




Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

由图,其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
1. add
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

残差连接
残差连接的核心思想是在网络的一层或多层之间引入直接连接,使得这些层的输出不仅包括经过非线性变换的特征,还包括未经处理的输入特征。这样做的目的是允许神经网络学习到的是输入和输出之间的残差(即差异),而不是直接学习一个完整的映射。这种方式有助于梯度在训练过程中更有效地回流,减轻深度网络中梯度消失的问题。
2. norm
Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
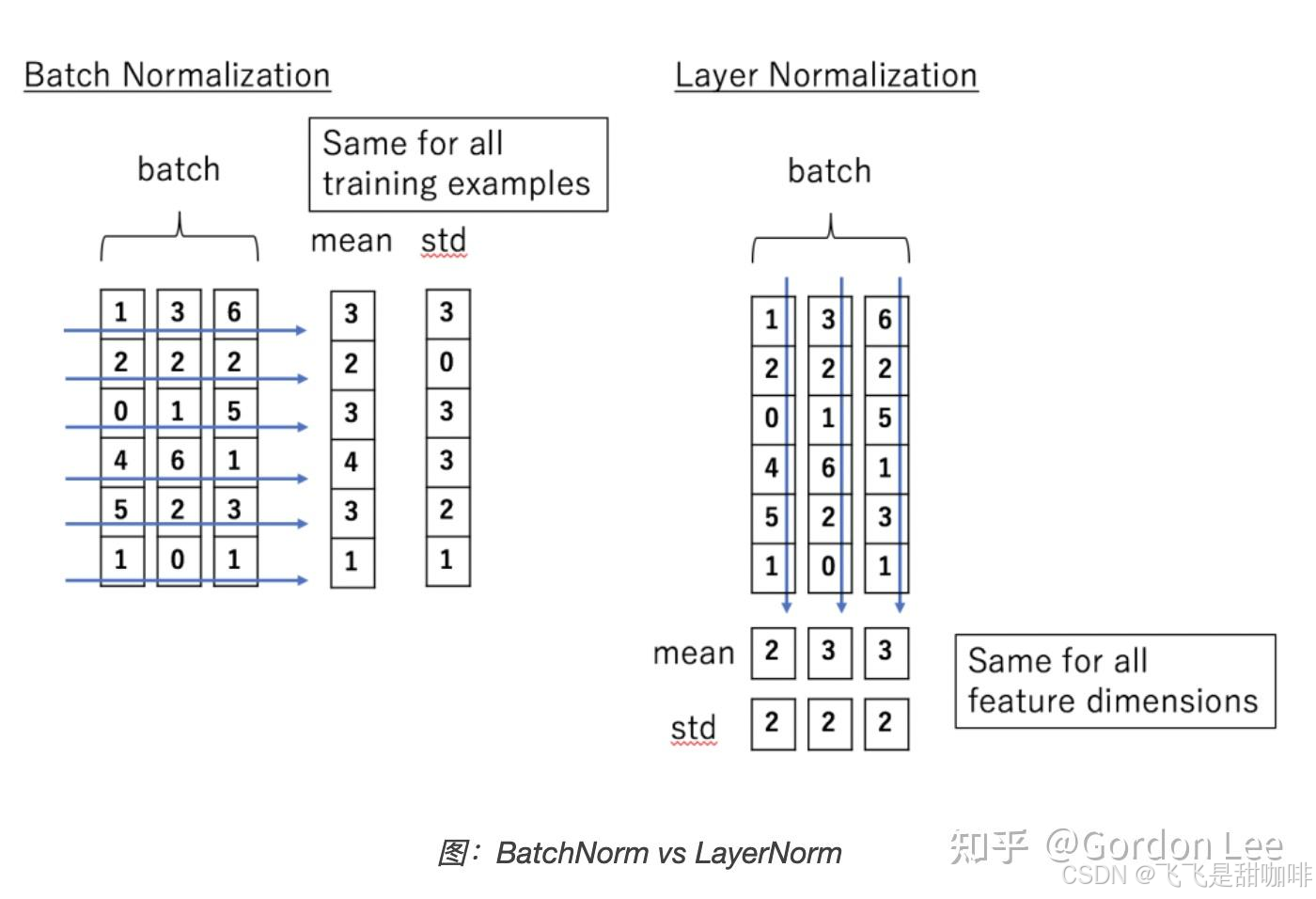
BN是对batch的维度去做归一化,也就是针对不同样本的同一特征做操作。LN是对hidden的维度去做归一化,也就是针对单个样本的不同特征做操作。因此LN可以不受样本数的限制。
具体而言,BN就是在每个维度上统计所有样本的值,计算均值和方差;LN就是在每个样本上统计所有维度的值,计算均值和方差(注意,这里都是指的简单的MLP情况,输入特征是(bsz,hidden_dim))。所以BN在每个维度上分布是稳定的,LN是每个样本的分布是稳定的。
Layer Normalization 的工作原理:
-
归一化:对于每个输入样本,计算该样本在当前层的所有神经元的均值和方差。然后使用这些统计量对输入进行归一化,使得归一化后的输出具有零均值和单位方差。
-
缩放和平移:在归一化之后,Layer Normalization 还会引入可学习的参数(缩放因子和偏置),以便模型能够恢复到原始的分布。这意味着归一化后的输出可以通过以下公式表示:
其中,x^是归一化后的输入,γ 和 β是可学习的参数。
3. 适用性:Layer Normalization 特别适合于循环神经网络(RNN)和其他需要处理变长输入的模型,因为它是对每个样本独立进行归一化的,而不是在批次维度上进行。
优势:
- 加速收敛:通过减少内部协变量偏移(internal covariate shift),Layer Normalization 可以加快模型的收敛速度。
- 提高稳定性:在训练过程中,模型的表现更加稳定,减少了梯度消失或爆炸的风险。
- 适应性强:可以在不同的网络架构中使用,尤其是在小批量训练时表现良好。
reference:

















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









