







不完全观测问题
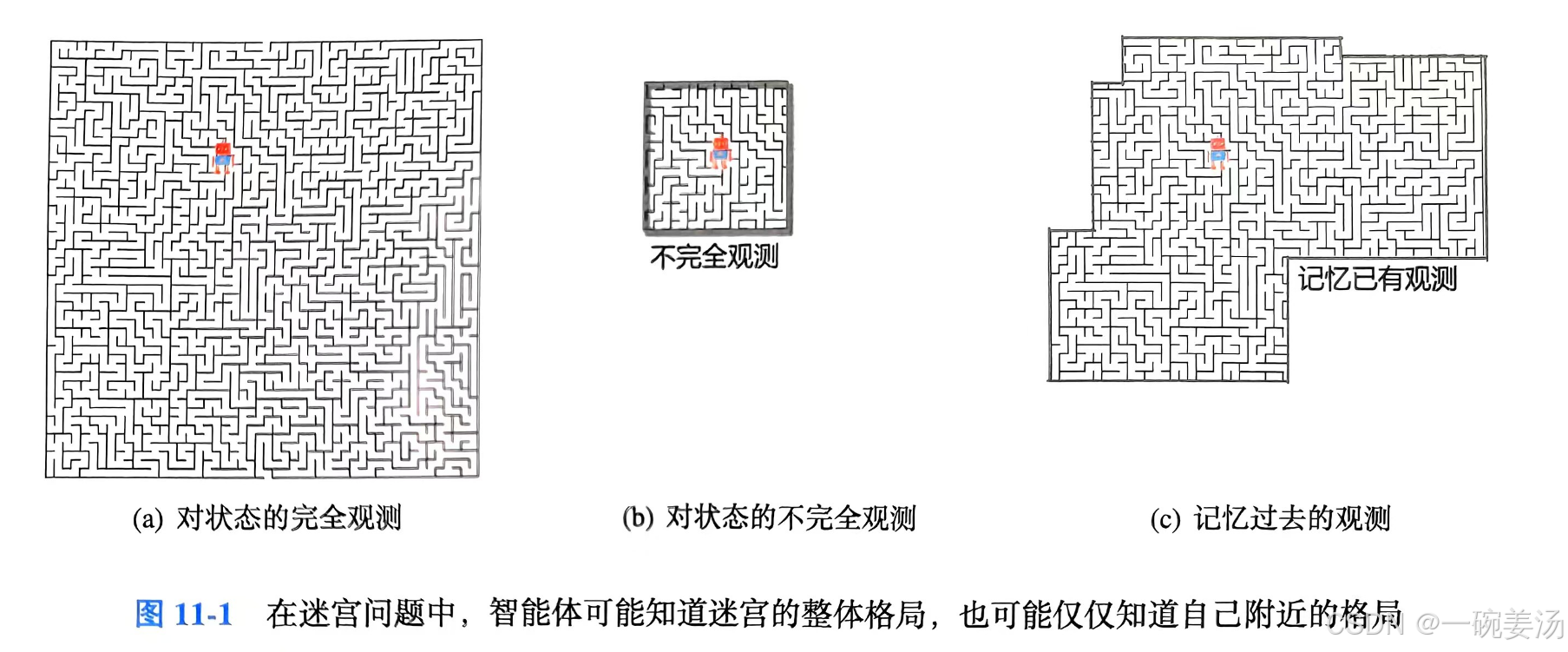
对于类似迷宫这样的不完全观测的强化学习问题,应当记忆过去的观测,用所有已知的信息做决策:
π
(
a
t
∣
o
1
:
t
;
θ
)
\pi(a_t|\mathbf o_{1:t};\theta)
π(at∣o1:t;θ)其中,
o
1
:
t
=
[
o
1
,
o
2
,
.
.
.
,
o
t
]
\mathbf o_{1:t}=[o_1,o_2,...,o_t]
o1:t=[o1,o2,...,ot]为从初始到t时刻为止的观测。
基于RNN的策略网络
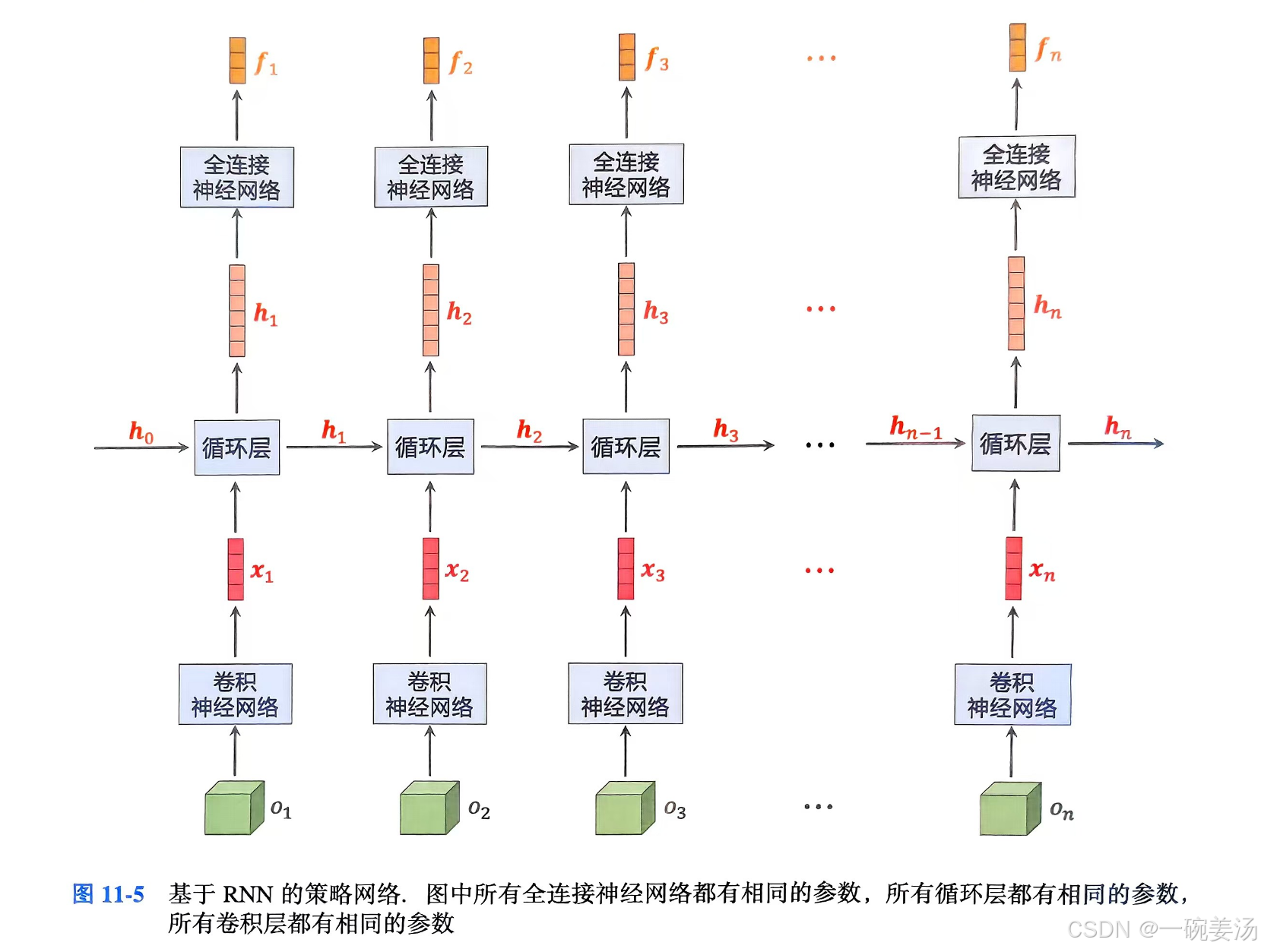
图中的
f
t
=
π
(
a
t
∣
o
1
:
t
;
θ
)
f_t=\pi(a_t|\mathbf o_{1:t};\theta)
ft=π(at∣o1:t;θ),将卷积层、全连接层与循环层结合,这样就能处理不固定长度的输入了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









