



 本文介绍了如何在Spring中使用@Scheduled注解进行任务自动化调度,包括固定延迟、固定速率和自定义cron表达式。同时讨论了分布式调度的需求,如高可用性、防止重复执行和性能优化,以及XXL-JOB分布式任务调度平台的使用和配置。
本文介绍了如何在Spring中使用@Scheduled注解进行任务自动化调度,包括固定延迟、固定速率和自定义cron表达式。同时讨论了分布式调度的需求,如高可用性、防止重复执行和性能优化,以及XXL-JOB分布式任务调度平台的使用和配置。
@Scheduled(任务自动化调度)
第一步要在启动配置类上面使用注解@EnableScheduling开启任务调度
Spring提供注解@Scheduled用来做任务自动化调用的。而注解里面的参数分为三个:
1、@Scheduled(fixedDelay = 5000)
延时执行,也就是调用该任务的时候,会延时5s再执行
2、@Scheduled(fixedRate = 5000)
定时循环任务,也就是每个5s就执行对应的任务。
3. @Scheduled(cron = “0 0 2 * * ?”)
自定义规则执行,上面的意思是每天凌晨2点执行下面的任务。
而里面是怎么去定义时间的咧,主要是从左到右用空格进行风格。
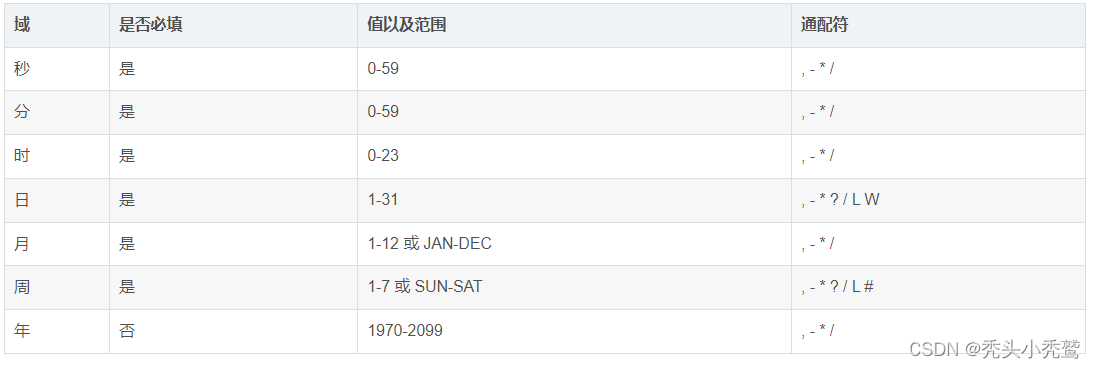
然后这个规则基本上都是定义一天之类的,如果想间隔时间来执行任务的话,就需要用到对应的通配符:
" * "------------------------------------全部都执行,每一个都执行
" ? "-----------------------------------忽略,也是说不用考虑以下字段的意思。
" / "-----------------------------------原本时间/间隔时间,间隔多久执行一次
" - "-----------------------------------区间,在这个时间区间里面
" , "-----------------------------------每一个点
" L "-----------------------------------最后一个时间点
案例:
@scheduled (cron="15,20,40 15-20 2/5 L * ?")
———每个月的最后一天的凌晨2点每隔5个小时的第15分钟到20分钟之间的每分钟的15,20,40秒执行一次。
注意:默认情况下,只有一个线程在执行这个任务调度(默认情况下,没有去设置线程池的话,springboot会默认创建一个线程数为1的线程池。)而这个线程池是ScheduledThreadPool(定时执行的线程池)
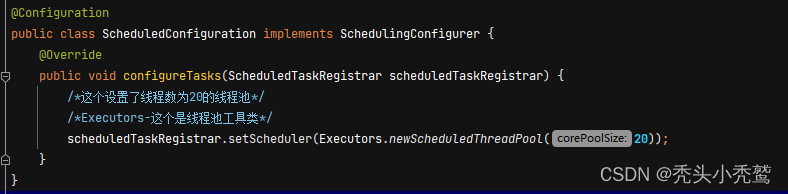
注意:这里是使用了工具类来进行线程池的创建。当然也可以通过ScheduledThreadPoolExecutor的构造方法来执行。
XXL-JOB(分布式调度)
上面是基于spring提供的注解,貌似能够完全解决我们的问题。那为什么还需要分布式咧?
1、高可用:
单机版的定时任务调度只能在一台机器上面运行,如果程序出现异常,对应的功能就无法使用了。
2、防止重复执行:
在机器集群的时候,无法确保定时任务是一个的,而不是多个重复的,所以就使用xxl-job
3、单机的性能瓶颈:
如果时单机状态的时候由于cpu,内存,磁盘会导致处理能力下降,所以此时建议使用分布式调度来进行。
执行原理图:
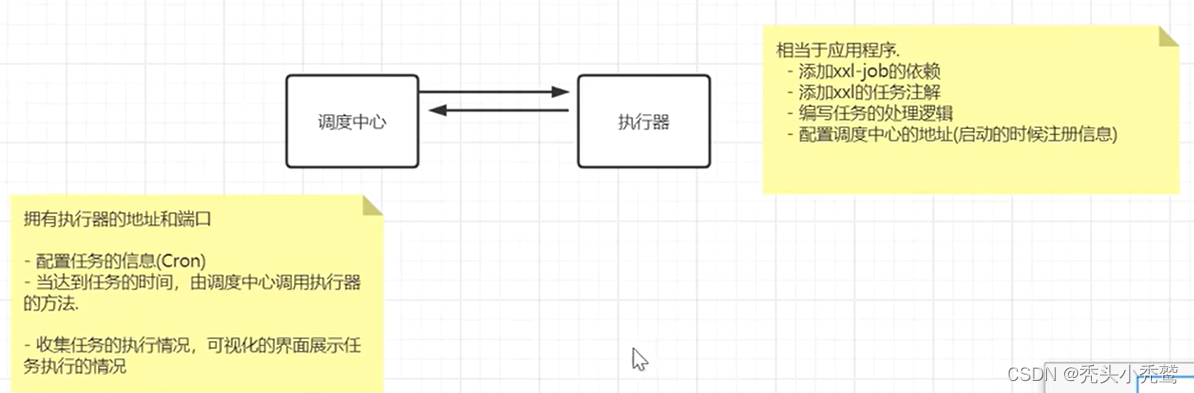
调度中心设置:
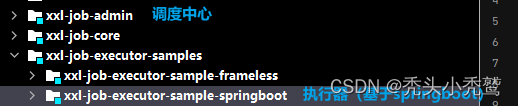
在gitee里面把对应的xxl-job源码远程下载。(xxl-job: 一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。)
里面有三个模块。
配置文件设置:
而调度中心是基于springboot来进行搭建的。所以对应的会有application.properties文件:
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### 如果对应的映射文件相同的时候,就不需要这样来,但是如果映射文件不相同时,需要专业昂来。
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl对应的数据库连接
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=1234
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000
### xxl执行失败之后,发送消息给邮箱使用的
### xxl-job, email
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.from=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
# 连接token,也就是其他业务要连接上的时候,这个就是密码
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
xxl.job.logretentiondays=30
数据库文件设置:
因为xxl-job是基于mysql数据库进行操作信息的记录的,所以在开启之前需要构建对应的数据库文件。
这个是sql文件是用来定义好对应的数据库表的。执行sql文件来生成对应的数据库表即可。
对应的数据库的表信息是这些:

配置好上面的数据库文件以及配置文件信息之后,就可以开启了![]()
此时我们在打开对应的连接,我们就可以得到对应的网页了(默认账户admin,密码123456)
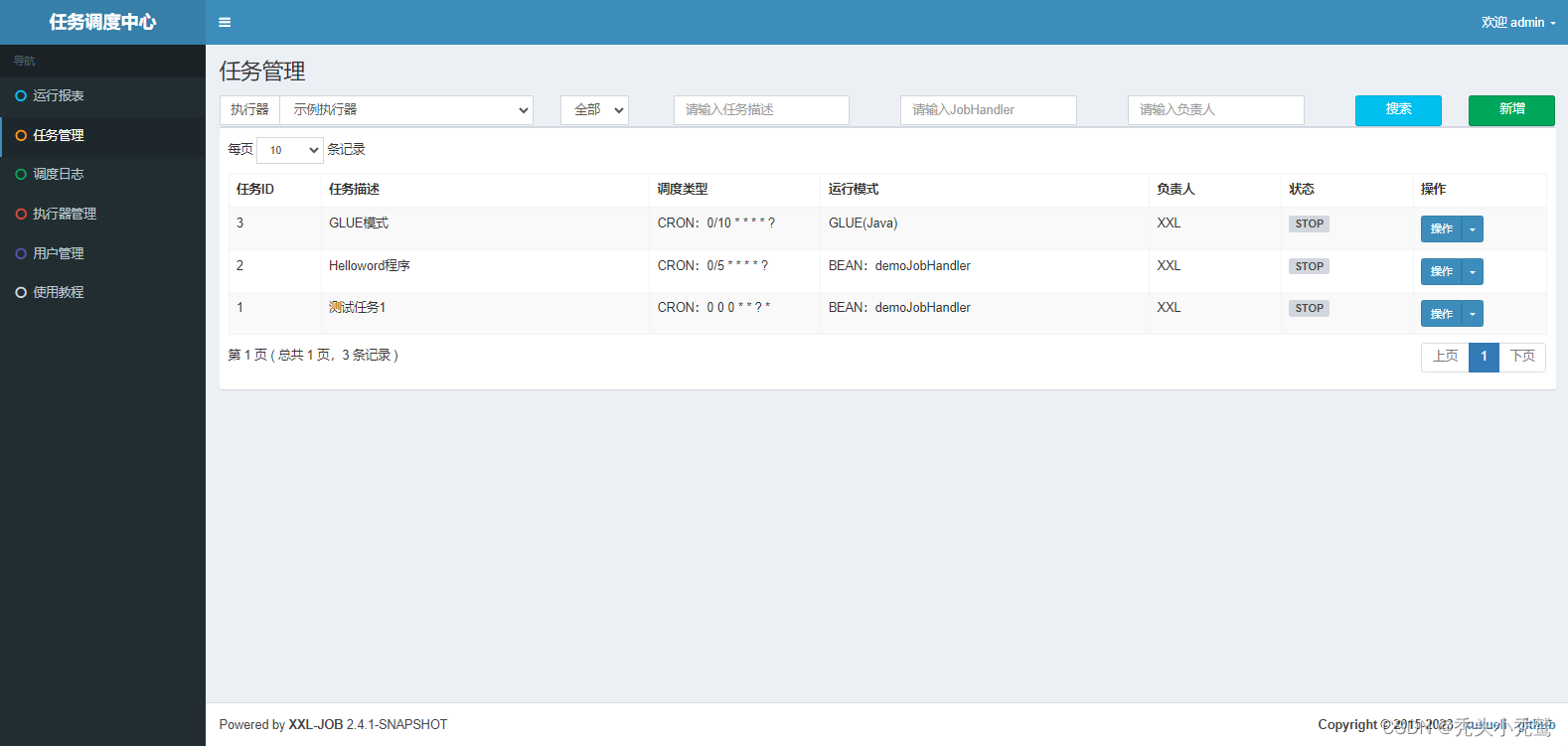
调度中心列表含义:
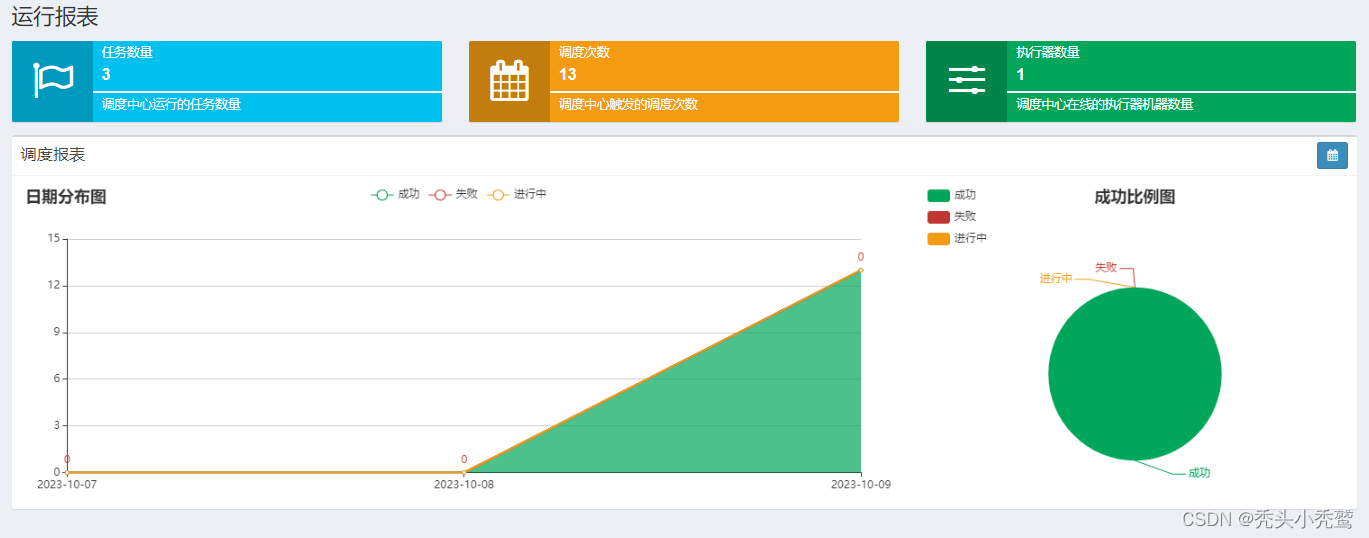
运行报表:
任务管理:
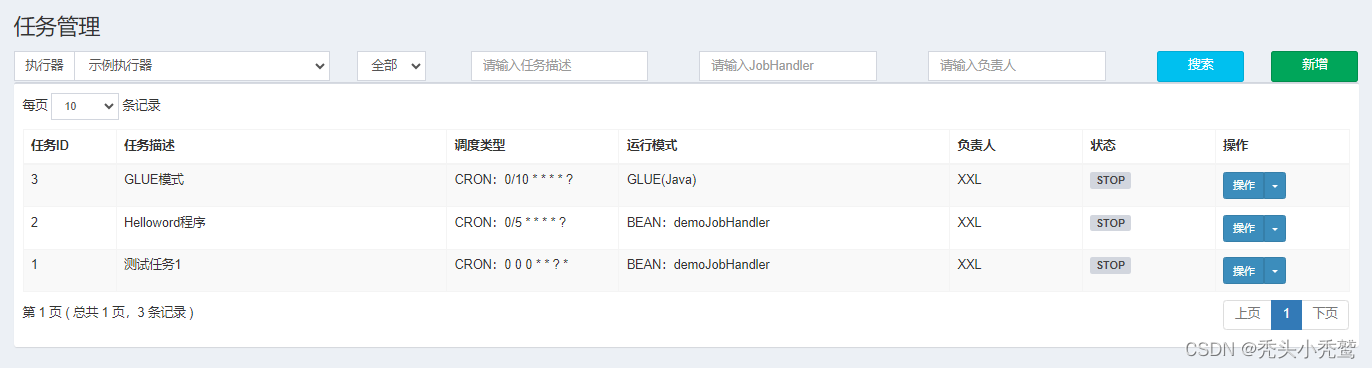
主要是用来创建定时任务的,并且开启。
BEAN模式:
只针对注解来执行任务。
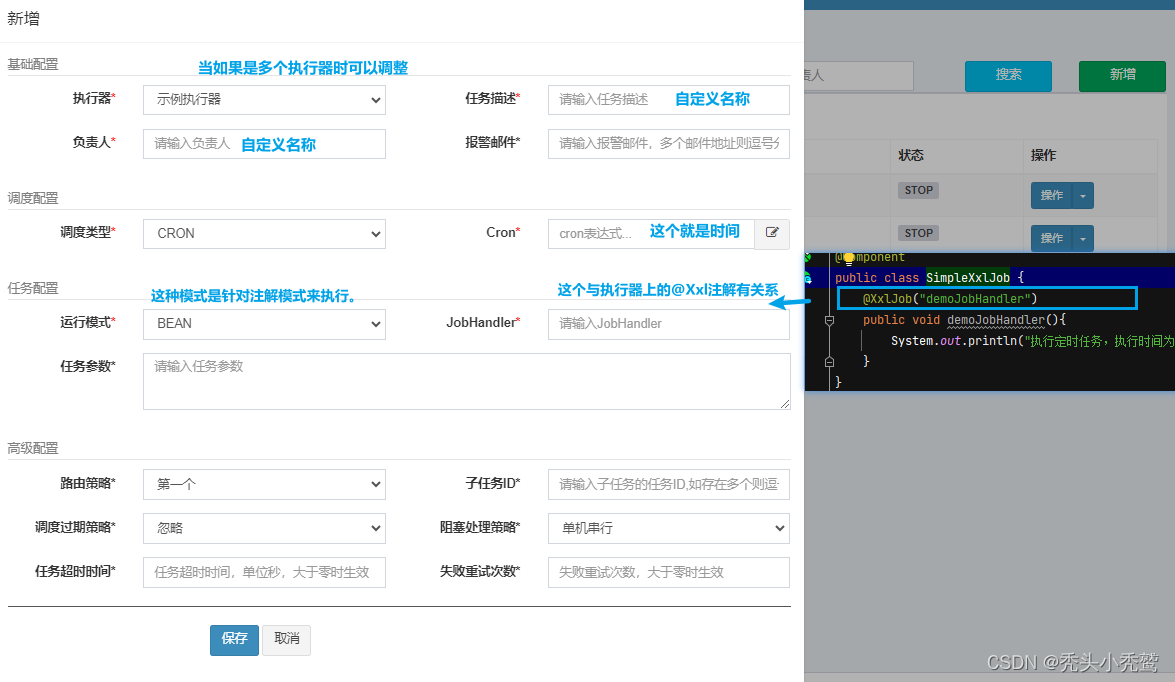
GLUE模式:
在调度中心上,直接编写定时任务代码,这样做的目的是为了不需要重启执行器,也可以定义定时任务。(需要留意的是,记得把类全路径名这一块也要放上去。)
调度日志:
主要是每一次的调度状态都会被记录下来,方便之后的查询。
执行器管理:
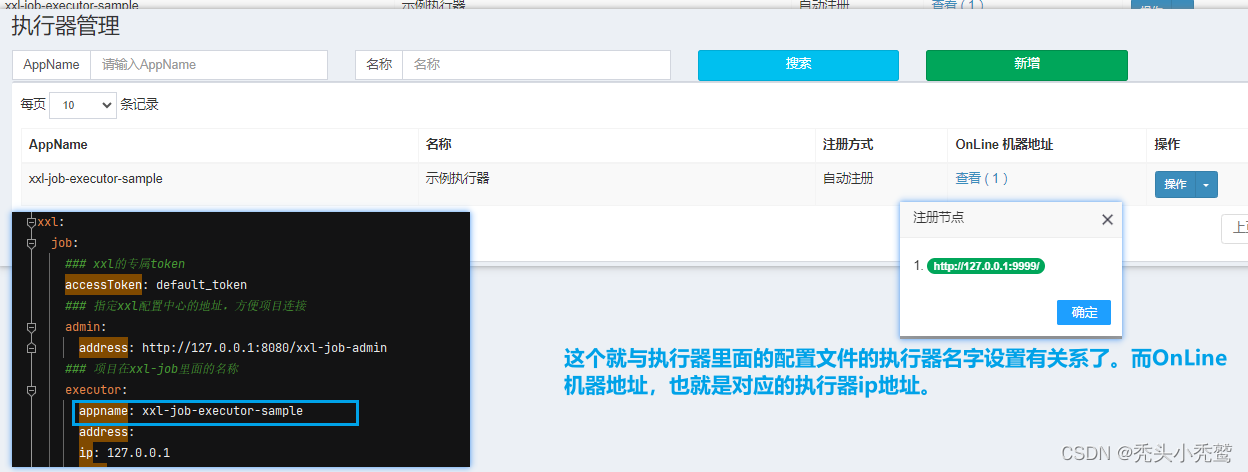
执行器:
引入依赖:
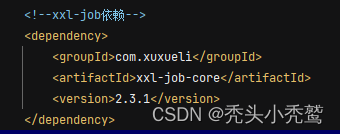
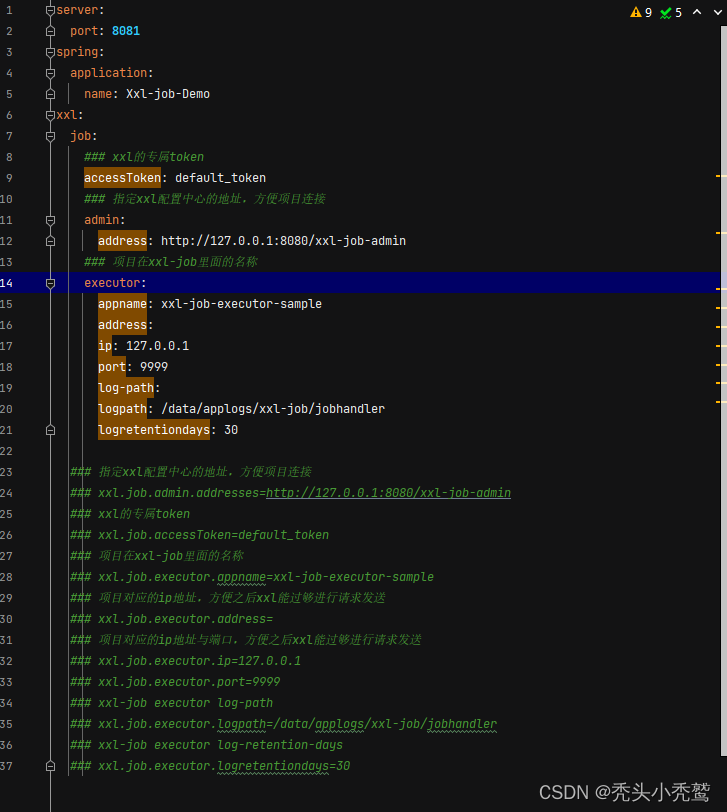
编写配置文件:
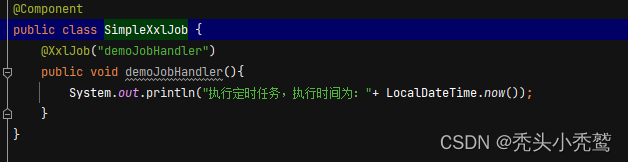
使用注解:
@XxlJob来定义在方法上,这样在调度中心上就可以调用到对应的注解任务。
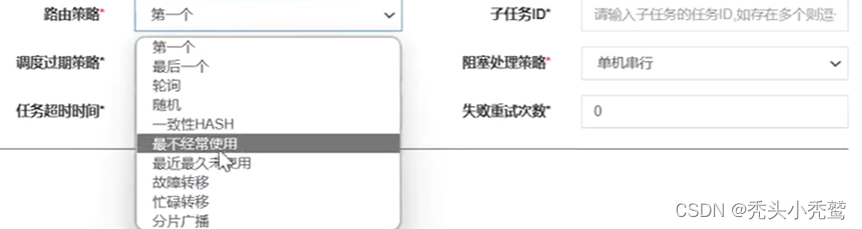
集群:
执行器:
当多个执行器的时候,并且同时都有注解@XxlJob的时候如何保证定时任务只执行其中的一个?
通过高级配置里面的路由策略就可以定义了。
我们假设一个命题,就是现在需要查询mysql中2000条数据,对应的现在执行器是以集群形式存在的,因为上面xxl-job也是可以让两个执行器同时执行操作。
分片机制:
路由策略上面使用分片广播,也就是把两个不同的执行器都进行执行对应的方法,此时我们可以通过方法:
//这个是获取当前执行器对应的Xxl服务有多少分片
int shardIndex=XxlJobHelper.getshardIndex();
//这个是获取当前执行器在对应的Xxl服务第几个分片
int shardTotal=XxlJobHelper.getshardTotal();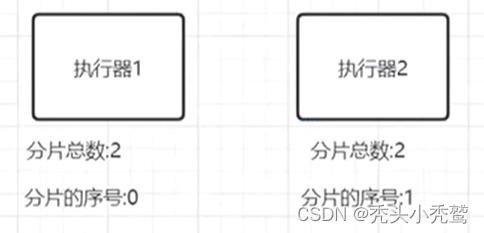
然后我们就可以把2000条查询的数据,通过两个执行器进行分片去处理。每个执行器执行1000条。

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









