



 本文详细介绍了在Elasticsearch中使用DSL进行查询的各种方法,包括match_all、全文检索(match_query和multi_match_query)、精确查询(term和range)、地理坐标查询(geo_distance和geo_bounding_box)、复合查询(functionscore和boolquery),以及如何在Java中通过API实现这些功能。
本文详细介绍了在Elasticsearch中使用DSL进行查询的各种方法,包括match_all、全文检索(match_query和multi_match_query)、精确查询(term和range)、地理坐标查询(geo_distance和geo_bounding_box)、复合查询(functionscore和boolquery),以及如何在Java中通过API实现这些功能。
DSL——在Mysql数据库里面也就是查询语句。而在Es里面分为五种查询(_search):
query条件(查询):
查询所有(match_all):
把索引库里面的文档(数据),全部查询出来,不根据字段进行查询。
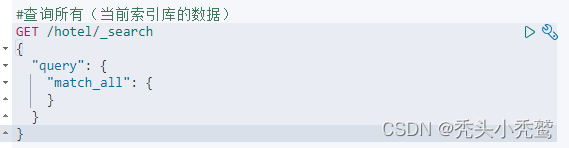
响应体:

全文检索(match_query/multi_match_query):
利用分词器对用户输入的内容进行分词,然后通过倒排索引库中匹配。
1、单字段查询(match_query):
也就是根据单一字段的分词条件来查询文档!
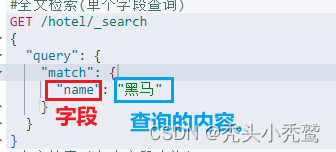
结果:

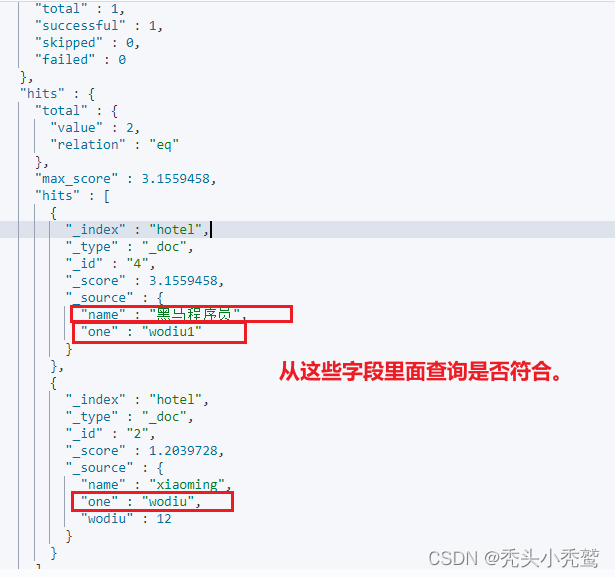
2、多字段查询(multi_match_query):
也就是查看多个字段是否符合语句里面的内容。
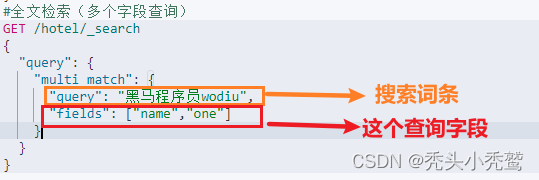
结果:
精确查询(term /range):
1、term(根据词条准确度来查询)
也就是对不分词的字段进行查询,因为是对不分词的字段进行查询,所以输入的字段就不需要做分词的操作了。
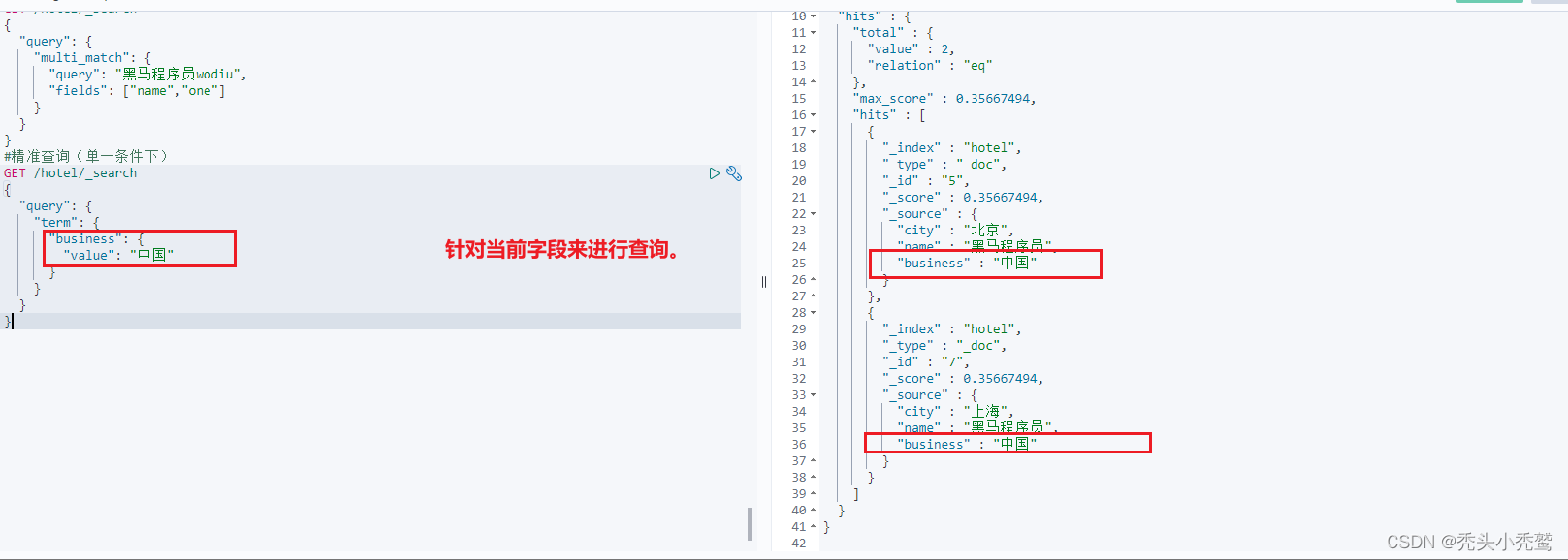
不支持多字段的查询,只支持单一字段的查询。
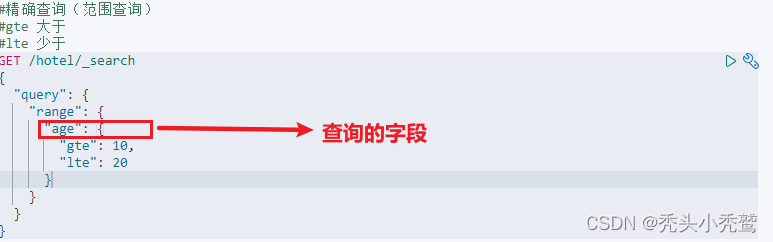
2、range(范围查询)
地理坐标查询(geo_distance/geo_bounding_box):
我们先看一下我们自己定义的索引库先:
![]()
这里是定义了location这个字段是地理坐标的字段的意思。以经纬度来确定一个点。我们再看一下对应的Doc类
![]()
是纬度,经度的形式进行存放的。
1、geo_distance(以圆半径来进行查询。)

2、geo_bounding_box(以对焦坐标来形成矩形查询。)

复合查询(fuction score/bool query):
更多的意思是指把其他的查询组合在一起,实现多条件查询。
1、fuction score(相关性算分):
我们都知道,我们查询过后会有一个对应的查询分值,分值越高说明匹配度越高(当然这是在没有调整分数的情况下)。

如果我们可以把分值自定义的去给他拉高。对应是不是就可以做到做广告的效果?
现在我是需要把上海城市的分值拉高。
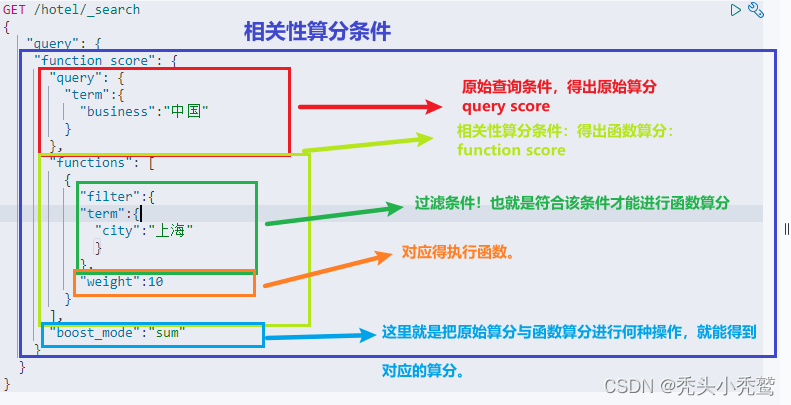 也就是算分分两种:原始算分(query score) !以及函数算分(function score) !
也就是算分分两种:原始算分(query score) !以及函数算分(function score) !
而函数算分有四种函数还获取:

而boost_mode是一个加权模式:也就是原始算分与函数算分进行什么然的操作!

结果:
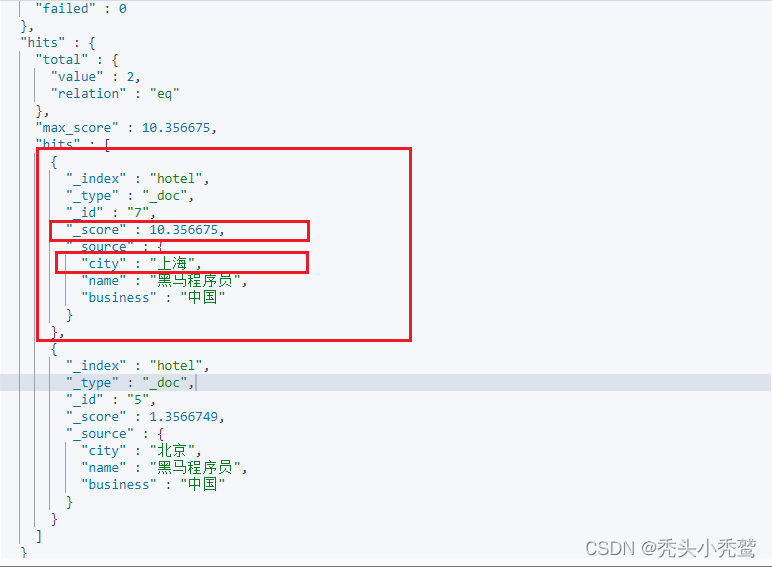
上海这个的分值多了10分。然后就会排在了上面去了。
2、bool query(布尔查询):
也就是多个条件查询,因为我们之前都是只能进行单个条件查询。如果不基于布尔查询来进行符合条件查询会报错
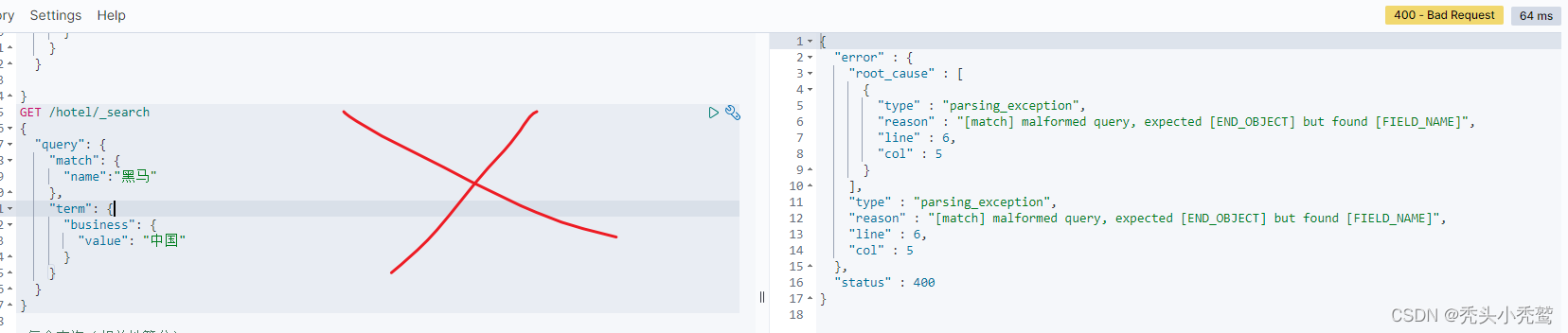
所以我们就知道了如果要基于多字段多条件查询的时候要使用布尔查询。就譬如这样:
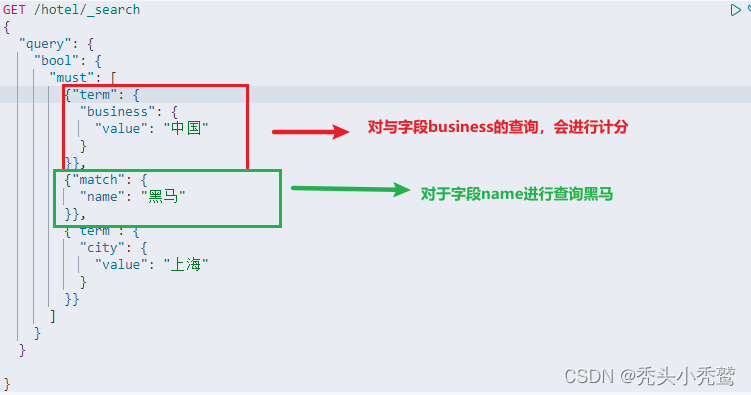
当然算分查询与布尔查询是可以嵌合在一起的。因为布尔查询的出来的分值是原始分值。此时看一下这里。

而布尔查询分四种类型:

sort条件(排序):
默认情况下是根据相关性算分来进行从大到小进行排排序的。建议不要自定义。
DESC为降序(自上往下),ASC为升序
1、普通字段排序(主要是数值,日期。)

2、地理坐标排序(针对地理坐标)

分页条件:
小体量的时候,使用From-size方式查询:

因为from-size的查询是基于把全部数据查询出来之后,再进行查询的。如果体量太大的时候,譬如查询到的文档上万的时候,这种方式会对内存以及cpu有很大的压力。
基本上都是search after:来进行分页查询。
高亮条件(highlight):
其实是把我们输入的搜索条件,查询出来文档之后,对其搜索条件的文字进行html的高亮符号的标志而已。因为我们是以json格式返回给前端页面的,所以前端页面接收到之后,就会把html的高亮符号也放入显示在里面了。

案例:
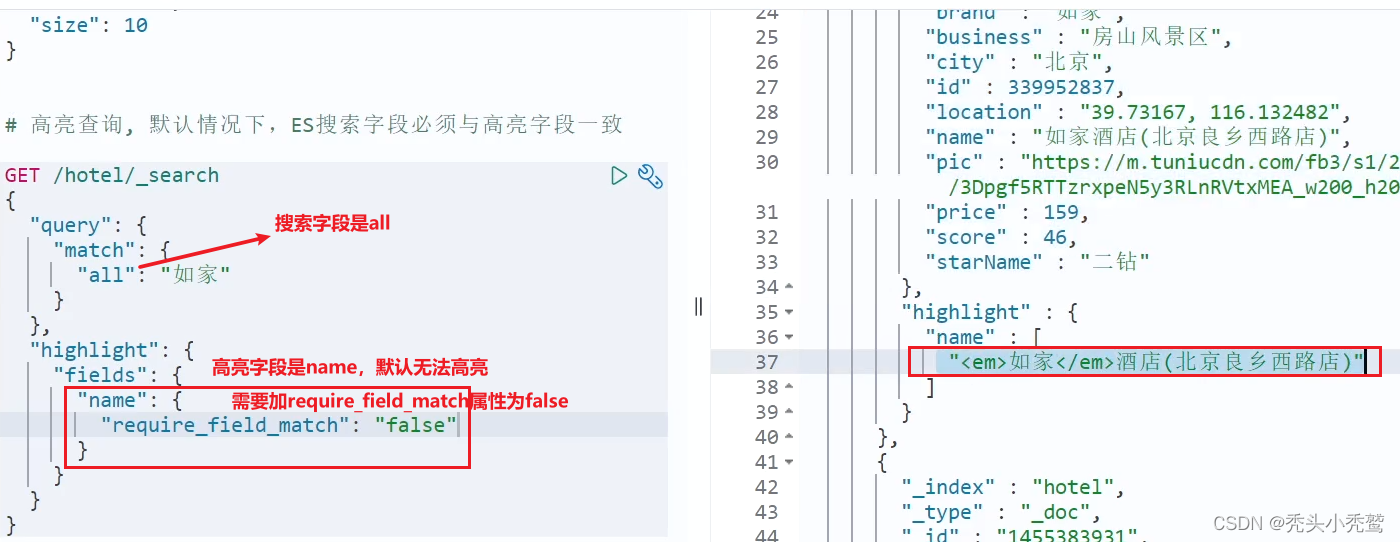
Java上实现:
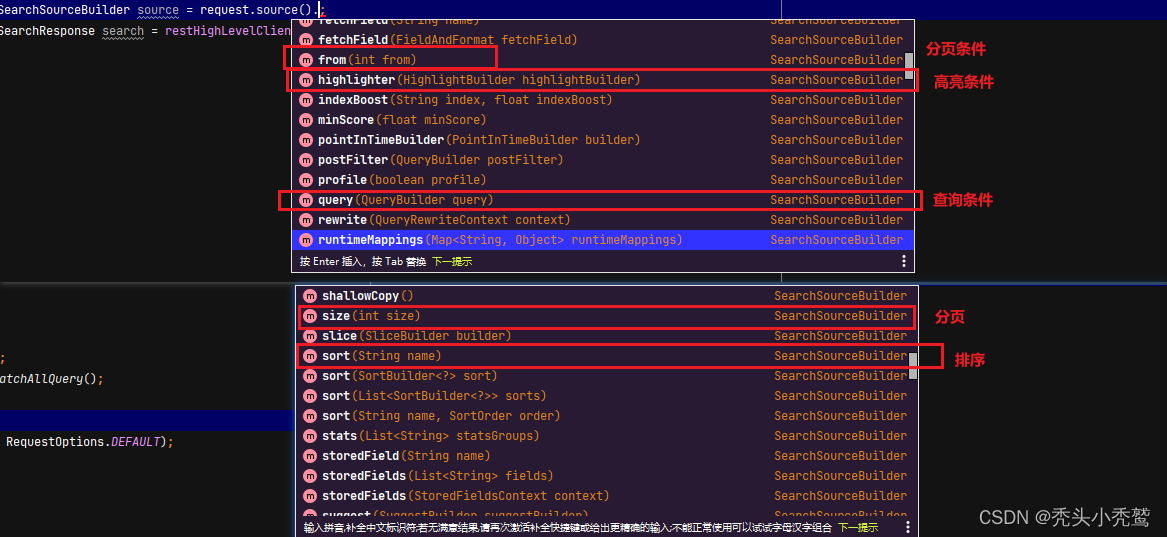
在学习java上面的api事项之前,我们需要知道的三个api:
SearchRequest————这个是DSL请求体的api
QueryBuilders————这个是条件创建类,它里面的静态方法对应着我们在kibana界面上面的东西:
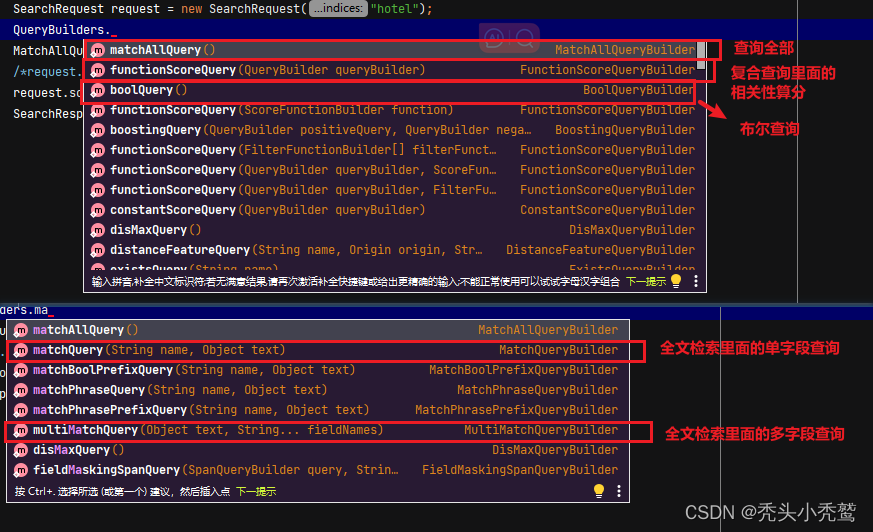
SearchSourceBuilder————执行DSL的语句的封装类对象。里面有对应请求体添加方法。
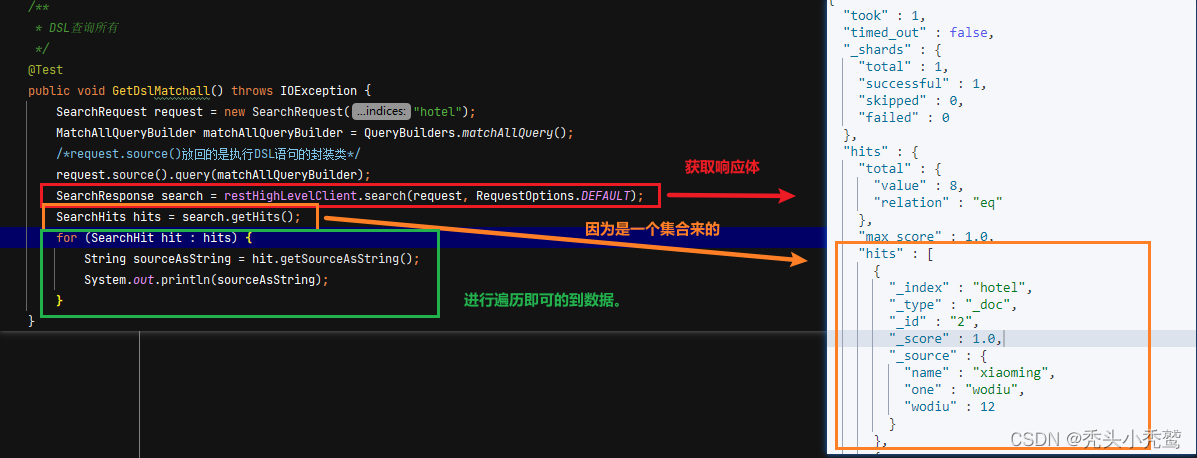
query条件(查询):
查询所有(MatchAllQuery):
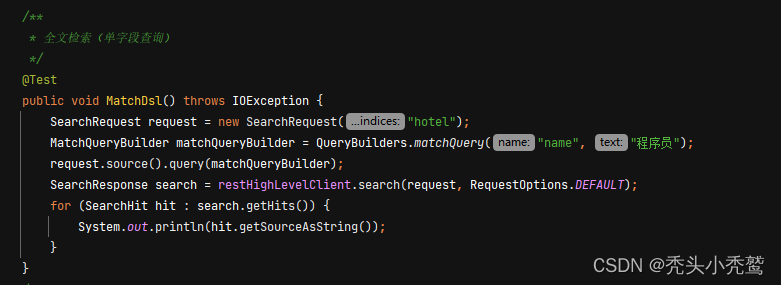
全文检索(matchQuery/multiMatchQuery)
1、单字段查询【matchQuery】:
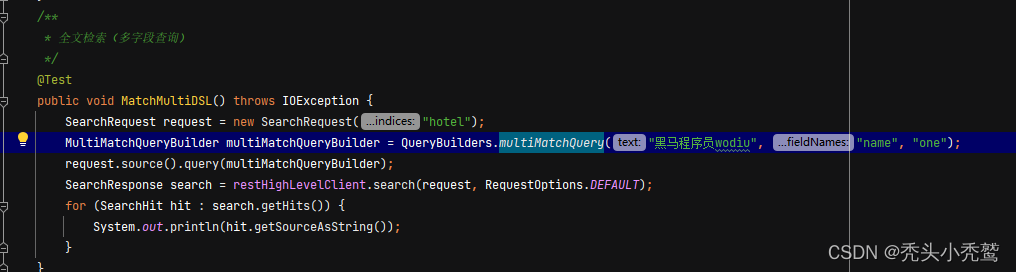
2、多字段查询【multiMatchQuery】:

















 1080
1080




 到【灌水乐园】发言
到【灌水乐园】发言







