是属于Hadoop的生态系统的,如果想入门大数据,都是需要学习,它们分别是:
- Hadoop HDFS(核心):Hadoop 分布式存储系统;
- Yarn(核心):Hadoop 2.x版本开始才有的资源管理系统;
- MapReduce(核心):并行处理框架;
- HBase:基于HDFS的列式存储数据库,它是一种 NoSQL 数据库,非常适用于存储海量的稀疏的数据集;
- Hive:Apache Hive是一个数据仓库基础工具,它适用于处理结构化数据。它提供了简单的 sql 查询功能,可以将sql语句转换为 MapReduce任务进行运行;
- Pig:它是一种高级脚本语言。利用它不需要开发Java代码就可以写出复杂的数据处理程序;
- Flume:它可以从不同数据源高效实时的收集海量日志数据;
- Sqoop:适用于在 Hadoop 和关系数据库之间抽取数据;
- Oozie:这是一种 Java Web 系统,用于Hadoop任务的调度,例如设置任务的执行时间和执行频率等;
- Zookeeper:用于管理配置信息,命名空间。提供分布式同步和组服务;
- Mahout:可扩展的机器学习算法库。
其中:HDFS、MapReduce、YARN是核心。
2.3.1 HDFS
已有专栏专门讲解,有兴趣的同学可以参考《HDFS专栏》
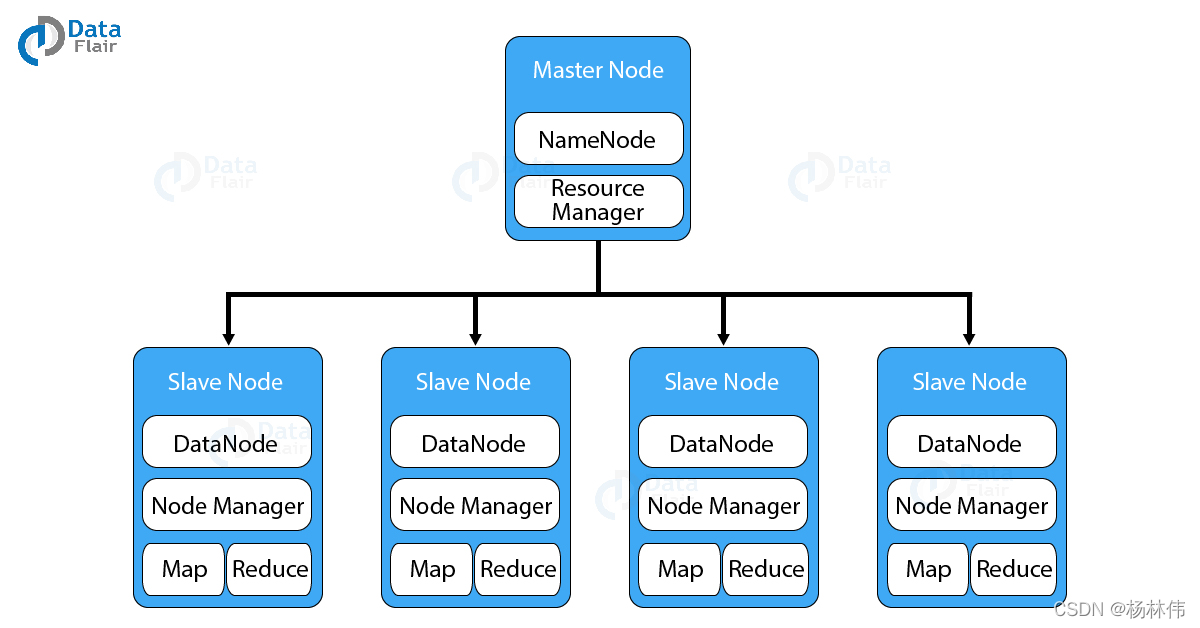
HDFS :即 Hadoop 分布式文件系统(Hadoop Distribute File System),以分布式存储的方式存储数据。
HDFS 也是一种 Master-slave 架构,NameNode 是运行 master 节点的进程,它负责命名空间管理和文件访问控制。DataNode 是运行在 slave 节点的进程,它负责存储实际的业务数据,如下图:
2.3.2 MapReduce
已有专栏专门讲解,有兴趣的同学可以参考《MapReduce专栏》
Hadoop MapReduce 是一种编程模型,它是 Hadoop 最重要的组件之一。它用于计算海量数据,并把计算任务分割成许多在集群并行计算的独立运行的 task。
MapReduce 是 Hadoop的核心,它会把计算任务移动到离数据最近的地方进行执行,因为移动大量数据是非常耗费资源的。

2.3.3 YARN
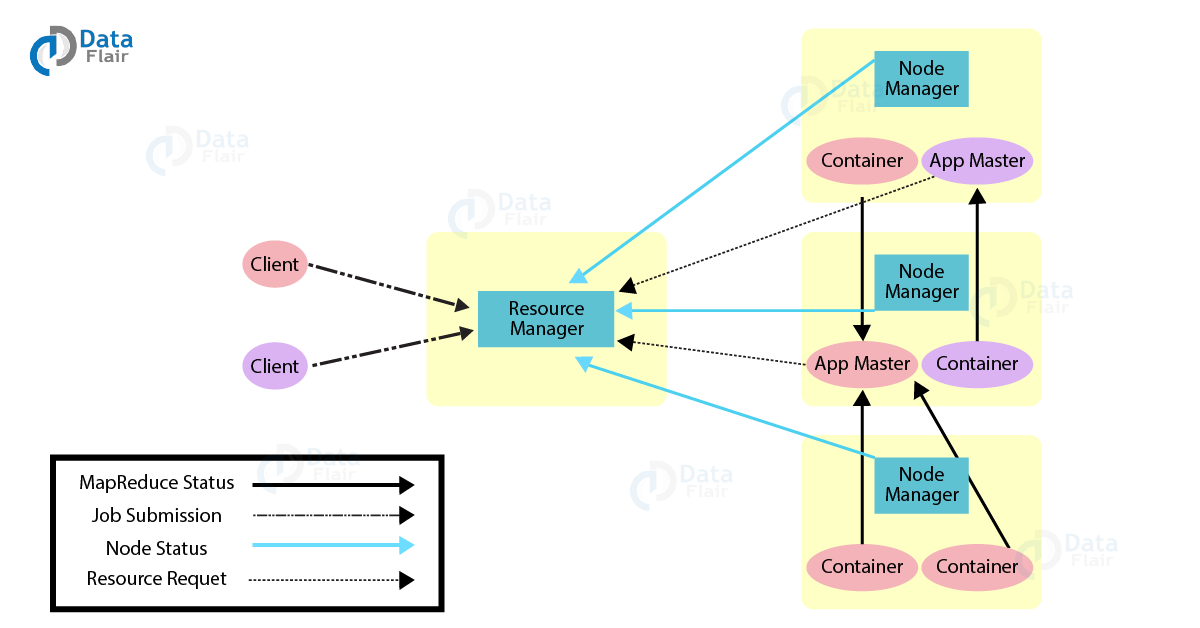
Yarn :是一个资源管理系统,其作用就是把资源管理和任务调度/监控功分割成不同的进程,Yarn 有一个全局的资源管理器叫 ResourceManager,每个 application 都有一个 ApplicationMaster 进程。一个 application 可能是一个单独的 job 或者是 job 的 DAG (有向无环图)。
在 Yarn 内部有两个守护进程:
- ResourceManager :负责给 application 分配资源
- NodeManager :负责监控容器使用资源情况,并把资源使用情况报告给 ResourceManager。这里所说的资源一般是指CPU、内存、磁盘、网络等。
ApplicationMaster 负责从 ResourceManager 申请资源,并与 NodeManager 一起对任务做持续监控工作。
Yarn 具有下面这些特性:
- 多租户:Yarn允许在同样的 Hadoop数据集使用多种访问引擎。这些访问引擎可能是批处理,实时处理,迭代处理等;
- 集群利用率:在资源自动分配的情况下,跟早期的Hadoop 版本相比,Yarn拥有更高的集群利用率;
- 可扩展性:Yarn可以根据实际需求扩展到几千个节点,多个独立的集群可以联结成一个更大的集群;
- 兼容性:Hadoop 1.x 的 MapReduce 应用程序可以不做任何改动运行在 Yarn集群上面。
2.4 Hadoop工作方式
2.4.1 Hadoop的主从工作方式
Hadoop 以主从的方式工作(如下图):
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









