







目录
三.Fuse_Resize_Pad_Bgr2rgb算子实现与launch函数实现
四.floatptr2cvimg将多batch浮点数指针,转成UINT8格式本地存储
五.OpenCV-Resize_Pad_Bgr2rgb算子实现(待实验)
六.CPU-Fuse_Resize_Pad_Bgr2rgb算子实现(待实验)
一.算子原理
1.仿射变换与放射变换矩阵
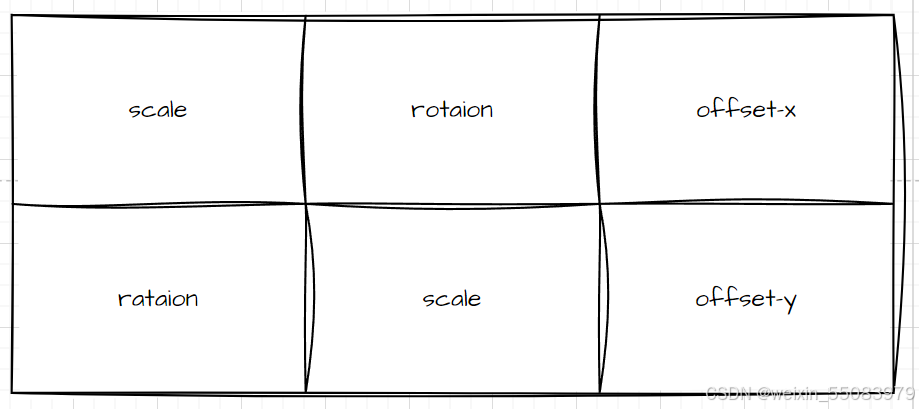
仿射变换矩阵: matrix_src2dst,两行三列;scale是缩放比例,rotaion是旋转角度,offset是偏移值;
scale = min(dst_w/src-w,dst_h/src_h);
rotaion = 0;
offset_x = 0.5*(dst_w-src_w*scale+scale-1);
offset_y = 0.5*(dst_y-src_y*scale+scale-1);
2.放射变换逆矩阵: matrix_dst2src;通过求逆矩阵得到
param.src_h = img.rows;
param.src_w = img.cols;
float scale = std::min(param.dst_h/(float)param.src_h, param.dst_w/float(param.src_w));
float offset_x = 0.5*(param.dst_w-param.src_w*scale+scale-1);
float offset_y = 0.5*(param.dst_h-param.src_h*scale+scale-1);
src2dstmat = (cv::Mat_<float>(2,3,CV_32FC1)<<scale,0,offset_x,0,scale,offset_y);
cv::invertAffineTransform(src2dstmat,dst2srcmat);
matrix_dst2src.v0 = dst2srcmat.ptr<float>(0)[0];
matrix_dst2src.v1 = dst2srcmat.ptr<float>(0)[1];
matrix_dst2src.v2 = dst2srcmat.ptr<float>(0)[2];
matrix_dst2src.v3 = dst2srcmat.ptr<float>(1)[0];
matrix_dst2src.v4 = dst2srcmat.ptr<float>(1)[1];
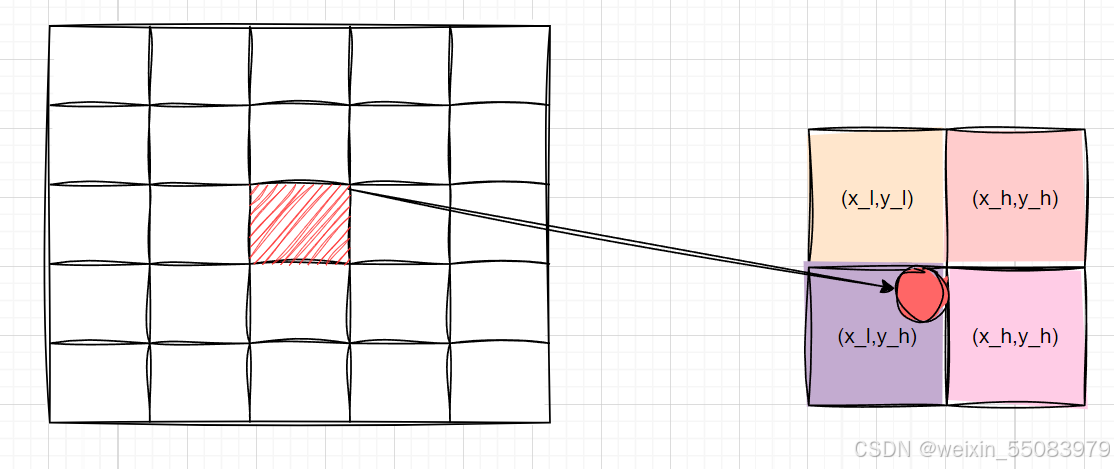
matrix_dst2src.v5 = dst2srcmat.ptr<float>(1)[2];3.在cuda核函数里面通过遍历dst每一个位置,通过matrix_dst2src 仿射变换计算该位置在src源图像的位置;此时的位置是一个浮点数结果,需要通过双线性插值计算目标点的值。
双线性插值的数学公式可以表示为:
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0]);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1]);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2]);4.权重计算公式
/*
w4 w3
w2 w1
v1 v2
v3 v4
*/
float w1 = hy*hx;
float w2 = hy*lx;
float w3 = ly*hx;
float w4 = ly*lx;5.最邻近四个元素的指针计算
if (y_low>=0)
{
if (x_low >= 0)
{
v1 = input_src_device + dy * src_volume + src_w * y_low * 3 + x_low * 3;
}
if (x_high < src_w)
{
v2 = input_src_device + dy * src_volume + src_w * y_low * 3 + x_high * 3;
}
}
// v3 v4 通过 y_high绑定。constrain之后 y_high->[1,src_y-1]
if (y_high<src_h)
{
if (x_low >= 0)
{
v3 = input_src_device + dy * src_volume + src_w * y_high * 3 + x_low * 3;
}
if (x_high<src_w)
{
v4 = input_src_device + dy * src_volume + src_w * y_high * 3 + x_high * 3;
}
}
6.最终结果:超出src原图像尺寸范围的就默认pad_value填充(小tip这里如果c2与c0换一下位置是不是就是bgr2rgb)
float* pdst = resize_dst + dy * dst_volume + dst_w * dst_y * 3 + dst_x * 3 ;
pdst[0] = c0;
pdst[1] = c1;
pdst[2] = c2;二.dynamicbatch infer动态batch推理
推理前,声明指针-->根据超参数batch分配显存-->将cv::Mat指针数据拷贝到device
for(int i=0;i<param.batch;++i){
cudaMemcpy(batch_imgs+i*param.src_w*param.src_h*3,img.data,
param.src_w*param.src_h*3*sizeof(unsigned char),cudaMemcpyHostToDevice);
}三.Fuse_Resize_Pad_Bgr2rgb算子实现与launch函数实现
void launch_cuda_resize_padding(tools::Param param, unsigned char* intput_src_device,float* resize_dst,const tools::AffineMatrix dst2src)
{
dim3 block_size(param.BLOCK_SIZE,param.BLOCK_SIZE);
dim3 grid_size((param.dst_w*param.dst_h + param.BLOCK_SIZE -1)/param.BLOCK_SIZE,
(param.BLOCK_SIZE + param.BLOCK_SIZE -1)/param.BLOCK_SIZE);
int batch_size = param.batch;
float pad_value = param.pad_value;
int src_w = param.src_w;
int src_h = param.src_h;
int src_volume = src_w * src_h * 3;
int dst_w = param.dst_w;
int dst_h = param.dst_h;
int dst_volume = dst_w * dst_h * 3;
int dst_area = dst_w * dst_h;
resize_padding_device_kernel<<<grid_size,block_size, 0, nullptr>>>(intput_src_device,src_volume,src_w,src_h,resize_dst,dst_volume,dst_area,dst_w,dst_h,dst2src,batch_size,pad_value);
}__device__ void affine_project_device_kernel(tools::AffineMatrix* dst2src,int dst_x,int dst_y, float* cal_src_x,float* cal_src_y)
{
*cal_src_x = dst2src->v0 * dst_x + dst2src->v1*dst_y + dst2src->v2;
*cal_src_y = dst2src->v3*dst_x + dst2src->v4*dst_y + dst2src->v5;
}
__global__ void resize_padding_device_kernel(unsigned char* input_src_device,int src_volume,int src_w,int src_h,float* resize_dst,int dst_volume,
int dst_area,int dst_w,int dst_h,tools::AffineMatrix dst2src,int batch_size,float pad_value)
{
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx < dst_area && dy<batch_size)
{
int dst_y = dx / dst_w;
int dst_x = dx % dst_w;
float cal_src_x = 0;
float cal_src_y = 0;
// 根据dst的(x,y)结合 affinemat--> 获取 src的 (x0,y0)
affine_project_device_kernel(&dst2src,dst_x,dst_y,&cal_src_x,&cal_src_y);
// 计算每一个dst(x,y)位置的三通道像素值
float c0 = pad_value;
float c1 = pad_value;
float c2 = pad_value;
// 如果索引越界了就填充默认值
if(cal_src_x<-1 || cal_src_x>=src_w || cal_src_y<-1 || cal_src_y>=src_h)
{
}
else
{
/*
cal_src_x: [0,src_x-1]
x_low-->[-1,src_x-1]
x_high-->[1,src_x]
cal_src_y: [0,src_y-1]
y_low-->[-1,src_y-1]
y_high-->[1,src_y]
*/
int x_low = floor(cal_src_x);
int y_low = floor(cal_src_y);
int x_high = x_low + 1;
int y_high = y_low + 1;
/*
x_low,y_low
src_x,src_y
x_high,y_high
*/
unsigned char const_values[] = {(unsigned char)pad_value,(unsigned char)pad_value,(unsigned char)pad_value};
float lx = cal_src_x - x_low;
float ly = cal_src_y - y_low;
float hx = x_high - cal_src_x;
float hy = y_high - cal_src_y;
/*
w4 w3
w2 w1
v1 v2
v3 v4
*/
float w1 = hy*hx;
float w2 = hy*lx;
float w3 = ly*hx;
float w4 = ly*lx;
unsigned char* v1 = const_values;
unsigned char* v2 = const_values;
unsigned char* v3 = const_values;
unsigned char* v4 = const_values;
//双线性插值索引越界就用默认常量值。constrain之后 y_low->[0,src_y-1]
// v1 v2通过y_low绑定
if (y_low>=0)
{
if (x_low >= 0)
{
v1 = input_src_device + dy * src_volume + src_w * y_low * 3 + x_low * 3;
}
if (x_high < src_w)
{
v2 = input_src_device + dy * src_volume + src_w * y_low * 3 + x_high * 3;
}
}
// v3 v4 通过 y_high绑定。constrain之后 y_high->[1,src_y-1]
if (y_high<src_h)
{
if (x_low >= 0)
{
v3 = input_src_device + dy * src_volume + src_w * y_high * 3 + x_low * 3;
}
if (x_high<src_w)
{
v4 = input_src_device + dy * src_volume + src_w * y_high * 3 + x_high * 3;
}
}
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0]);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1]);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2]);
}
float* pdst = resize_dst + dy * dst_volume + dst_w * dst_y * 3 + dst_x * 3 ;
pdst[0] = c0;
pdst[1] = c1;
pdst[2] = c2;
}
}四.floatptr2cvimg将多batch浮点数指针,转成UINT8格式本地存储
std::vector<cv::Mat> floatptr2cvmat(tools::Param param,float* imgptr){
std::vector<cv::Mat> img_list;
for(int i=0;i<param.batch;++i){
float* img_data = imgptr+i*param.dst_h*param.dst_w*3;
cv::Mat floatcvimg(param.dst_h,param.dst_w,CV_32FC3,img_data);
cv::Mat uint8cvimg;
floatcvimg.convertTo(uint8cvimg,CV_8UC3);
img_list.push_back(uint8cvimg.clone());
}
return img_list;
}
五.OpenCV-Resize_Pad_Bgr2rgb算子实现(待实验)
cv::Mat img_cpu;
cv::Mat img_cpu_gray(cv::Size(param.dst_w,param.dst_h),CV_8UC3,cv::Scalar(127,127,127));
int target_w = (int)param.src_w*scale;
int target_h = (int)param.src_h*scale;
// offset_x = (param.dst_h-target_h)/2;
// offset_y = (param.dst_w-target_w)/2;
offset_x = std::max(0, (param.dst_w - target_w) / 2);
offset_y = std::max(0, (param.dst_h - target_h) / 2);
for(int j=0;j<param.epochs;++j){
HostTimer ht0;
cv::resize(img,img_cpu,cv::Size(target_w,target_h),0,0,cv::INTER_LINEAR);
cv::cvtColor(img_cpu,img_cpu,cv::COLOR_BGR2RGB);
img_cpu.copyTo(img_cpu_gray(cv::Rect(offset_x,offset_y,img_cpu.cols,img_cpu.rows)));
float hc1 = ht0.getUsedTime();
printf("cpu opencv const %f ,img_width: %d img_height %d\n",hc1,img.cols,img.rows);
}
cv::imwrite("cpu_rezizepadbgr.jpg",img_cpu_gray);六.CPU-Fuse_Resize_Pad_Bgr2rgb算子实现(待实验)
七.结果图像对比
1.cuda 算子结果:bgr格式与rgb格式


2.OpenCV算法实现结果:bgr格式与rgb格式


八.Latency时延对比(batch=10/100/1000/5000)
1.cuda计算与cv::resizepad的时间对比
batch = 10
epoch 980 cuda op const 0.172054 ,img_width: 750 img_height 563
epoch 981 cuda op const 0.173248 ,img_width: 750 img_height 563
epoch 982 cuda op const 0.170288 ,img_width: 750 img_height 563
epoch 983 cuda op const 0.166989 ,img_width: 750 img_height 563
epoch 984 cuda op const 0.166275 ,img_width: 750 img_height 563
epoch 985 cuda op const 0.169181 ,img_width: 750 img_height 563
epoch 986 cuda op const 0.171242 ,img_width: 750 img_height 563
epoch 987 cuda op const 0.167664 ,img_width: 750 img_height 563
epoch 988 cuda op const 0.169021 ,img_width: 750 img_height 563
epoch 989 cuda op const 0.172352 ,img_width: 750 img_height 563
epoch 990 cuda op const 0.167555 ,img_width: 750 img_height 563
epoch 991 cuda op const 0.174797 ,img_width: 750 img_height 563
epoch 992 cuda op const 0.171424 ,img_width: 750 img_height 563
epoch 993 cuda op const 0.173725 ,img_width: 750 img_height 563
epoch 994 cuda op const 0.169533 ,img_width: 750 img_height 563
epoch 995 cuda op const 0.167475 ,img_width: 750 img_height 563
epoch 996 cuda op const 0.171782 ,img_width: 750 img_height 563
epoch 997 cuda op const 0.172122 ,img_width: 750 img_height 563
epoch 998 cuda op const 0.194198 ,img_width: 750 img_height 563
epoch 999 cuda op const 0.168038 ,img_width: 750 img_height 563
cpu propcess!!
epoch 0 cpu opencv const 5.732247 ,img_width: 750 img_height 563
epoch 1 cpu opencv const 2.152392 ,img_width: 750 img_height 563
epoch 2 cpu opencv const 2.172201 ,img_width: 750 img_height 563
epoch 3 cpu opencv const 1.556902 ,img_width: 750 img_height 563
epoch 4 cpu opencv const 1.726663 ,img_width: 750 img_height 563
epoch 5 cpu opencv const 1.481510 ,img_width: 750 img_height 563
epoch 6 cpu opencv const 1.440997 ,img_width: 750 img_height 563
epoch 7 cpu opencv const 2.039463 ,img_width: 750 img_height 563
epoch 8 cpu opencv const 1.536422 ,img_width: 750 img_height 563
epoch 9 cpu opencv const 1.607238 ,img_width: 750 img_height 563
epoch 10 cpu opencv const 2.025224 ,img_width: 750 img_height 563
epoch 11 cpu opencv const 1.160740 ,img_width: 750 img_height 563
epoch 12 cpu opencv const 1.112708 ,img_width: 750 img_height 563
epoch 13 cpu opencv const 1.817159 ,img_width: 750 img_height 563
epoch 14 cpu opencv const 1.891463 ,img_width: 750 img_height 563
epoch 15 cpu opencv const 1.704038 ,img_width: 750 img_height 563
epoch 16 cpu opencv const 1.128037 ,img_width: 750 img_height 563
epoch 17 cpu opencv const 1.181764 ,img_width: 750 img_height 563
epoch 18 cpu opencv const 1.511142 ,img_width: 750 img_height 563
epoch 19 cpu opencv const 1.718407 ,img_width: 750 img_height 563
epoch 20 cpu opencv const 1.781127 ,img_width: 750 img_height 563batch = 100
epoch 980 cuda op const 0.028806 ,img_width: 750 img_height 563
epoch 981 cuda op const 0.028790 ,img_width: 750 img_height 563
epoch 982 cuda op const 0.028797 ,img_width: 750 img_height 563
epoch 983 cuda op const 0.028782 ,img_width: 750 img_height 563
epoch 984 cuda op const 0.028801 ,img_width: 750 img_height 563
epoch 985 cuda op const 0.028824 ,img_width: 750 img_height 563
epoch 986 cuda op const 0.028808 ,img_width: 750 img_height 563
epoch 987 cuda op const 0.028845 ,img_width: 750 img_height 563
epoch 988 cuda op const 0.028838 ,img_width: 750 img_height 563
epoch 989 cuda op const 0.028825 ,img_width: 750 img_height 563
epoch 990 cuda op const 0.028794 ,img_width: 750 img_height 563
epoch 991 cuda op const 0.028817 ,img_width: 750 img_height 563
epoch 992 cuda op const 0.028783 ,img_width: 750 img_height 563
epoch 993 cuda op const 0.028804 ,img_width: 750 img_height 563
epoch 994 cuda op const 0.028774 ,img_width: 750 img_height 563
epoch 995 cuda op const 0.028631 ,img_width: 750 img_height 563
epoch 996 cuda op const 0.028582 ,img_width: 750 img_height 563
epoch 997 cuda op const 0.028596 ,img_width: 750 img_height 563
epoch 998 cuda op const 0.028594 ,img_width: 750 img_height 563
epoch 999 cuda op const 0.028604 ,img_width: 750 img_height 563
cpu propcess!!
epoch 0 cpu opencv const 5.226768 ,img_width: 750 img_height 563
epoch 1 cpu opencv const 3.195691 ,img_width: 750 img_height 563
epoch 2 cpu opencv const 2.124902 ,img_width: 750 img_height 563
epoch 3 cpu opencv const 2.339208 ,img_width: 750 img_height 563
epoch 4 cpu opencv const 1.806246 ,img_width: 750 img_height 563
epoch 5 cpu opencv const 2.067526 ,img_width: 750 img_height 563
epoch 6 cpu opencv const 1.486469 ,img_width: 750 img_height 563
epoch 7 cpu opencv const 1.414405 ,img_width: 750 img_height 563
epoch 8 cpu opencv const 1.417124 ,img_width: 750 img_height 563
epoch 9 cpu opencv const 0.905187 ,img_width: 750 img_height 563
epoch 10 cpu opencv const 1.772198 ,img_width: 750 img_height 563
epoch 11 cpu opencv const 1.603525 ,img_width: 750 img_height 563
epoch 12 cpu opencv const 1.799590 ,img_width: 750 img_height 563
epoch 13 cpu opencv const 1.758662 ,img_width: 750 img_height 563
epoch 14 cpu opencv const 1.768677 ,img_width: 750 img_height 563
epoch 15 cpu opencv const 1.646501 ,img_width: 750 img_height 563
epoch 16 cpu opencv const 2.659240 ,img_width: 750 img_height 563
epoch 17 cpu opencv const 1.101092 ,img_width: 750 img_height 563
epoch 18 cpu opencv const 1.672933 ,img_width: 750 img_height 563
epoch 19 cpu opencv const 1.896550 ,img_width: 750 img_height 563
epoch 20 cpu opencv const 1.555621 ,img_width: 750 img_height 563batch = 1000
epoch 980 cuda op const 0.002896 ,img_width: 750 img_height 563
epoch 981 cuda op const 0.002896 ,img_width: 750 img_height 563
epoch 982 cuda op const 0.002885 ,img_width: 750 img_height 563
epoch 983 cuda op const 0.003374 ,img_width: 750 img_height 563
epoch 984 cuda op const 0.003342 ,img_width: 750 img_height 563
epoch 985 cuda op const 0.003326 ,img_width: 750 img_height 563
epoch 986 cuda op const 0.003387 ,img_width: 750 img_height 563
epoch 987 cuda op const 0.002899 ,img_width: 750 img_height 563
epoch 988 cuda op const 0.005490 ,img_width: 750 img_height 563
epoch 989 cuda op const 0.003381 ,img_width: 750 img_height 563
epoch 990 cuda op const 0.003330 ,img_width: 750 img_height 563
epoch 991 cuda op const 0.003318 ,img_width: 750 img_height 563
epoch 992 cuda op const 0.003388 ,img_width: 750 img_height 563
epoch 993 cuda op const 0.002888 ,img_width: 750 img_height 563
epoch 994 cuda op const 0.005479 ,img_width: 750 img_height 563
epoch 995 cuda op const 0.003373 ,img_width: 750 img_height 563
epoch 996 cuda op const 0.003340 ,img_width: 750 img_height 563
epoch 997 cuda op const 0.003340 ,img_width: 750 img_height 563
epoch 998 cuda op const 0.003396 ,img_width: 750 img_height 563
epoch 999 cuda op const 0.002887 ,img_width: 750 img_height 563
cpu propcess!!
epoch 0 cpu opencv const 5.238708 ,img_width: 750 img_height 563
epoch 1 cpu opencv const 2.164763 ,img_width: 750 img_height 563
epoch 2 cpu opencv const 2.063035 ,img_width: 750 img_height 563
epoch 3 cpu opencv const 2.486202 ,img_width: 750 img_height 563
epoch 4 cpu opencv const 1.245405 ,img_width: 750 img_height 563
epoch 5 cpu opencv const 1.014045 ,img_width: 750 img_height 563
epoch 6 cpu opencv const 1.394557 ,img_width: 750 img_height 563
epoch 7 cpu opencv const 1.161213 ,img_width: 750 img_height 563
epoch 8 cpu opencv const 1.397469 ,img_width: 750 img_height 563
epoch 9 cpu opencv const 1.737884 ,img_width: 750 img_height 563
epoch 10 cpu opencv const 1.084029 ,img_width: 750 img_height 563
epoch 11 cpu opencv const 1.064254 ,img_width: 750 img_height 563
epoch 12 cpu opencv const 2.396474 ,img_width: 750 img_height 563
epoch 13 cpu opencv const 1.971900 ,img_width: 750 img_height 563
epoch 14 cpu opencv const 1.725276 ,img_width: 750 img_height 563
epoch 15 cpu opencv const 1.567133 ,img_width: 750 img_height 563
epoch 16 cpu opencv const 2.015387 ,img_width: 750 img_height 563
epoch 17 cpu opencv const 1.704092 ,img_width: 750 img_height 563
epoch 18 cpu opencv const 1.677532 ,img_width: 750 img_height 563
epoch 19 cpu opencv const 1.555516 ,img_width: 750 img_height 563
epoch 20 cpu opencv const 1.952060 ,img_width: 750 img_height 563batch = 5000
epoch 980 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 981 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 982 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 983 cuda op const 0.000573 ,img_width: 750 img_height 563
epoch 984 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 985 cuda op const 0.000577 ,img_width: 750 img_height 563
epoch 986 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 987 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 988 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 989 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 990 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 991 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 992 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 993 cuda op const 0.000576 ,img_width: 750 img_height 563
epoch 994 cuda op const 0.000574 ,img_width: 750 img_height 563
epoch 995 cuda op const 0.000576 ,img_width: 750 img_height 563
epoch 996 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 997 cuda op const 0.000576 ,img_width: 750 img_height 563
epoch 998 cuda op const 0.000575 ,img_width: 750 img_height 563
epoch 999 cuda op const 0.000575 ,img_width: 750 img_height 563
cpu propcess!!
epoch 0 cpu opencv const 5.225226 ,img_width: 750 img_height 563
epoch 1 cpu opencv const 5.118987 ,img_width: 750 img_height 563
epoch 2 cpu opencv const 1.679843 ,img_width: 750 img_height 563
epoch 3 cpu opencv const 1.647299 ,img_width: 750 img_height 563
epoch 4 cpu opencv const 1.635460 ,img_width: 750 img_height 563
epoch 5 cpu opencv const 1.637443 ,img_width: 750 img_height 563
epoch 6 cpu opencv const 1.632451 ,img_width: 750 img_height 563
epoch 7 cpu opencv const 1.624227 ,img_width: 750 img_height 563
epoch 8 cpu opencv const 1.534532 ,img_width: 750 img_height 563
epoch 9 cpu opencv const 1.769283 ,img_width: 750 img_height 563
epoch 10 cpu opencv const 1.611299 ,img_width: 750 img_height 563
epoch 11 cpu opencv const 1.604932 ,img_width: 750 img_height 563
epoch 12 cpu opencv const 1.612163 ,img_width: 750 img_height 563
epoch 13 cpu opencv const 1.655651 ,img_width: 750 img_height 563
epoch 14 cpu opencv const 1.643011 ,img_width: 750 img_height 563
epoch 15 cpu opencv const 1.689508 ,img_width: 750 img_height 563
epoch 16 cpu opencv const 1.681379 ,img_width: 750 img_height 563
epoch 17 cpu opencv const 1.629092 ,img_width: 750 img_height 563
epoch 18 cpu opencv const 2.414660 ,img_width: 750 img_height 563
epoch 19 cpu opencv const 1.696036 ,img_width: 750 img_height 563
epoch 20 cpu opencv const 1.669123 ,img_width: 750 img_height 5632.cuda计算与cv::resizepad_bgr2rgb的时间对比
九.test_Resize_Pad_Bgr2rgb.cpp源码
#include "src/utils/utils.h"
#include "src/resizepad/resizepad.h"
std::vector<cv::Mat> floatptr2cvmat(tools::Param param,float* imgptr){
std::vector<cv::Mat> img_list;
for(int i=0;i<param.batch;++i){
float* img_data = imgptr+i*param.dst_h*param.dst_w*3;
cv::Mat floatcvimg(param.dst_h,param.dst_w,CV_32FC3,img_data);
cv::Mat uint8cvimg;
floatcvimg.convertTo(uint8cvimg,CV_8UC3);
img_list.push_back(uint8cvimg.clone());
}
return img_list;
}
int main(){
tools::Param param;
tools::AffineMatrix matrix_src2dst;
tools::AffineMatrix matrix_dst2src;
cv::Mat src2dstmat;
cv::Mat dst2srcmat;
cv::Mat img = cv::imread("../a.jpg");
param.src_h = img.rows;
param.src_w = img.cols;
float scale = std::min(param.dst_h/(float)param.src_h, param.dst_w/float(param.src_w));
float offset_x = 0.5*(param.dst_w-param.src_w*scale+scale-1);
float offset_y = 0.5*(param.dst_h-param.src_h*scale+scale-1);
src2dstmat = (cv::Mat_<float>(2,3,CV_32FC1)<<scale,0,offset_x,0,scale,offset_y);
cv::invertAffineTransform(src2dstmat,dst2srcmat);
matrix_dst2src.v0 = dst2srcmat.ptr<float>(0)[0];
matrix_dst2src.v1 = dst2srcmat.ptr<float>(0)[1];
matrix_dst2src.v2 = dst2srcmat.ptr<float>(0)[2];
matrix_dst2src.v3 = dst2srcmat.ptr<float>(1)[0];
matrix_dst2src.v4 = dst2srcmat.ptr<float>(1)[1];
matrix_dst2src.v5 = dst2srcmat.ptr<float>(1)[2];
unsigned char* batch_imgs;
float* batch_imgs_resized_host;
float* batch_imgs_resized_device;
// 将多个cv::Mat host指针数据形成dynamicbatch
cudaMalloc((void**)&batch_imgs,param.batch*param.src_w*param.src_h*3*sizeof(unsigned char));
// 为cuda核函数计算结果在host端展示的空间分配内存
batch_imgs_resized_host = (float*)malloc(param.batch*param.dst_h*param.dst_w*3*sizeof(float));
// 为cuda核函数计算结果在device端的空间分配内存
cudaMalloc((void**)&batch_imgs_resized_device,param.batch*param.dst_h*param.dst_w*3*sizeof(float));
// 将cv::Mat host指针数据拷贝到device
for(int i=0;i<param.batch;++i){
cudaMemcpy(batch_imgs+i*param.src_w*param.src_h*3,img.data,
param.src_w*param.src_h*3*sizeof(unsigned char),cudaMemcpyHostToDevice);
}
for(int i=0;i<param.epochs;++i){
DeviceTimer dt0;
launch_cuda_resize_padding(param,batch_imgs,batch_imgs_resized_device,matrix_dst2src);
float dc0 = dt0.getUsedTime()/param.batch;
printf("epoch %d cuda op const %f ,img_width: %d img_height %d\n",i,dc0,img.cols,img.rows);
}
printf("cpu propcess!!");
cv::Mat img_cpu;
cv::Mat img_cpu_gray(cv::Size(param.dst_w,param.dst_h),CV_8UC3,cv::Scalar(127,127,127));
int target_w = (int)param.src_w*scale;
int target_h = (int)param.src_h*scale;
// offset_x = (param.dst_h-target_h)/2;
// offset_y = (param.dst_w-target_w)/2;
offset_x = std::max(0, (param.dst_w - target_w) / 2);
offset_y = std::max(0, (param.dst_h - target_h) / 2);
for(int j=0;j<param.epochs;++j){
HostTimer ht0;
cv::resize(img,img_cpu,cv::Size(target_w,target_h),0,0,cv::INTER_LINEAR);
cv::cvtColor(img_cpu,img_cpu,cv::COLOR_BGR2RGB);
img_cpu.copyTo(img_cpu_gray(cv::Rect(offset_x,offset_y,img_cpu.cols,img_cpu.rows)));
float hc1 = ht0.getUsedTime();
printf("epoch %d cpu opencv const %f ,img_width: %d img_height %d\n",j,hc1,img.cols,img.rows);
}
cv::imwrite("cpu_rezizepadbgr.jpg",img_cpu_gray);
cudaMemcpy(batch_imgs_resized_host,batch_imgs_resized_device,
param.batch*param.dst_h*param.dst_w*3*sizeof(float),cudaMemcpyDeviceToHost);
std::vector<cv::Mat> img_list = floatptr2cvmat(param,batch_imgs_resized_host);
for(int j=0;j<img_list.size();++j){
std::string img_name = std::to_string(j)+".jpg";
cv::imwrite(img_name,img_list[j]);
}
free(batch_imgs_resized_host);
cudaFree(batch_imgs);
cudaFree(batch_imgs_resized_device);
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









