






设计Attention Mask限定注意力范围的初衷主要有2个:
- Sparse Attention减少计算量,每个token只能看到附近的token等。
- 缓解训练和推理不一致,尤其是自回归的训练中,需要先生成前面的token,再生成后面的token。
纵坐标为query,横坐标为key,黄色部分表示每个query能看到哪几个key(即query要和哪些key算注意力权重)。
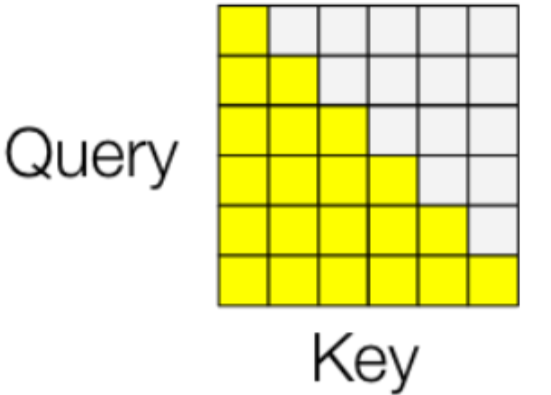
attn_weight矩阵本质上会告诉你每个 token 之间的相互作用强度,值汇总来自所有其他 token 的每个 token 的信息。例如Causal Mask理想情况下希望从矩阵的上三角中删除所有值。实现时并不是删除,而是用 -inf 替换它。这是因为当应用 softmax 时,这些极小的值将变为零,因此不会产生任何影响。attn_mask在q@k之后,softmax之前使用:
# Efficient implementation equivalent to the following:
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, scale=None) -> torch.Tensor:
L, S = query.size(-2), key.size(-2)
scale_factor = 1 / math.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype, device=query.device)
if attn_mask is not None:
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias = attn_mask + attn_bias
attn_weight = query @ key.transpose(-2, -1) * scale_factor
attn_weight += attn_bias # add attn bias as mask
attn_weight = torch.softmax(attn_weight, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value
Pre-train Mask
文本因果掩码(Text Causal Mask)
生成当前 token 时,只能看到自己和之前的 token。tril 返回输入矩阵的主对角线以下的下三角矩阵,其它元素全部置为0。
- 作用:LLM文本自回归,逐token生成。预训练文本生成任务。
import torch
import matplotlib.pyplot as plt
N = 16 # 序列长度
attn_mask = torch.tril(torch.ones(N, N))
print(attn_mask)
plt.figure(figsize=(4, 4))
plt.imshow(attn_mask.numpy(), cmap='Blues')
plt.title("Causal Mask: Yellow is True, Purple is False")
plt.axis('off')
plt.savefig('causal_mask.png')
plt.show()

tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
图生文掩码(I2T Mask)
image token可以看到彼此,后面生成的token是只能看到前面的所有token。
- 作用:预训练image caption任务。
import torch
import matplotlib.pyplot as plt
# 参数设置
N_image = 4 # 图像 token 的数量
N_text = 12 # 文本 token 的数量
N = N_image + N_text # 总序列长度
# 创建 i2t mask
i2t_mask = torch.zeros(N, N)
# 图像 token 可以相互看到
i2t_mask[:N_image, :N_image] = 1
# 文本 token 可以看到所有图像 token 和前面的文本 token(因果掩码)
text_mask = torch.tril(torch.ones(N_text, N_text))
i2t_mask[N_image:, :N_image] = 1 # 文本 token 可以看到所有图像 token
i2t_mask[N_image:, N_image:] = text_mask # 文本 token 是因果的
# 可视化
plt.figure(figsize=(4, 4))
plt.imshow(i2t_mask.numpy())
plt.title("Image tokens see each other,\n text tokens are causal")
plt.axis('off')
plt.savefig('i2t_mask.png')
plt.show()

tensor([[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
文生图掩码(T2I Mask)
文本 token因果生成,每个文本 token 只能看到前面的文本 token。图像 token可以相互看到,不受因果限制。
- 作用:预训练文生图任务。
import torch
import matplotlib.pyplot as plt
# 参数设置
N_text = 12 # 文本 token 的数量
N_image = 4 # 图像 token 的数量
N = N_text + N_image # 总序列长度
# 创建文生图掩码
t2i_mask = torch.zeros(N, N)
# 文本 token 是因果的
text_mask = torch.tril(torch.ones(N_text, N_text))
t2i_mask[:N_text, :N_text] = text_mask # 文本 token 是因果的
# 图像 token 可以相互看到
image_mask = torch.ones(N_image, N_image)
t2i_mask[N_text:, N_text:] = image_mask # 图像 token 可以相互看到
# 图像 token 可以看到所有文本 token
t2i_mask[N_text:, :N_text] = 1 # 图像 token 可以看到所有文本 token
print(t2i_mask)
# 可视化
plt.figure(figsize=(6, 6))
plt.imshow(t2i_mask.numpy())
plt.title("T2I Mask: Text tokens are causal,\n Image tokens see each other")
plt.axis('off')
plt.savefig('t2i_mask.png')
plt.show()

tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
视频帧因果掩码(Video Frame Causal Mask)
因果块掩码结合了因果掩码和块掩码的特性。每个块内部的 token 可以相互看见,后面块的 token 可以看到前面所有块的 token。
- 作用:视频帧自回归生成预训练,当前帧的token可以看到前面所有帧的token。
import torch
import matplotlib.pyplot as plt
N = 16 # 序列长度
block_size = 4 # 每个块的大小
num_blocks = N // block_size
# 创建因果掩码
causal_mask = torch.tril(torch.ones(N, N))
# 创建块掩码
block_mask = torch.block_diag(*[torch.ones(block_size, block_size)] * num_blocks)
# 结合因果掩码和块掩码
causal_block_mask = (causal_mask + block_mask) > 0.5
causal_block_mask = causal_block_mask.to(torch.float)
print(causal_block_mask)
plt.figure(figsize=(4, 4))
plt.imshow(causal_block_mask.numpy())
plt.title("Causal Block Mask: Yellow is True, Purple is False")
plt.axis('off')
plt.savefig('causal_block_mask.png')
plt.show()

tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1.]])
视频生文掩码(V2T Mask)
序列中先video token后text token。视频帧内token可以相互看见,当前视频帧token可以看到前面所有帧的token,生成的文本token可以看到前面所有帧的token和前面生成的text token。
- 作用:预训练video caption任务。
import torch
import matplotlib.pyplot as plt
# 参数设置
N_frame = 4 # 视频帧的数量
N_video_per_frame = 4 # 每个帧内的视频 token 数量
N_text = 8 # 文本 token 的数量
N_video = N_frame * N_video_per_frame # 总视频 token 数量
N = N_video + N_text # 总序列长度
# 创建视频生文掩码
v2t_mask = torch.zeros(N, N)
# 视频帧内的 token 可以相互看见
for i in range(N_frame):
start = i * N_video_per_frame
end = start + N_video_per_frame
v2t_mask[start:end, start:end] = 1 # 当前帧内的 token 可以相互看见
# 当前视频帧的 token 可以看到前面所有帧的 token
for i in range(1, N_frame):
start = i * N_video_per_frame
end = start + N_video_per_frame
v2t_mask[start:end, :start] = 1 # 当前帧的 token 可以看到前面所有帧的 token
# 文本 token 可以看到前面所有帧的 token 和前面生成的文本 token
text_mask = torch.tril(torch.ones(N_text, N_text))
v2t_mask[N_video:, :N_video] = 1 # 文本 token 可以看到前面所有帧的 token
v2t_mask[N_video:, N_video:] = text_mask # 文本 token 是因果的
print(v2t_mask)
# 可视化
plt.figure(figsize=(6, 6))
plt.imshow(v2t_mask.numpy())
plt.title("V2T Mask: Video tokens see each other,\n Text tokens are causal")
plt.axis('off')
plt.savefig('v2t_mask.png')
plt.show()

tensor([[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.]])
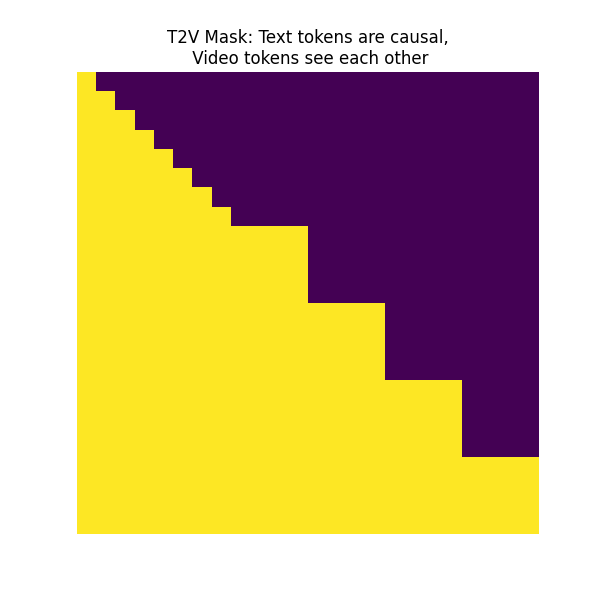
文生视频掩码(T2V Mask)
序列中先text token后video token。生成的文本token可以看到前面生成的text token。视频帧内token可以相互看见,当前视频帧token可以看到前面的文本token以及前面生成的所有帧的token。
- 作用:预训练文生图任务。
import torch
import matplotlib.pyplot as plt
# 参数设置
N_frame = 4 # 视频帧的数量
N_video_per_frame = 4 # 每个帧内的视频 token 数量
N_text = 8 # 文本 token 的数量
N_video = N_frame * N_video_per_frame # 总视频 token 数量
N = N_text + N_video # 总序列长度
# 创建文生视频掩码
t2v_mask = torch.zeros(N, N)
# 文本 token 是因果的
text_mask = torch.tril(torch.ones(N_text, N_text))
t2v_mask[:N_text, :N_text] = text_mask # 文本 token 是因果的
# 视频帧内的 token 可以相互看见
for i in range(N_frame):
start = N_text + i * N_video_per_frame
end = start + N_video_per_frame
t2v_mask[start:end, start:end] = 1 # 当前帧内的 token 可以相互看见
# 当前视频帧的 token 可以看到前面的文本 token 以及前面生成的所有帧的 token
for i in range(0, N_frame):
start = N_text + i * N_video_per_frame
end = start + N_video_per_frame
t2v_mask[start:end, :start] = 1 # 当前帧的 token 可以看到前面的文本 token 和前面所有帧的 token
print(t2v_mask)
# 可视化
plt.figure(figsize=(6, 6))
plt.imshow(t2v_mask.numpy())
plt.title("T2V Mask: Text tokens are causal,\n Video tokens see each other")
plt.axis('off')
plt.savefig('t2v_mask.png')
plt.show()
SFT 前缀掩码(SFT Prefix Mask)
所有的多模态提示信息(image/video/text instruction)都是Prefix,前缀token可以看到彼此,后面生成的token是只能看到前面的所有token。
import torch
import matplotlib.pyplot as plt
# 参数设置
N_prefix = 8 # 前缀 token 的数量
N_text1 = 8 # 第一部分文本 token 的数量
N_image = 4 # 图像 token 的数量
N_text2 = 8 # 第二部分文本 token 的数量
N_frame = 4 # 视频帧的数量
N_video_per_frame = 4 # 每帧的视频 token 数量
N_video = N_frame * N_video_per_frame # 总视频 token 数量
N = N_prefix + N_text1 + N_image + N_text2 + N_video # 总序列长度
# 创建 SFT 前缀掩码
sft_mask = torch.zeros(N, N)
# 前缀 token 可以看到彼此
sft_mask[:N_prefix, :N_prefix] = 1
# 第一部分文本 token 是因果的,可以看到前面的前缀 token
text1_mask = torch.tril(torch.ones(N_text1, N_text1))
sft_mask[N_prefix:N_prefix+N_text1, :N_prefix] = 1
sft_mask[N_prefix:N_prefix+N_text1, N_prefix:N_prefix+N_text1] = text1_mask
# 图像 token 可以看到前面的所有 token,并且图像 token 之间可以看到彼此
sft_mask[N_prefix+N_text1:N_prefix+N_text1+N_image, :N_prefix+N_text1] = 1
sft_mask[N_prefix+N_text1:N_prefix+N_text1+N_image, N_prefix+N_text1:N_prefix+N_text1+N_image] = 1
# 第二部分文本 token 是因果的,可以看到前面的所有 token
text2_mask = torch.tril(torch.ones(N_text2, N_text2))
sft_mask[N_prefix+N_text1+N_image:N_prefix+N_text1+N_image+N_text2, :N_prefix+N_text1+N_image] = 1
sft_mask[N_prefix+N_text1+N_image:N_prefix+N_text1+N_image+N_text2, N_prefix+N_text1+N_image:N_prefix+N_text1+N_image+N_text2] = text2_mask
# 视频 token 采用视频因果掩码
for i in range(N_frame):
start = N_prefix + N_text1 + N_image + N_text2 + i * N_video_per_frame
end = start + N_video_per_frame
# 当前帧的 token 可以看到前面的所有 token
sft_mask[start:end, :start] = 1
# 当前帧内的 token 可以相互看见
sft_mask[start:end, start:end] = 1
# 可视化
plt.figure(figsize=(10, 10))
plt.imshow(sft_mask.numpy())
plt.title("SFT Prefix Mask: Prefix tokens see each other,\n Generated tokens are causal")
plt.axis('off')
plt.savefig('sft_prefix_mask.png')
plt.show()
支持多模态输出:序列中,前缀token 8个,接着是8个text token(因果生成),可以看到前面全部token;然后是4个image token,不仅image token之间可以看到彼此,而且可以看到前面全部token;然后又是8个text token(因果生成),可以看到前面全部token;最后是4帧每帧4个的video token,采用视频因果掩码。

tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,
0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.]])



















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











