






动机:
(1)模态矛盾。 许多现有的 MKGC 方法在将视觉信息添加到传统的 KG 嵌入时基本上忽略了视觉信息可能导致不确定性并引入噪声,这可能会带来模态矛盾。 特别地,一个实体通常在各种三元组(链接信息)中具有不同的属性,并且每个关联图像对该实体的贡献在不同的链接场景中是不同的。
(2)结构信息缺失。 大多数现有的 MKGC 模型在学习实体和关系嵌入时都会独立处理每个三元组,这会导致结构信息丢失。 由于KG中的实体通常与多个邻居实体链接,这可以为该实体的嵌入提供丰富的结构信息。 因此,在学习实体嵌入时独立处理每个三元组会导致丢失有关其邻域和知识图谱整体结构的信息。
动机图:
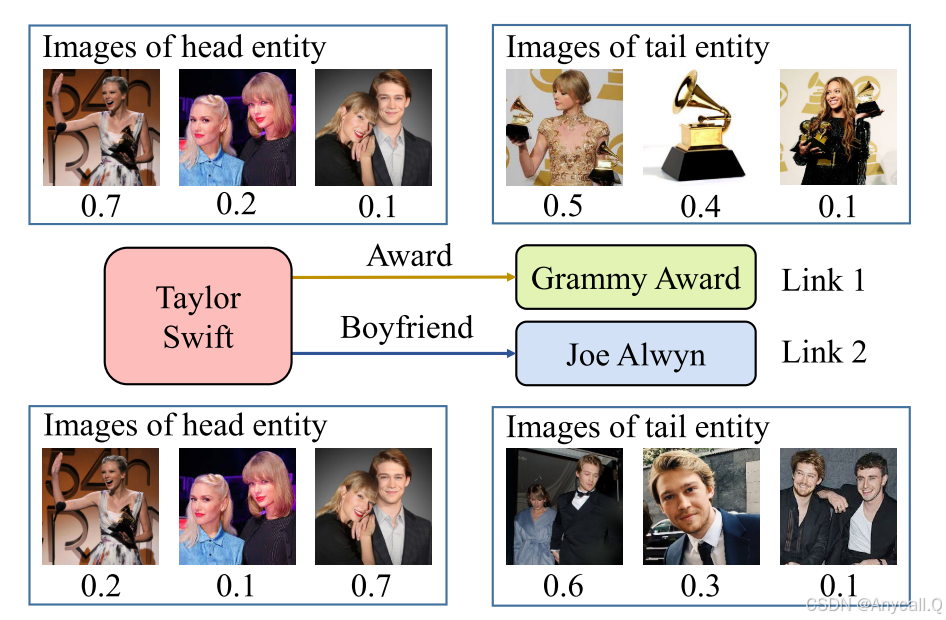
在图 1 中,实体 Taylor Swift 有许多关联图像,但它们在两个链接中的贡献是不同的。 尽管最近的工作如 RSME 和 MKGformer 考虑了计算图像的噪声,它们在融合视觉信息时针对独立实体而不是链接信息。
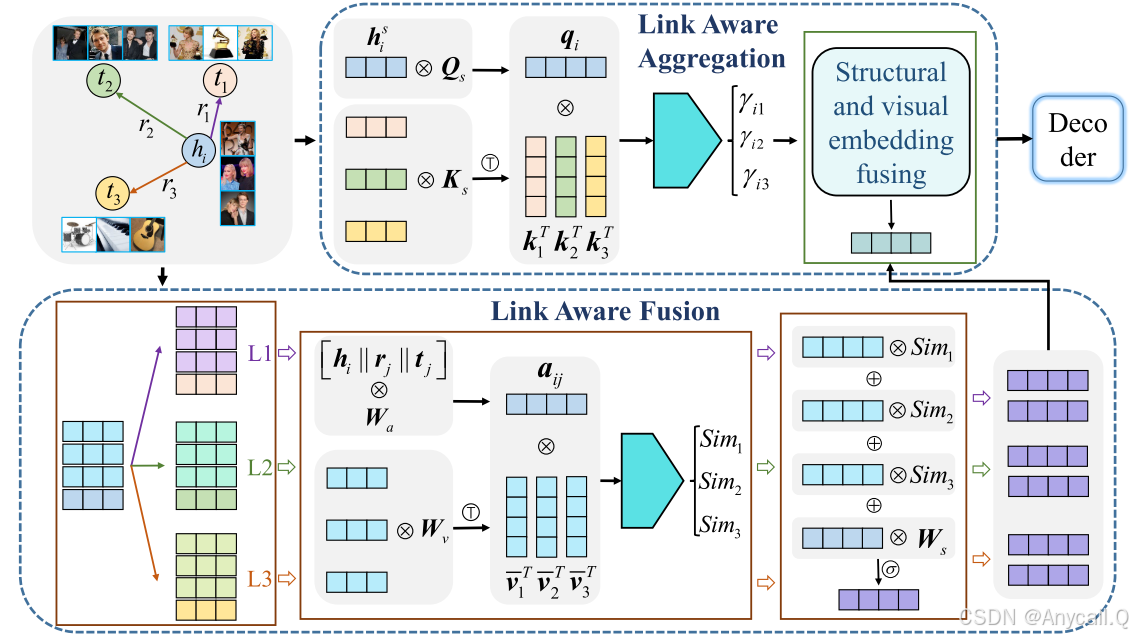
LAFA 由两个模块组成:链路感知融合和链路感知聚合,用于生成实体嵌入,以及用于链路预测的解码器。
解决方法:
为了缓解模态矛盾问题,链接感知融合模块根据链接信息计算实体与其关联图像之间的重要性,然后通过我们提出的模态嵌入融合机制融合视觉和结构嵌入,该机制执行线性组合 根据视觉嵌入的重要性,并将其与结构嵌入融合。
为了缓解结构信息缺失的问题,链接感知聚合模块计算给定中心实体与其邻居之间的重要性,然后根据重要性通过线性组合将邻居嵌入与视觉信息聚合,以将结构信息分配给中心实体 实体。
具体方法:
1、链接感知融合(Link Aware Fusion)
该模块设计了一种模态交互注意机制,根据链接信息动态衡量图像对实体嵌入的贡献,从而判断哪些图像是噪声,并设计了一种模态嵌入融合机制来融合视觉和结构嵌入。
(1)模态交互注意力(Modality Interaction Attention)
给定一个中心实体 hi 及其邻居实体集 ![]() ,我们首先随机初始化实体和关系的结构嵌入。 然后,我们定义一个视觉矩阵,将视觉嵌入投影到隐藏嵌入中,以实现维度统一和相似性匹配,如下所示:
,我们首先随机初始化实体和关系的结构嵌入。 然后,我们定义一个视觉矩阵,将视觉嵌入投影到隐藏嵌入中,以实现维度统一和相似性匹配,如下所示:
![]()
![]() ,dh 是隐藏嵌入的维度。
,dh 是隐藏嵌入的维度。
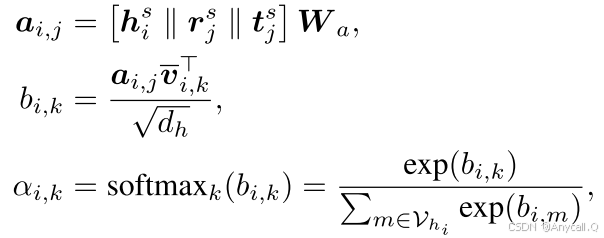
![]() 分别表示 头实体、 关系和尾实体的初始结构嵌入,ds是初始结构嵌入的维度,
分别表示 头实体、 关系和尾实体的初始结构嵌入,ds是初始结构嵌入的维度, ![]() 是可训练的线性变换矩阵;
是可训练的线性变换矩阵;
bi,k中除以根号下dh是一种常见的做法,目的是为了防止数值不稳定和梯度消失或爆炸问题;
αi,k ∈ [0, 1] 表示图像 vi,k 对实体 hi 的重要性, || 表示嵌入的串联。 αi,k 的值指示图像 vi,k 对于实体 hi 是否是噪声。 特别是,当 αi,k ≤ ψ 时,我们认为图像 vi,k 是噪声,其中 ψ 是预定义的阈值。
同理,计算尾实体相关图像集合中图像的重要性:
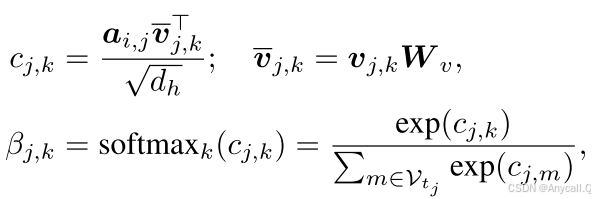
(2)模态嵌入融合(Modality Embedding Fusion)
模态交互注意力机制根据链接信息发现噪声图像。 与现有的 MKGC 方法不同,我们不直接去除这些噪声图像,而是根据上面计算的重要性对它们的视觉嵌入进行线性组合,然后融合视觉嵌入和结构嵌入。 这样做的动机是图像信息始终有助于学习实体嵌入。 对于实体 hi 和 tj,它们的三元组 (hi, rj, tj) 的视觉信息可以聚合如下:
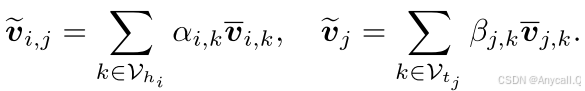
为了促进视觉嵌入和结构嵌入的融合,我们定义了一个结构矩阵,将实体 hi 和 tj 的结构嵌入投影到隐藏嵌入中,如下所示:
![]()
然后,包含三元组(hi,rj,tj)的视觉和结构信息的实体 hi 和 tj 的新嵌入可以如下融合:
![]()
此外,为了提高和稳定 LAFA 和学习过程的有效性,我们应用多头注意力机制来捕获来自不同参数的子空间信息。 具体来说,P 个独立的注意力头(乘以P个不同的投影矩阵)被用来学习嵌入,它们的输出被组合起来生成统一的表示。
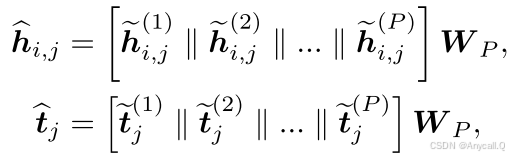
![]() 叫多模态融合嵌入。
叫多模态融合嵌入。
2、链路感知聚合(Link Aware Aggregation)
对于实体 hi,我们认为将其邻居实体的信息聚合到其嵌入中有助于提高表示质量。 因此,我们提出了一个链接感知聚合模块来将邻域结构信息聚合到中心实体。
对于中心实体 hi,我们首先定义一个查询矩阵,将 hi 的初始结构嵌入投影到查询向量中,并定义一个关键矩阵,将邻居实体的初始结构嵌入投影到关键向量中,如下所示:
![]()
其中 Qs ∈ Rds×dh 和 Ks ∈ Rds×dh 是可训练的查询和关键矩阵,![]() 是邻居实体,
是邻居实体,![]() 是 hi 的邻居实体集。 然后对查询向量qi和关键向量kj的点积进行softmax归一化,计算它们之间的注意力得分,如下:
是 hi 的邻居实体集。 然后对查询向量qi和关键向量kj的点积进行softmax归一化,计算它们之间的注意力得分,如下:
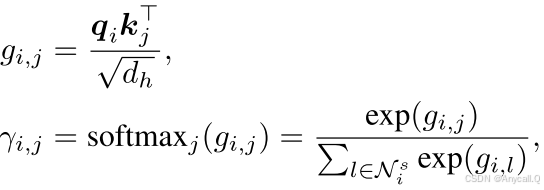
![]() 表示相邻实体tj对中心实体hi的重要性。当
表示相邻实体tj对中心实体hi的重要性。当![]() 时,实体tj被认为是噪声,
时,实体tj被认为是噪声,
我们将基于与中心实体hi相连的每个三元组,计算多个多模态融合嵌入hi。接下来,我们将根据以下方式对它们进行聚合,并结合结构信息:
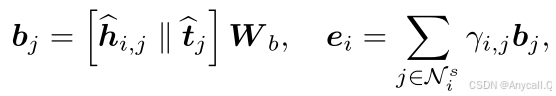
其中![]() 是根据第j个三元组(hi,ri,tj)计算的中心实体hi的多模态融合嵌入,t是实体ti的多模态融合嵌入
是根据第j个三元组(hi,ri,tj)计算的中心实体hi的多模态融合嵌入,t是实体ti的多模态融合嵌入
为了使模型能够集中于不同子空间的信息,提取更丰富的特征信息,我们采用了多头注意机制。 具体来说,我们使用Q个独立的注意头学习嵌入,然后将它们组合生成最终的中心实体的嵌入h / h,公式如下:
![]()
因此,整个KG的结构和视觉信息被聚合,并且可以生成高度多模态的上下文相关嵌入。
3、解码器(Decoder)
基于ConvE构建解码器
对于三元组(h, r, t),我们模型的评分函数可以定义为:
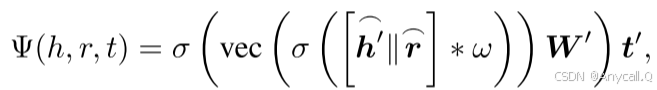
得分由sigmoid函数激活:
![]()
4、训练与优化(Training and Optimization)
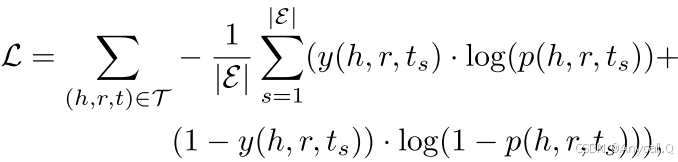
![]() 是三元组的标签,
是三元组的标签,![]() 为所有候选尾部实体的总数
为所有候选尾部实体的总数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









