







目录
二.Latency原因分析与序列化的dynamicbatch
三、使用dynamicbatch进行engine本地序列化的转换命令
十二.CmakeLists(TensorRT_ROOT&&TensorRT_LIB_ROOT 需要修改 )
一.硬件信息与infer速度
-
jtop
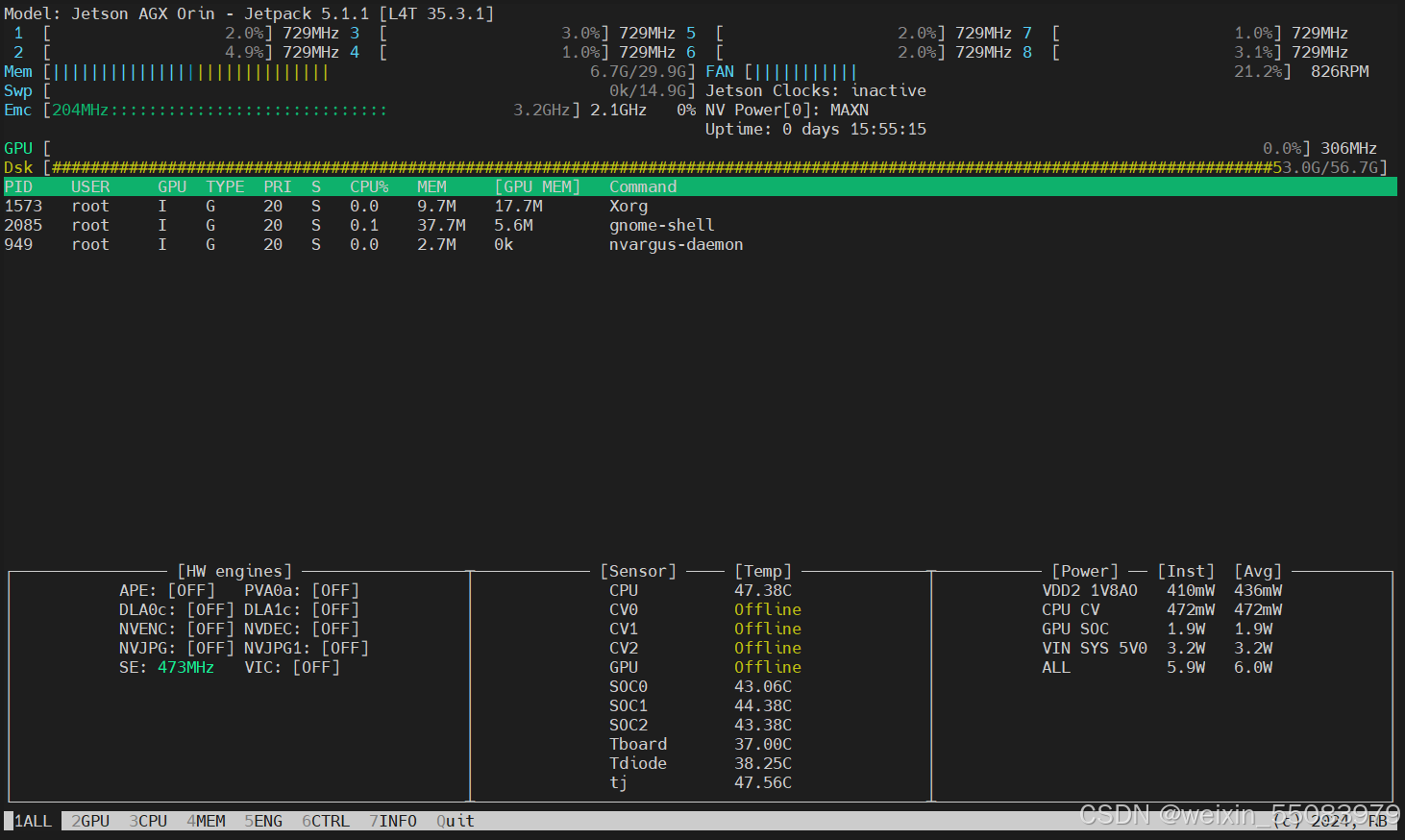
- jetson docker version
agx@ubuntu:~$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5146d15378b3 nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3 "/bin/bash" 5 months ago Up 39 hours nvpy - cuda+ tesorrt infer speed
#include "utils.h" #include "yolov8.h" //trtexec --onnx=yolov8m.onnx --saveEngine=yolov8m_f16.trt --buildOnly --minShapes=images:1x3x640x640 --optShapes=images:4x3x640x640 --maxShapes=images:8x3x640x640 --fp16 void init_param(utils::Param& param){ param.batch = 8; param.topK = 300; param.num_class = 80; param.pad_value = 114.f; param.src_h = 1080; param.src_w = 1920; param.dst_h = 640; param.dst_w = 640; param.engine_dir = "/home/xk/cv/04_exercise/02yolov8_cuda_all/TensorRT-YOLOV8/yolov8s_fp16.trt"; }root@ubuntu:/datas/xk/02code/yolov8-tensor-rt-cuda/build# ./cuda_example [03/08/2025-09:06:27] [I] [TRT] Loaded engine size: 23 MiB [03/08/2025-09:06:29] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +618, GPU +959, now: CPU 918, GPU 9694 (MiB) [03/08/2025-09:06:29] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +21, now: CPU 0, GPU 21 (MiB) [03/08/2025-09:06:29] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +1, GPU +6, now: CPU 919, GPU 9696 (MiB) [03/08/2025-09:06:29] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +137, now: CPU 0, GPU 158 (MiB) Successfully load the engine to TensorRT !!! [03/08/2025-09:06:29] [I] The TensorRT Engine's info: [03/08/2025-09:06:29] [I] idx = 0, images: -1, 3, 640, 640, [03/08/2025-09:06:29] [I] idx = 1, output0: -1, 84, 8400, [03/08/2025-09:06:29] [I] the context's info: [03/08/2025-09:06:29] [I] idx = 0, images: 8, 3, 640, 640, [03/08/2025-09:06:29] [I] idx = 1, output0: 8, 84, 8400, successfully init the vs!!! FPS: 7.999617 CUDA_Prepocess 1.910332 TenosrRT 122.465858 CUDA_Postpocess 0.629796 FPS: 187.625000 CUDA_Prepocess 0.820068 TenosrRT 3.961664 CUDA_Postpocess 0.548048 FPS: 192.379608 CUDA_Prepocess 0.813188 TenosrRT 3.836440 CUDA_Postpocess 0.548428 FPS: 194.519226 CUDA_Prepocess 0.810808 TenosrRT 3.781168 CUDA_Postpocess 0.548904 FPS: 189.270035 CUDA_Prepocess 0.810988 TenosrRT 3.921396 CUDA_Postpocess 0.551072 FPS: 192.964508 CUDA_Prepocess 0.809696 TenosrRT 3.833708 CUDA_Postpocess 0.538896 FPS: 192.795456 CUDA_Prepocess 0.809496 TenosrRT 3.835448 CUDA_Postpocess 0.541900 FPS: 188.080521 CUDA_Prepocess 0.812324 TenosrRT 3.959956 CUDA_Postpocess 0.544592 FPS: 192.944275 CUDA_Prepocess 0.809480 TenosrRT 3.831240 CUDA_Postpocess 0.542124 FPS: 183.228180 CUDA_Prepocess 0.810724 TenosrRT 4.072064 CUDA_Postpocess 0.574888 FPS: 176.897095 CUDA_Prepocess 0.811472 TenosrRT 3.979328 CUDA_Postpocess 0.862204 FPS: 194.589935 CUDA_Prepocess 0.810948 TenosrRT 3.799532 CUDA_Postpocess 0.528532 FPS: 193.144165 CUDA_Prepocess 0.809972 TenosrRT 3.844344 CUDA_Postpocess 0.523164 FPS: 188.065643 CUDA_Prepocess 0.808708 TenosrRT 3.980308 CUDA_Postpocess 0.528276 FPS: 187.749146 CUDA_Prepocess 0.813944 TenosrRT 3.990252 CUDA_Postpocess 0.522060 FPS: 193.512985 CUDA_Prepocess 0.810192 TenosrRT 3.838820 CUDA_Postpocess 0.518600 FPS: 188.101746 CUDA_Prepocess 0.809632 TenosrRT 3.981472 CUDA_Postpocess 0.525168 FPS: 192.530289 CUDA_Prepocess 0.809316 TenosrRT 3.846072 CUDA_Postpocess 0.538600 FPS: 193.276321 CUDA_Prepocess 0.811428 TenosrRT 3.831804 CUDA_Postpocess 0.530708 FPS: 187.536484 CUDA_Prepocess 0.809540 TenosrRT 3.961128 CUDA_Postpocess 0.561628 FPS: 192.401962 CUDA_Prepocess 0.809028 TenosrRT 3.828576 CUDA_Postpocess 0.559848 FPS: 191.462616 CUDA_Prepocess 0.811872 TenosrRT 3.858800 CUDA_Postpocess 0.552280 FPS: 188.229904 CUDA_Prepocess 0.811792 TenosrRT 3.959564 CUDA_Postpocess 0.541296 FPS: 192.966003 CUDA_Prepocess 0.811204 TenosrRT 3.836944 CUDA_Postpocess 0.534112 FPS: 192.735870 CUDA_Prepocess 0.810276 TenosrRT 3.838808 CUDA_Postpocess 0.539364 FPS: 185.220718 CUDA_Prepocess 0.809648 TenosrRT 3.960644 CUDA_Postpocess 0.628672 FPS: 191.945053 CUDA_Prepocess 0.810692 TenosrRT 3.872168 CUDA_Postpocess 0.526964 FPS: 192.214966 CUDA_Prepocess 0.810484 TenosrRT 3.835004 CUDA_Postpocess 0.557020 FPS: 187.548019 CUDA_Prepocess 0.811080 TenosrRT 3.957496 CUDA_Postpocess 0.563392 FPS: 192.206100 CUDA_Prepocess 0.810212 TenosrRT 3.834856 CUDA_Postpocess 0.557680 FPS: 192.576996 CUDA_Prepocess 0.811196 TenosrRT 3.837880 CUDA_Postpocess 0.543652 FPS: 188.662720 CUDA_Prepocess 0.811312 TenosrRT 3.957840 CUDA_Postpocess 0.531312 FPS: 193.167435 CUDA_Prepocess 0.810468 TenosrRT 3.834080 CUDA_Postpocess 0.532308 FPS: 192.700638 CUDA_Prepocess 0.809360 TenosrRT 3.842912 CUDA_Postpocess 0.537124 FPS: 185.663361 CUDA_Prepocess 0.810088 TenosrRT 4.053344 CUDA_Postpocess 0.522660 FPS: 192.351181 CUDA_Prepocess 0.810056 TenosrRT 3.831056 CUDA_Postpocess 0.557712 FPS: 192.145844 CUDA_Prepocess 0.811304 TenosrRT 3.837364 CUDA_Postpocess 0.555712 FPS: 188.554718 CUDA_Prepocess 0.809232 TenosrRT 3.954508 CUDA_Postpocess 0.539760 FPS: 192.361847 CUDA_Prepocess 0.811044 TenosrRT 3.855180 CUDA_Postpocess 0.532312 FPS: 192.710159 CUDA_Prepocess 0.809512 TenosrRT 3.842344 CUDA_Postpocess 0.537284 FPS: 187.484879 CUDA_Prepocess 0.809968 TenosrRT 3.960996 CUDA_Postpocess 0.562800 FPS: 192.768555 CUDA_Prepocess 0.808908 TenosrRT 3.842792 CUDA_Postpocess 0.535868 FPS: 193.135941 CUDA_Prepocess 0.810624 TenosrRT 3.837596 CUDA_Postpocess 0.529480 FPS: 186.589874 CUDA_Prepocess 0.810096 TenosrRT 4.014928 CUDA_Postpocess 0.534324 FPS: 193.618195 CUDA_Prepocess 0.807972 TenosrRT 3.833064 CUDA_Postpocess 0.523768 FPS: 210.187180 CUDA_Prepocess 0.724216 TenosrRT 3.577020 CUDA_Postpocess 0.456428 FPS: 208.015427 CUDA_Prepocess 0.724208 TenosrRT 3.664212 CUDA_Postpocess 0.418916 FPS: 211.268021 CUDA_Prepocess 0.724848 TenosrRT 3.574580 CUDA_Postpocess 0.433896 FPS: 211.013382 CUDA_Prepocess 0.725344 TenosrRT 3.580028 CUDA_Postpocess 0.433664 FPS: 210.250641 CUDA_Prepocess 0.725456 TenosrRT 3.586636 CUDA_Postpocess 0.444136 FPS: 210.529846 CUDA_Prepocess 0.721748 TenosrRT 3.579600 CUDA_Postpocess 0.448572 FPS: 210.470474 CUDA_Prepocess 0.722056 TenosrRT 3.578768 CUDA_Postpocess 0.450436 FPS: 210.276642 CUDA_Prepocess 0.721644 TenosrRT 3.590724 CUDA_Postpocess 0.443272
二.Latency原因分析与序列化的dynamicbatch
1.使用cuda重写模型前后处理,使用tensorrt推理模型,全过程pipline在GPU上运行,大大降低了由于模型前后处理在cpu运算,以及数据从host 拷贝到device,从device拷贝到host带来的时间消耗。
三、使用dynamicbatch进行engine本地序列化的转换命令
root@ubuntu:/datas/xk/02code/yolov8-tensor-rt-cuda# /usr/src/tensorrt/bin/trtexec --onnx=yolov8m.onnx --saveEngine=yolov8m_f16.trt --buildOnly --minShapes=images:1x3x640x640 --optShapes=images:4x3x640
x640 --maxShapes=images:8x3x640x640 --fp16
&&&& RUNNING TensorRT.trtexec [TensorRT v8502] # /usr/src/tensorrt/bin/trtexec --onnx=yolov8m.onnx --saveEngine=yolov8m_f16.trt --buildOnly --minShapes=images:1x3x640x640 --optShapes=images:4x3x640x640 --maxShapes=images:8x3x640x640 --fp16
[03/08/2025-08:32:16] [I] === Model Options ===
[03/08/2025-08:32:16] [I] Format: ONNX
[03/08/2025-08:32:16] [I] Model: yolov8m.onnx
[03/08/2025-08:32:16] [I] Output:
[03/08/2025-08:32:16] [I] === Build Options ===
[03/08/2025-08:32:16] [I] Max batch: explicit batch
[03/08/2025-08:32:16] [I] Memory Pools: workspace: default, dlaSRAM: default, dlaLocalDRAM: default, dlaGlobalDRAM: default
[03/08/2025-08:32:16] [I] minTiming: 1
[03/08/2025-08:32:16] [I] avgTiming: 8
[03/08/2025-08:32:16] [I] Precision: FP32+FP16四.Pipline中yolov8类构造函数
YOLOV8::YOLOV8(utils::Param param){
this->param = param;
this->get_martrix_dst2src();
this->load_engine();
bool status = this->load_tensorrt();
if(not status){
cout<<"Fall to load the engine to TensorRT !!!"<<endl;
}
else{
cout<<"Successfully load the engine to TensorRT !!!"<<endl;
}
this->check_tensorrt();
this->memrymalloc();
}五.Pipline中Warpaffine仿射变换矩阵
void YOLOV8::get_martrix_dst2src(){
float scale0 = (float)param.dst_h/param.src_h;
float scale1 = (float)param.dst_w/param.src_w;
float warp_scale = min(scale0,scale1);
cv::Mat src2dstmat = (cv::Mat_<float>(2,3,CV_32FC1)<<
warp_scale,0,0.5*(param.dst_w-param.src_w*warp_scale + warp_scale -1),
0,warp_scale,0.5*(param.dst_h-param.src_h*warp_scale + warp_scale -1));
cv::Mat dst2srcmat = cv::Mat::zeros(2,3,CV_32FC1);
cv::invertAffineTransform(src2dstmat,dst2srcmat);
//1.使用 mat默认访存api
/*
Matrix_dst2src.v0 = dst2srcmat.at<float>(0,0);
Matrix_dst2src.v1 = dst2srcmat.at<float>(0,1);
Matrix_dst2src.v2 = dst2srcmat.at<float>(0,2);
Matrix_dst2src.v3 = dst2srcmat.at<float>(1,0);
Matrix_dst2src.v4 = dst2srcmat.at<float>(1,1);
Matrix_dst2src.v5 = dst2srcmat.at<float>(1,2);
*/
//2.使用指针访问
Matrix_dst2src.v0 = dst2srcmat.ptr<float>(0)[0];
Matrix_dst2src.v1 = dst2srcmat.ptr<float>(0)[1];
Matrix_dst2src.v2 = dst2srcmat.ptr<float>(0)[2];
Matrix_dst2src.v3 = dst2srcmat.ptr<float>(1)[0];
Matrix_dst2src.v4 = dst2srcmat.ptr<float>(1)[1];
Matrix_dst2src.v5 = dst2srcmat.ptr<float>(1)[2];
}六.Pipline中TensorRT模型的加载
void YOLOV8::load_engine(){
// load the engine data
ifstream in(this->param.engine_dir,ios::in|ios::binary);
if(!in.is_open()){
this->engine_data = {};
}
in.seekg(0,ios::end);
size_t length = in.tellg();
if(length>0){
in.seekg(0,ios::beg);
this->engine_data.resize(length);
in.read((char*)this->engine_data.data(),length);
}
in.close();
}
// int tensorrt model
bool YOLOV8::load_tensorrt(){
//如果engine data为空加载失败
if(this->engine_data.empty()) return false;
this->trt_runtime = unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if(trt_runtime==nullptr) return false;
this->cuda_engine = unique_ptr<nvinfer1::ICudaEngine>(trt_runtime->deserializeCudaEngine(engine_data.data(),engine_data.size()));
if(cuda_engine==nullptr) return false;
this->executioncontext = unique_ptr<nvinfer1::IExecutionContext>(this->cuda_engine->createExecutionContext());
if(executioncontext==nullptr) return false;
if(param.dynamicbatch){
this->executioncontext->setBindingDimensions(0,nvinfer1::Dims4(param.batch,3,param.dst_h,param.dst_w));
}
this->infer_out_dims = this->executioncontext->getBindingDimensions(1);
// N,class+4,8400
this->object_num = infer_out_dims.d[2];
this->object_len = infer_out_dims.d[1];
return true;
}七.Pipline中的CPU&&GPU内存分配
void YOLOV8::memrymalloc(){
Check_Cuda_Runtime(cudaMalloc(&imgs,param.batch*param.src_h*param.src_w*3*sizeof(unsigned char)));
Check_Cuda_Runtime(cudaMalloc(&img_resized,param.batch*param.dst_h*param.dst_w*3*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&img_rgb,param.batch*param.dst_h*param.dst_w*3*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&img_normed,param.batch*param.dst_h*param.dst_w*3*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&img_nchw,param.batch*param.dst_h*param.dst_w*3*sizeof(float)));
// Check_Cuda_Runtime(cudaMallocHost(&img_nchw_host,param.batch*param.dst_h*param.dst_w*3*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&box_infered,param.batch*object_len*object_num*sizeof(float)));
// Check_Cuda_Runtime(cudaMallocHost(&box_infered_host,param.batch*object_len*object_num*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&box_tranposed,param.batch*object_num*object_len*sizeof(float)));
// Check_Cuda_Runtime(cudaMallocHost(&box_tranposed_host,param.batch*object_num*object_len*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&box_decodered_nms_sorted,param.batch*(1+param.topK*param.box_len)*sizeof(float)));
Check_Cuda_Runtime(cudaMallocHost(&box_decodered_nms_sorted_host,param.batch*(1+param.topK*param.box_len)*sizeof(float)));
Check_Cuda_Runtime(cudaMalloc(&nms_idx,param.batch*param.topK*sizeof(int)));
// Check_Cuda_Runtime(cudaMallocHost(&nms_idx_host,param.batch*param.topK*sizeof(int)));
Check_Cuda_Runtime(cudaMalloc(&nms_conf,param.batch*param.topK*sizeof(float)));
// Check_Cuda_Runtime(cudaMallocHost(&nms_conf_host,param.batch*param.topK*sizeof(float)));
boxes_final.resize(param.batch);
}八.Pipline中的多batch加载与模型前处理
bool YOLOV8::tobatch(cv::Mat& img){
img_batch.push_back(img);
if(img_batch.size()<param.batch){
return false;
}
else{
for(int i=0;i<img_batch.size();++i){
Check_Cuda_Runtime(cudaMemcpy(&imgs[i*param.src_h*param.src_w*3],img_batch[i].data,param.src_h*param.src_w*3*sizeof(unsigned char),cudaMemcpyHostToDevice));
}
return true;
}
}void YOLOV8::preprocess(){
resize_padding_device(param,imgs,img_resized,Matrix_dst2src);
bgr2rgb_device(param,img_resized,img_rgb);
normlize_device(param,img_rgb,img_normed);
nhwc2nchw_device(param,img_normed,img_nchw);
// Check_Cuda_Runtime(cudaMemcpy(img_nchw_host,img_nchw,param.batch*param.dst_h*param.dst_w*3*sizeof(float),cudaMemcpyDeviceToHost));
}九.Pipline的TensorRT模型推理
bool YOLOV8::infer(){
float* bindings[] = {img_nchw,box_infered};
bool context = this->executioncontext->executeV2((void**)bindings);
return context;
}十.Pipline的模型后处理
void YOLOV8::postprocess(){
// Check_Cuda_Runtime(cudaMemcpy(box_infered_host,box_infered,param.batch*object_len*object_num*sizeof(float),cudaMemcpyDeviceToHost));
transpose_device(param,box_infered,box_tranposed,object_num,object_len);
// Check_Cuda_Runtime(cudaMemcpy(box_tranposed_host,box_tranposed,param.batch*(1+param.topK*param.box_len)*sizeof(float),cudaMemcpyDeviceToHost));
decode_device(param,box_tranposed,box_decodered_nms_sorted,object_num,object_len,param.topK,param.box_len);
// Check_Cuda_Runtime(cudaMemcpy(box_decodered_nms_sorted_host,box_decodered_nms_sorted,param.batch*(1+param.topK*param.box_len)*sizeof(float),cudaMemcpyDeviceToHost));
nms_sort_device(param,box_decodered_nms_sorted,(1+param.topK*param.box_len),param.box_len,nms_idx,nms_conf);
Check_Cuda_Runtime(cudaMemcpy(box_decodered_nms_sorted_host,box_decodered_nms_sorted,param.batch*(1+param.topK*param.box_len)*sizeof(float),cudaMemcpyDeviceToHost));
// Check_Cuda_Runtime(cudaMemcpy(nms_conf_host,nms_conf,param.batch*param.topK*sizeof(float),cudaMemcpyDeviceToHost));
// Check_Cuda_Runtime(cudaMemcpy(nms_idx_host,nms_idx,param.batch*param.topK*sizeof(int),cudaMemcpyDeviceToHost));
filter_boxes(param,box_decodered_nms_sorted_host,Matrix_dst2src,boxes_final);
}十一.Pipline中的batch结果清除与内存指针释放
void YOLOV8::reset(){
Check_Cuda_Runtime(cudaMemset(box_decodered_nms_sorted,0,param.batch*(1+param.topK*param.box_len)*sizeof(float)));
img_batch.clear();
for(int i=0;i<param.batch;++i){
this->boxes_final[i].clear();
}
}
YOLOV8::~YOLOV8(){
Check_Cuda_Runtime(cudaFree(imgs));
Check_Cuda_Runtime(cudaFree(img_resized));
Check_Cuda_Runtime(cudaFree(img_rgb));
Check_Cuda_Runtime(cudaFree(img_normed));
Check_Cuda_Runtime(cudaFree(img_nchw));
Check_Cuda_Runtime(cudaFree(box_infered));
Check_Cuda_Runtime(cudaFree(box_tranposed));
Check_Cuda_Runtime(cudaFree(box_decodered_nms_sorted));
Check_Cuda_Runtime(cudaFreeHost(box_decodered_nms_sorted_host));
Check_Cuda_Runtime(cudaFree(nms_idx));
Check_Cuda_Runtime(cudaFree(nms_conf));
}十二.CmakeLists(TensorRT_ROOT&&TensorRT_LIB_ROOT 需要修改 )
cmake_minimum_required(VERSION 3.10)
set(CMAKE_BUILD_TYPE "Debug")
# set(CMAKE_BUILD_TYPE "Release")
set(TensorRT_ROOT /usr/src/tensorrt)
set(TensorRT_LIB_ROOT /usr/lib/aarch64-linux-gnu)
PROJECT(cuda_example VERSION 1.0.0 LANGUAGES C CXX CUDA)
file(GLOB SOURCE_FILE
${CMAKE_CURRENT_SOURCE_DIR}/main.cpp
${CMAKE_CURRENT_SOURCE_DIR}/src/*.cpp
${CMAKE_CURRENT_SOURCE_DIR}/src/*.cu
# ${CMAKE_CURRENT_SOURCE_DIR}/utils/*.cu
# ${CMAKE_CURRENT_SOURCE_DIR}/utils/*.cpp
${TensorRT_ROOT}/samples/common/logger.cpp
${TensorRT_ROOT}/samples/common/sampleOptions.cpp
${TensorRT_ROOT}/samples/common/sampleUtils.cpp
)
find_package(OpenCV REQUIRED)
find_package(CUDA REQUIRED)
include_directories(
${OpenCV_INCLUDE_DIRS}
${CMAKE_CURRENT_SOURCE_DIR}
${CUDA_INCLUDE_DIRS}
${TensorRT_ROOT}/include
${TensorRT_ROOT}/samples/common
# ${CMAKE_CURRENT_SOURCE_DIR}/utils
${CMAKE_CURRENT_SOURCE_DIR}/include
)
add_executable(cuda_example ${SOURCE_FILE} )
set_property(TARGET ${PROJECT_NAME} PROPERTY CUDA_ARCHITECTURES 80)
# target_compile_options(${PROJECT_NAME} PUBLIC
# $<$<COMPILE_LANGUAGE:CUDA>:--default-stream per-thread -lineinfo; --use_fast_math --disable-warnings>)
target_link_libraries(cuda_example ${OpenCV_LIBS} ${CUDA_LIBRATIES} ${CUDA_CUDART_LIBRARY} ${TensorRT_LIB_ROOT}/libnvinfer.so ${TensorRT_LIB_ROOT}/libnvinfer_plugin.so)
# 手动指定 CUDA 驱动库路径
set(CUDA_DRIVER_LIBRARY /usr/local/cuda/lib64/stubs/libcuda.so)
if (EXISTS ${CUDA_DRIVER_LIBRARY})
target_link_libraries(cuda_example ${CUDA_DRIVER_LIBRARY})
else()
message(FATAL_ERROR "CUDA driver library ${CUDA_DRIVER_LIBRARY} not found.")
endif()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









