






目录
什么是KNN算法?
KNN算法核心思想很简单:“近朱者赤近墨者黑”。
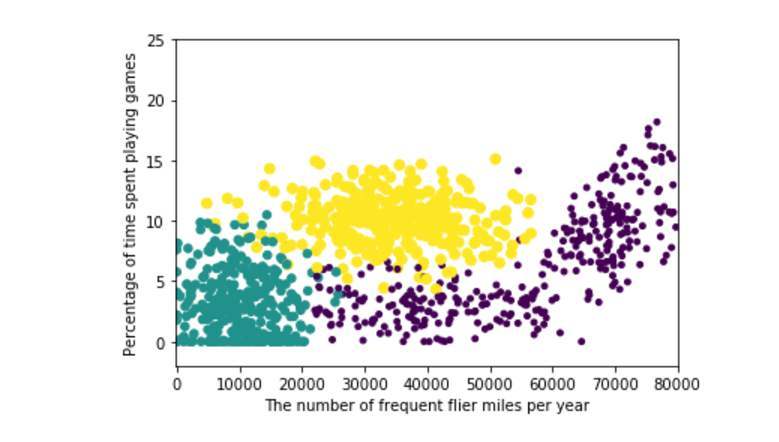
上例子:
如图,可以粗略将图分成三部分,黄绿紫。接着我们随便用笔往图上点一下留下印记A。而KNN算法要做的就是找出离A点距离最近的K个点,把这K个点的加权结果赋值给A作为A的结果就算完成了。
算法归纳如下 :
1.获取数据
2.读取数据
3.划分测试集训练集(KNN算法不需要训练,但是要修正K值)
4.计算距离
5.加权平均
算法重点:
影响KNN算法最终结果的两个重要因素就是K的值与计算距离的方式。
K值过大会导致结果过于平滑:即无论用什么样的点进行测试输出的都会是数据集中数量最多的结果,无法做到分类,这不是我们想要的。K值过小又会导致泛化能力低,对于临近点太过依赖。因此,选取一个合适的K值是重中之重。
计算距离的方式不同结算结果不同,同样会影响到最后结果。常用的计算方法有如下两种

算法优缺点
| 简单,易于理解,是一个天然的多分类器 | 数据量大的时候,计算量也非常大(样本多,特征多) |
| 不需要庞大的样本数据也可以完成一个简单的分类 | 不平衡样本处理能力差 |
| 不需要训练和求解参数 | 并没有学习和优化的过程,严格来说不算是机器学习 |
KNN算法实战--集美大学分区
算法目的:
看下图,蓝线简单的把集美大学本部划分成两个区,以下为学习区,以上为休息区。接下来我们就用KNN算法来辨别目标点到底是学习区(study)还是休息区(rest )。
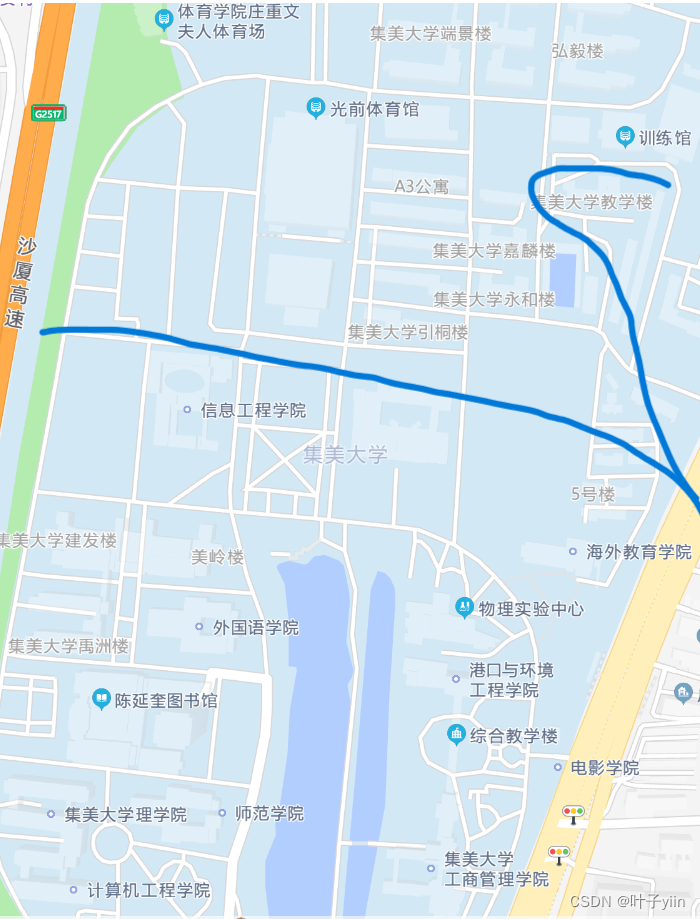
获取数据集
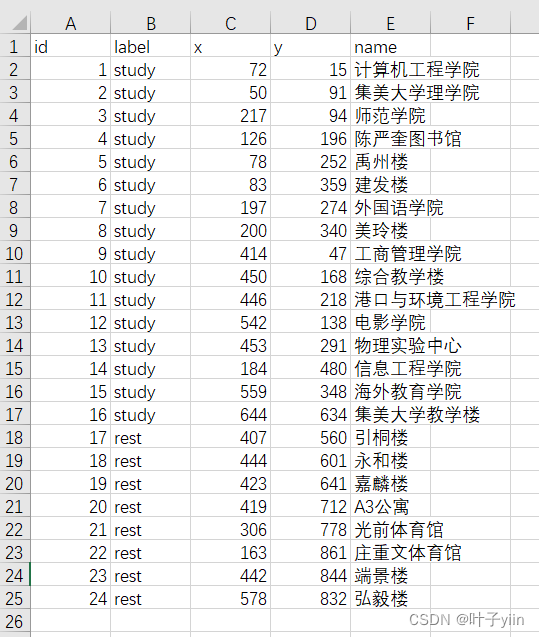
将上述所有展示的点用二维坐标表示,可以用qq截图功能将像素点近似的表示成距离
如下示例,以左下角为原点,则第一个点计算机工程学院的坐标为(72,15)。

统计后结果如下
代码
import random
import csv
#读取
with open('KNN.csv','r',encoding='utf-8') as file:
reader=csv.DictReader(file)
datas=[row for row in reader]
#分组
random.shuffle(datas)#打乱
n=len(datas)//3
test_set=datas[0:n]
train_set=datas[n:]
#计算欧氏距离
def distance(d1,d2):
res=0
for key in ("x","y"):
res+=(float(d1[key])-float(d2[key]))**2
return res**0.5
K=1
def knn(data):
res=[
{"label_result":train['label'],"distance":distance(data,train)}
for train in train_set
]
#排序
res=sorted(res,key=lambda item:item['distance'])
#取前K个
res2=res[0:K]
#加权平均
result={'study':0,'rest':0}
sum=0
for r in res2:
sum+=r['distance']
for r in res2:
result[r['label_result']]+=1-r['distance']/sum
if result['study']>result['rest']:
return 'study'
else:
return 'rest'
for i in range(10):
random.shuffle(datas) # 打乱
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]
correct=0
for test in test_set:
result=test['label']
result2=knn(test)
if result==result2:
correct+=1
print(correct/len(test_set))
i+=1结果分析
当k分别取1、3、5 、13时准确率分别如下
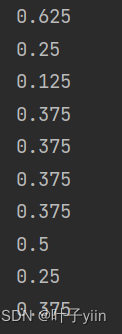
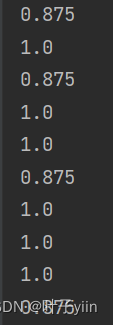
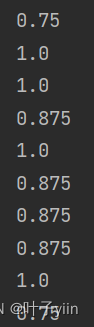
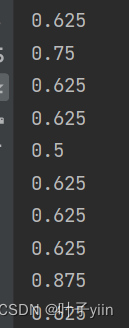
可以看到在最近邻算法中的准确率处于一个较低水平,猜测是有一个study样例点(集美大学教学楼)处于rest区域中的原因。
当K取值3-7之间准确率近似,都在85+,K取值11+后准确率急速下降,推测是正例反例的数据集不平衡导致的(16/8),同时又因为数据集的数量较小,K值对结果影响比较大。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









