






本文主要仔细探索image VQGAN的模型结构和Video VQGAN的模型结构,都是主要包含Encoder、Decoder、VectorQuant、Discriminator。
- ResnetBlocb
不会改变spatial维度的大小(Conv1/2/3D的stride=1,kernel=3,pad=1或kernel=1,pad=0) - Downsample
会改变spatial/temporal维度的大小(Conv1/2/3D的stride=2或AvgPool的stride=2)
VideoVAE+ (VideoVAE)
主要学video encoder和decoder的架构设计
(VAE连续的latent,没有VQ操作。)AutoEncoder结构是采用先包含3D CNN的spatial encoder(进行spatial和temporal维度的联合建模,但只压缩spatial维度,不压缩temporal维度),再进行3D CNN的temporal encoder(压缩temporal)。Decoder是Encoder的对称结构不用细说。
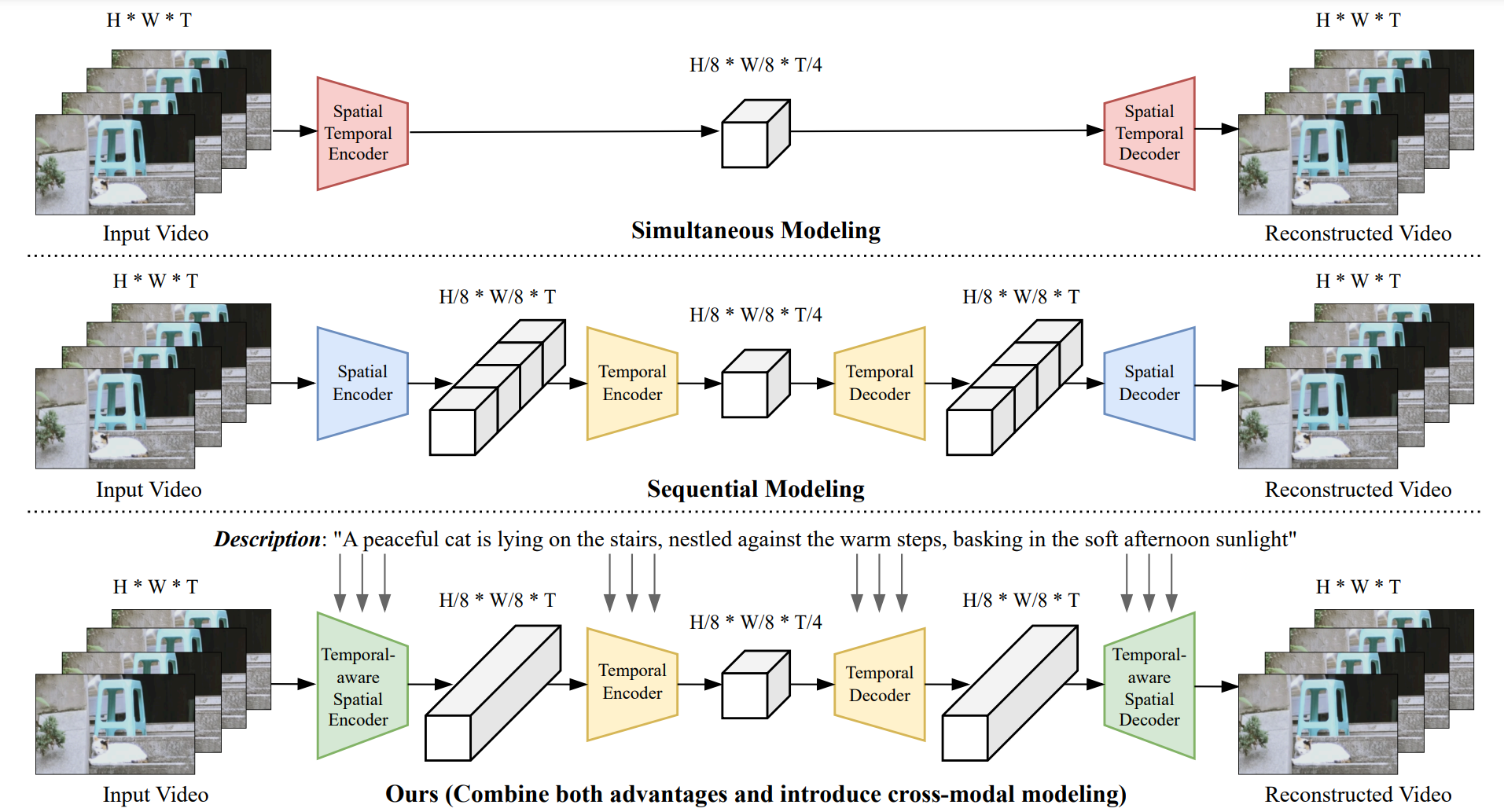
Video Modeling:casual temporal modeling after spatial modeling + corss-modal guidance
-
add temporal layer in 2D VAE(inflate 2D to 3D): inherit the weight from pre-trained2D VAE is to inflate the 2D spatial blocks to 3D temporal blocks and simultaneously do the spatial and temporal: replace the 2D convolution in SD VAE with 3D convolution of kernel size (1,3,3), inherit initial weights. Add an additional temporal convolution layer with kernel size (3,3,3) to learn spatiotemporal patterns. 继承image vae的先验,spatial重建效果好。
-
add temopral encoder/decoder after 2D VAE: first utilize the 2D VAE to compress the input video frame-by-frame, and then learn a temporal autoencoding process to further compress the temporal redundancy. 比1的large motion的temporal压缩效果更好,但是不擅长恢复spatial细节。
-
combine 1 and 2: inflate the 2D convolution to 3D convolution with kernel size (1,3,3), and similarly to option 1, we add additional
temporal convolution layers through 3D convolution. We denote our first-stage model as a temporal-aware spatial autoencoder. Different from option 1, we only compress the spatial information and do not compress the temporal information at the first stage, but introduce another temporal encoder to further encode the temporal dimensions, which serves as the second stage compression. 第一个encoder只压缩spatial,同时建模但不压缩temporal。
train image input时, treat these images as independent static frames,直接关闭 temporal-attn和temporal encoder即可。 train data采用 8:2 video-to-image ratio。
Temporal-Aware Spatial Encoder(Encoder2plus1D)
输入的frames的形状是[b, c, t, h, w]
z_channels: 16
resolution: 216
in_channels: 3
out_ch: 3
ch: 128
ch_mult: [1, 2, 4, 4] # spatial resolutions(channel mults)
temporal_down_factor: 1 # 不压缩temporal维度
num_res_blocks: 2 # 每个Encoder和Decoder的block中插入 几个 ResnetBlock
attn_resolutions: [] # 指定Encoder和Decoder的 哪些 block中插入 AttnBlock(self-attention)
- 将
conv_in的Conv2d改为Conv3d; - 将
ResnetBlock中的Conv2d和conv_in一样改为Conv3d,同时在每个conv3d后面插入一个TemporalConvLayer,TemporalConvLayer- 是使用Conv3d对temporal和spatial进行联合建模,kernel_size=(3, 3, 3)表示,卷积操作不仅会聚合帧内的spatial特征,还会聚合帧间的temporal特征!;去掉所有的SelfAttn,并在ResnetBlock后插入CorssAttn。 - 在
mid中除了改为conv3d和SelfAttn(将[b,c,t,h,w]->[(b,t),c,(h,w)]),还插入了TemporalAttention(将[b,c,t,h,w]->[(b,h,w),c,t]),进行时序建模。
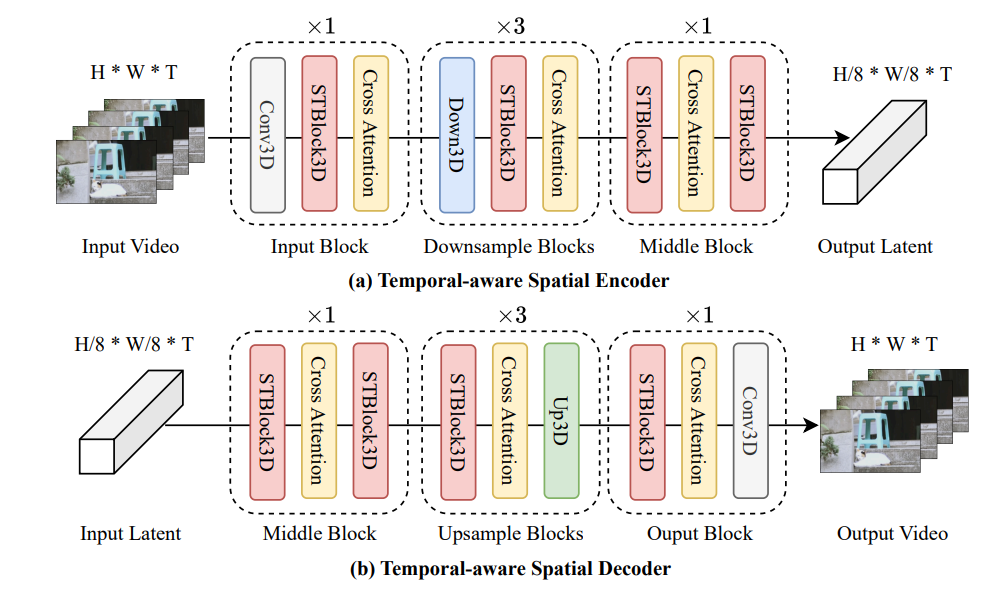
- conv_in:将原始的
Conv2d改为Conv3d,卷积核大小kernel从(h,w)=(3, 3)改为(t,h,w)=(1, 3, 3)。使得可以适配video frames数据,但因为kernel的temporal维度的kernel size=1,卷积操作不会在时间维度上跨越多个帧,因此不进行时序建模。padding从(1,1)改为(0, 1, 1),也就是不对temporal维度进行padding。
- downsample blocks:将其中的ResnetBlock改为
ResnetBlock2plus1D,并插入CrossAttention实现t5的text_embedding与image feature交互。Downsample改为Downsample2plus1D。 - mid block:包含
ResnetBlock2plus1D和AttnBlock3D和TemporalAttention和ResnetBlock2plus1D。其中除了改为conv3d和SelfAttn(将[b,c,t,h,w]->[(b,t),c,(h,w)]),还插入了TemporalAttention(将[b,c,t,h,w]->[(b,h,w),c,t]),进行时序建模。
ResnetBlock
原始的ResnetBlock是3个Conv2d组成的:
class ResnetBlock(nn.Module):
def __init__(
self,
*,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout,
temb_channels=512,
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm1 = Normalize(in_channels)
self.conv1 = torch.nn.Conv2d(
in_channels, out_channels, kernel_size=3, stride=1, padding=1
)
if temb_channels > 0:
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
self.norm2 = Normalize(out_channels)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = torch.nn.Conv2d(
out_channels, out_channels, kernel_size=3, stride=1, padding=1
)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = torch.nn.Conv2d(
in_channels, out_channels, kernel_size=3, stride=1, padding=1
)
else:
self.nin_shortcut = torch.nn.Conv2d(
in_channels, out_channels, kernel_size=1, stride=1, padding=0
)
def forward(self, x, temb):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
return x + h
现在的ResnetBlock2plus1D,不仅将ResnetBlock中的Conv2d和conv_in一样改为Conv3d,同时在每个conv3d后面插入一个TemporalConvLayer。
class ResnetBlock2plus1D(nn.Module):
def __init__(
self,
*,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout,
temb_channels=512,
kernel_size_t=3,
padding_t=1,
stride_t=1,
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm1 = Normalize(in_channels)
self.conv1 = torch.nn.Conv3d(
in_channels,
out_channels,
kernel_size=(1, 3, 3),
stride=1,
padding=(0, 1, 1),
)
self.conv1_tmp = TemporalConvLayer(out_channels, out_channels)
if temb_channels > 0:
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
self.norm2 = Normalize(out_channels)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = torch.nn.Conv3d(
out_channels,
out_channels,
kernel_size=(1, 3, 3),
stride=1,
padding=(0, 1, 1),
)
self.conv2_tmp = TemporalConvLayer(out_channels, out_channels)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = torch.nn.Conv3d(
in_channels,
out_channels,
kernel_size=(1, 3, 3),
stride=1,
padding=(0, 1, 1),
)
else:
self.nin_shortcut = torch.nn.Conv3d(
in_channels,
out_channels,
kernel_size=(1, 1, 1),
stride=1,
padding=(0, 0, 0),
)
self.conv3_tmp = TemporalConvLayer(out_channels, out_channels)
def forward(self, x, temb, mask_temporal=False):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if not mask_temporal:
h = self.conv1_tmp(h) + h
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if not mask_temporal:
h = self.conv2_tmp(h) + h
# skip connections
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
if not mask_temporal:
x = self.conv3_tmp(x) + x
return x + h
TemporalConvLayer是使用Conv3d对temporal和spatial进行联合建模,kernel_size=(3, 3, 3)表示,卷积操作不仅会聚合帧内的spatial特征,还会聚合帧间的temporal特征!
class TemporalConvLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.norm = Normalize(in_channels)
self.conv = torch.nn.Conv3d(
in_channels,
out_channels,
kernel_size=(3, 3, 3),
stride=1,
padding=(1, 1, 1),
)
nn.init.constant_(self.conv.weight, 0)
nn.init.constant_(self.conv.bias, 0)
def forward(self, x):
h = x
h = self.norm(h)
h = nonlinearity(h)
h = self.conv(h)
return h
Downsample
原始的Downsample是使用stride=2的Conv2d实现spatial维度的2倍下采样。在卷积操作中,由于步长为2,如果不进行任何填充,输出的宽度和高度将正好减半。但是,这种“硬”下采样可能会导致边界信息的丢失。为了缓解这个问题,代码中通过在宽度两侧各添加1个像素的0 padding,来模拟不对称的填充效果,这有助于保持边界信息。
class Downsample(nn.Module):
def __init__(self, in_channels, with_conv):
super().__init__()
self.with_conv = with_conv
self.in_channels = in_channels
if self.with_conv:
# no asymmetric padding in torch conv, must do it ourselves
self.conv = torch.nn.Conv2d(
in_channels, in_channels, kernel_size=3, stride=2, padding=0
)
def forward(self, x):
if self.with_conv:
pad = (0, 1, 0, 1)
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
x = self.conv(x)
else:
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
return x
扩展为视频的Downsample2plus1D,就是使用kernel_size=(1, 3, 3),stride=(1, 2, 2)的Conv3d,在temporal维度的stride=1,卷积核滑动的步长是1。也不进行temporal维度的padding。
class Downsample2plus1D(nn.Module):
"""spatial downsample, in a factorized way"""
def __init__(self, in_channels, with_conv, temp_down):
super().__init__()
self.with_conv = with_conv
self.in_channels = in_channels
self.temp_down = temp_down
if self.with_conv:
# no asymmetric padding in torch conv, must do it ourselves
self.conv = torch.nn.Conv3d(
in_channels,
in_channels,
kernel_size=(1, 3, 3),
stride=(1, 2, 2),
padding=0,
)
def forward(self, x, mask_temporal):
if self.with_conv:
pad = (0, 1, 0, 1, 0, 0)
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
x = self.conv(x)
# print(f'[Encoder-Downsample] after conv={x.shape}')
# print(f'[Encoder-Downsample] after conv_tmp={x.shape}')
else:
raise NotImplementedError
# x = torch.nn.functional.avg_pool3d(x, kernel_size=2, stride=2)
return x
TemporalAttention
在mid中额外插入的,进行temporal self attention(将[b,c,t,h,w]->[(b,h,w),c,t]),进行时序建模。
class TemporalAttention(nn.Module):
def __init__(
self,
channels,
num_heads=1,
num_head_channels=-1,
max_temporal_length=64,
):
"""
a clean multi-head temporal attention
"""
super().__init__()
if num_head_channels == -1:
self.num_heads = num_heads
else:
assert (
channels % num_head_channels == 0
), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
self.num_heads = channels // num_head_channels
self.norm = normalization(channels)
self.qkv = zero_module(conv_nd(1, channels, channels * 3, 1))
self.attention = QKVAttention(self.num_heads)
self.relative_position_k = RelativePosition(
num_units=channels // self.num_heads,
max_relative_position=max_temporal_length,
)
self.relative_position_v = RelativePosition(
num_units=channels // self.num_heads,
max_relative_position=max_temporal_length,
)
self.proj_out = zero_module(
conv_nd(1, channels, channels, 1)
) # conv_dim, in_channels, out_channels, kernel_size
def forward(self, x, mask=None):
b, c, t, h, w = x.shape
out = rearrange(x, "b c t h w -> (b h w) c t") # to [batch, seq_len, emb_dim]
qkv = self.qkv(self.norm(out))
len_q = qkv.size()[-1]
len_k, len_v = len_q, len_q
k_rp = self.relative_position_k(len_q, len_k)
v_rp = self.relative_position_v(len_q, len_v) # [T,T,head_dim]
out = self.attention(qkv, rp=(k_rp, v_rp))
out = self.proj_out(out)
out = rearrange(out, "(b h w) c t -> b c t h w", b=b, h=h, w=w)
return x + out
Temporal Encoder
额外进行的Temporal维度的建模和压缩:
temporal_scale_factor: 4
z_channels: 16
out_ch: 16
ch: 16
attn_temporal_factor: [] # down的哪些层有attn
conv_in + (resblock + down_block) + (resblock + down_block) + final_block
- 根据
temporal_scale_factor得到num_ds(temporal压缩的downsample的次数,每次在temporal维度进行2倍压缩)
- conv_in:
kernel_size=(3,3,3)的Conv3d进行时刻联合建模,stride=1,不压缩。改变channel。 - mid_blocks:
down中的Conv3d的kernel_size=(3,3,3),stride=(temporal_stride=2, 1, 1), 在temporal维度进行2倍压缩。res中的Conv3d的kernel_size=(3,3,3)的Conv3d进行时刻联合建模,stride=1,不压缩。 - final_block:
kernel_size=(3,3,3)的Conv3d进行时刻联合建模,stride=1,不压缩。改变channel。
class EncoderTemporal1DCNN(nn.Module):
def __init__(
self,
*,
ch,
out_ch,
attn_temporal_factor=[],
temporal_scale_factor=4,
hidden_channel=128,
**ignore_kwargs
):
super().__init__()
self.ch = ch
self.temb_ch = 0
self.temporal_scale_factor = temporal_scale_factor
# conv_in + resblock + down_block + resblock + down_block + final_block
self.conv_in = SamePadConv3d(
ch, hidden_channel, kernel_size=3, padding_type="replicate"
)
self.mid_blocks = nn.ModuleList()
num_ds = int(math.log2(temporal_scale_factor))
norm_type = "group"
curr_temporal_factor = 1
for i in range(num_ds):
block = nn.Module()
# compute in_ch, out_ch, stride
in_channels = hidden_channel * 2**i
out_channels = hidden_channel * 2 ** (i + 1)
temporal_stride = 2
curr_temporal_factor = curr_temporal_factor * 2
block.down = SamePadConv3d(
in_channels,
out_channels,
kernel_size=3,
stride=(temporal_stride, 1, 1),
padding_type="replicate",
)
block.res = ResBlock(out_channels, out_channels, norm_type=norm_type)
block.attn = nn.ModuleList()
if curr_temporal_factor in attn_temporal_factor:
block.attn.append(
SpatialCrossAttention(query_dim=out_channels, context_dim=1024)
)
self.mid_blocks.append(block)
# n_times_downsample -= 1
self.final_block = nn.Sequential(
Normalize(out_channels, norm_type),
SiLU(),
SamePadConv3d(
out_channels, out_ch * 2, kernel_size=3, padding_type="replicate"
),
)
self.initialize_weights()
def initialize_weights(self):
# Initialize transformer layers:
def _basic_init(module):
if isinstance(module, nn.Linear):
if module.weight.requires_grad_:
torch.nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
if isinstance(module, nn.Conv3d):
torch.nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
self.apply(_basic_init)
def forward(self, x, text_embeddings=None, text_attn_mask=None):
# x: [b c t h w]
# x: [1, 4, 16, 32, 32]
# timestep embedding
h = self.conv_in(x)
for block in self.mid_blocks:
h = block.down(h)
h = block.res(h)
if len(block.attn) > 0:
for attn in block.attn:
h = attn(h, context=text_embeddings, mask=text_attn_mask) + h
h = self.final_block(h)
return h
SamePadConv3d
class SamePadConv3d(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
bias=True,
padding_type="replicate",
):
super().__init__()
if isinstance(kernel_size, int):
kernel_size = (kernel_size,) * 3
if isinstance(stride, int):
stride = (stride,) * 3
# assumes that the input shape is divisible by stride
total_pad = tuple([k - s for k, s in zip(kernel_size, stride)])
pad_input = []
for p in total_pad[::-1]: # reverse since F.pad starts from last dim
pad_input.append((p // 2 + p % 2, p // 2))
pad_input = sum(pad_input, tuple())
self.pad_input = pad_input
self.padding_type = padding_type
self.conv = nn.Conv3d(
in_channels, out_channels, kernel_size, stride=stride, padding=0, bias=bias
)
def forward(self, x):
# print(x.dtype)
return self.conv(F.pad(x, self.pad_input, mode=self.padding_type))
ResBlock
class ResBlock(nn.Module):
def __init__(
self,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout=0.0,
norm_type="group",
padding_type="replicate",
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm1 = Normalize(in_channels, norm_type)
self.conv1 = SamePadConv3d(
in_channels, out_channels, kernel_size=3, padding_type=padding_type
)
self.dropout = torch.nn.Dropout(dropout)
self.norm2 = Normalize(in_channels, norm_type)
self.conv2 = SamePadConv3d(
out_channels, out_channels, kernel_size=3, padding_type=padding_type
)
if self.in_channels != self.out_channels:
self.conv_shortcut = SamePadConv3d(
in_channels, out_channels, kernel_size=3, padding_type=padding_type
)
def forward(self, x):
h = x
h = self.norm1(h)
h = silu(h)
h = self.conv1(h)
h = self.norm2(h)
h = silu(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
x = self.conv_shortcut(x)
return x + h
Loss
Loss部分基本没有变化,其他的loss直接将将video看成多个frames处理:[b,c,t,h,w]->[(b,t),c,h,w]。
- 只是换了
Discriminator3D用于处理video数据计算logits(一般默认PatchGANDiscriminator),GAN loss的generator_adv_loss和disc_loss都默认使用hinge函数。
class LPIPSWithDiscriminator3D(nn.Module):
def __init__(
self,
disc_start,
logvar_init=0.0,
kl_weight=1.0,
pixelloss_weight=1.0,
perceptual_weight=1.0,
# --- Discriminator Loss ---
disc_num_layers=3,
disc_in_channels=3,
disc_factor=1.0,
disc_weight=1.0,
use_actnorm=False,
disc_conditional=False,
disc_loss="hinge",
):
super().__init__()
assert disc_loss in ["hinge", "vanilla"]
self.kl_weight = kl_weight
self.pixel_weight = pixelloss_weight
self.perceptual_loss = LPIPS().eval()
self.perceptual_weight = perceptual_weight
self.logvar = nn.Parameter(torch.ones(size=()) * logvar_init)
self.discriminator = NLayerDiscriminator3D(
input_nc=disc_in_channels, n_layers=disc_num_layers, use_actnorm=use_actnorm
).apply(weights_init)
self.discriminator_iter_start = disc_start
self.disc_loss = hinge_d_loss if disc_loss == "hinge" else vanilla_d_loss
self.disc_factor = disc_factor
self.discriminator_weight = disc_weight
self.disc_conditional = disc_conditional
def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
if last_layer is not None:
nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
else:
nll_grads = torch.autograd.grad(
nll_loss, self.last_layer[0], retain_graph=True
)[0]
g_grads = torch.autograd.grad(
g_loss, self.last_layer[0], retain_graph=True
)[0]
d_weight = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
d_weight = torch.clamp(d_weight, 0.0, 1e4).detach()
d_weight = d_weight * self.discriminator_weight
return d_weight
def forward(
self,
inputs,
reconstructions,
posteriors,
optimizer_idx,
global_step,
split="train",
weights=None,
last_layer=None,
cond=None,
):
t = inputs.shape[2]
inputs = rearrange(inputs, "b c t h w -> (b t) c h w")
reconstructions = rearrange(reconstructions, "b c t h w -> (b t) c h w")
## 1. NLL Loss = Rec_L1 loss + LPIPS loss
# 2D Rec_L1 loss
rec_loss = torch.abs(inputs.contiguous() - reconstructions.contiguous())
# 2D LPIPS loss
if self.perceptual_weight > 0:
p_loss = self.perceptual_loss(
inputs.contiguous(), reconstructions.contiguous()
)
# Rec loss = Rec_L1 loss + LPIPS loss
rec_loss = rec_loss + self.perceptual_weight * p_loss
# Norm Rec loss
nll_loss = rec_loss / torch.exp(self.logvar) + self.logvar
weighted_nll_loss = nll_loss
if weights is not None:
weighted_nll_loss = weights * nll_loss
weighted_nll_loss = torch.sum(weighted_nll_loss) / weighted_nll_loss.shape[0]
# Nll loss = Avg(weighted_all_nll_loss for batch and temporal)
nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
## 2. KL loss = posteriors loss for guassin distribution
kl_loss = posteriors.kl()
kl_loss = torch.sum(kl_loss) / kl_loss.shape[0]
## 3. When iter < discriminator_iter_start, 不计算GAN loss: Total loss = NLL Loss + KL loss
if global_step < self.discriminator_iter_start:
loss = weighted_nll_loss + self.kl_weight * kl_loss
log = {
"{}/total_loss".format(split): loss.clone().detach().mean(),
"{}/logvar".format(split): self.logvar.detach(),
"{}/kl_loss".format(split): kl_loss.detach().mean(),
"{}/nll_loss".format(split): nll_loss.detach().mean(),
"{}/rec_loss".format(split): rec_loss.detach().mean(),
}
return loss, log
inputs = rearrange(inputs, "(b t) c h w -> b c t h w", t=t)
reconstructions = rearrange(reconstructions, "(b t) c h w -> b c t h w", t=t)
## 4. When iter >= discriminator_iter_start, 计算GAN loss
## 4.1 GAN loss = ADV loss = -mean(logits_fake)
if optimizer_idx == 0: # for generator update
if cond is None:
assert not self.disc_conditional
logits_fake = self.discriminator(reconstructions.contiguous())
else:
assert self.disc_conditional
logits_fake = self.discriminator(
torch.cat((reconstructions.contiguous(), cond), dim=1)
)
g_loss = -torch.mean(logits_fake)
if self.disc_factor > 0.0:
try:
d_weight = self.calculate_adaptive_weight(
nll_loss, g_loss, last_layer=last_layer
)
except RuntimeError as e:
assert not self.training, print(e)
d_weight = torch.tensor(0.0)
else:
d_weight = torch.tensor(0.0)
disc_factor = adopt_weight(
self.disc_factor, global_step, threshold=self.discriminator_iter_start
)
loss = (
weighted_nll_loss
+ self.kl_weight * kl_loss
+ d_weight * disc_factor * g_loss
)
log = {
"{}/total_loss".format(split): loss.clone().detach().mean(),
"{}/logvar".format(split): self.logvar.detach(),
"{}/kl_loss".format(split): kl_loss.detach().mean(),
"{}/nll_loss".format(split): nll_loss.detach().mean(),
"{}/rec_loss".format(split): rec_loss.detach().mean(),
"{}/d_weight".format(split): d_weight.detach(),
"{}/disc_factor".format(split): torch.tensor(disc_factor),
"{}/g_loss".format(split): g_loss.detach().mean(),
}
return loss, log
## 4.2 GAN loss = Discriminator loss = disc_loss['hinge'](logits_real, logits_fake)
if optimizer_idx == 1: # for discriminator update
if cond is None:
logits_real = self.discriminator(inputs.contiguous().detach())
logits_fake = self.discriminator(reconstructions.contiguous().detach())
else:
logits_real = self.discriminator(
torch.cat((inputs.contiguous().detach(), cond), dim=1)
)
logits_fake = self.discriminator(
torch.cat((reconstructions.contiguous().detach(), cond), dim=1)
)
disc_factor = adopt_weight(
self.disc_factor, global_step, threshold=self.discriminator_iter_start
)
d_loss = disc_factor * self.disc_loss(logits_real, logits_fake)
log = {
"{}/disc_loss".format(split): d_loss.clone().detach().mean(),
"{}/logits_real".format(split): logits_real.detach().mean(),
"{}/logits_fake".format(split): logits_fake.detach().mean(),
}
return d_loss, log
PatchDiscriminator3D(NLayerDiscriminator3D)
可以看出使用Video的计算loss比Image的效果要好。
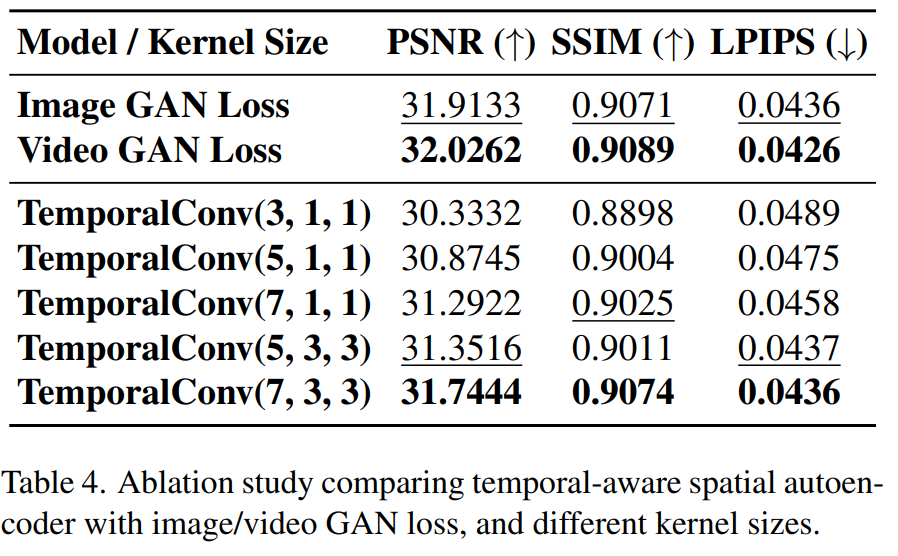
PatchDiscriminator3D(NLayerDiscriminator3D)比原始的PatchDiscriminator(NLayerDiscriminator):
- BatchNorm2d改成
BatchNorm3d - Conv2d改为
Conv3d,kernel_size从(4,4,4)改成(3,3,3)
class NLayerDiscriminator(nn.Module):
"""Defines a PatchGAN discriminator as in Pix2Pix
--> see https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py
"""
def __init__(self, input_nc=3, ndf=64, n_layers=3, use_actnorm=False):
"""Construct a PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the last conv layer
n_layers (int) -- the number of conv layers in the discriminator
norm_layer -- normalization layer
"""
super(NLayerDiscriminator, self).__init__()
if not use_actnorm:
norm_layer = nn.BatchNorm2d
else:
norm_layer = ActNorm
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func != nn.BatchNorm2d
else:
use_bias = norm_layer != nn.BatchNorm2d
kw = 4
padw = 1
sequence = [
nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
nn.LeakyReLU(0.2, True)
]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [
nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
self.main = nn.Sequential(*sequence)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Conv2d):
nn.init.normal_(module.weight.data, 0.0, 0.02)
elif isinstance(module, nn.BatchNorm2d):
nn.init.normal_(module.weight.data, 1.0, 0.02)
nn.init.constant_(module.bias.data, 0)
def forward(self, input):
"""Standard forward."""
return self.main(input)
class NLayerDiscriminator3D(nn.Module):
"""Defines a 3D PatchGAN discriminator as in Pix2Pix but for 3D inputs."""
def __init__(self, input_nc=1, ndf=64, n_layers=3, use_actnorm=False):
"""
Construct a 3D PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input volumes
ndf (int) -- the number of filters in the last conv layer
n_layers (int) -- the number of conv layers in the discriminator
use_actnorm (bool) -- flag to use actnorm instead of batchnorm
"""
super(NLayerDiscriminator3D, self).__init__()
if not use_actnorm:
norm_layer = nn.BatchNorm3d
else:
raise NotImplementedError("Not implemented.")
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func != nn.BatchNorm3d
else:
use_bias = norm_layer != nn.BatchNorm3d
kw = 3
padw = 1
sequence = [
nn.Conv3d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
nn.LeakyReLU(0.2, True),
]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2**n, 8)
sequence += [
nn.Conv3d(
ndf * nf_mult_prev,
ndf * nf_mult,
kernel_size=(kw, kw, kw),
stride=(2 if n == 1 else 1, 2, 2),
padding=padw,
bias=use_bias,
),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True),
]
nf_mult_prev = nf_mult
nf_mult = min(2**n_layers, 8)
sequence += [
nn.Conv3d(
ndf * nf_mult_prev,
ndf * nf_mult,
kernel_size=(kw, kw, kw),
stride=1,
padding=padw,
bias=use_bias,
),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True),
]
sequence += [
nn.Conv3d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)
] # output 1 channel prediction map
self.main = nn.Sequential(*sequence)
def forward(self, input):
"""Standard forward."""
return self.main(input)
VidTok (Video VQVAE)
主要学video版本的FSQ训练
特点就是:使用FSQ,提出AlphaBlender时序上/下采样模块(fixed MoE),自己弄的数据,采样低FPS视频,2阶段训练,训的比Cosmos更好。
- 连续版本:使用VAE
- 离散版本:VQ操作使用Cosmos中用到的
Finite Scalar Quantization (FSQ)。
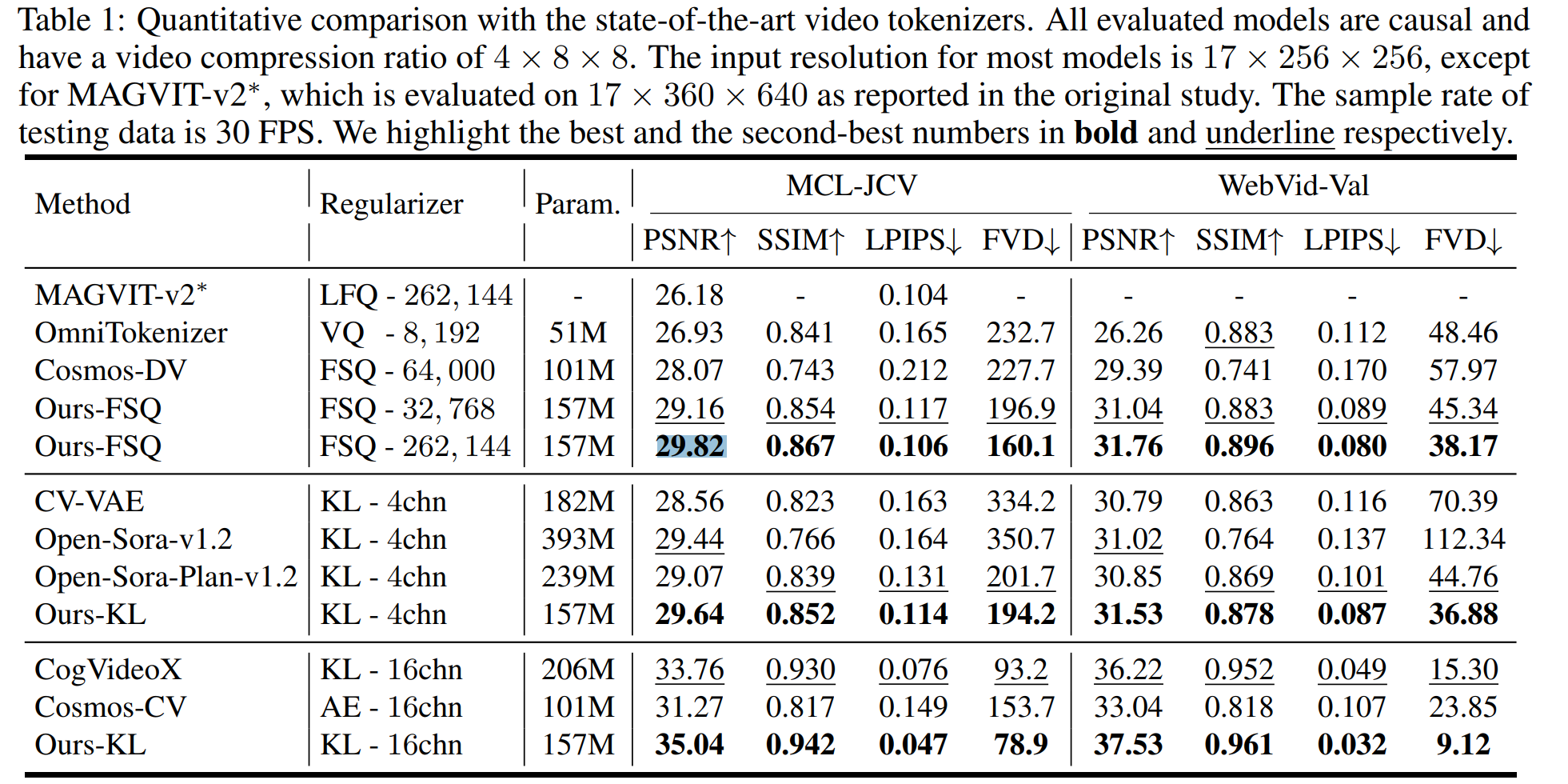
非因果模型通常优于因果模型,因为它们能捕捉到更广泛的时间信息,有助于高保真地重建精细节。
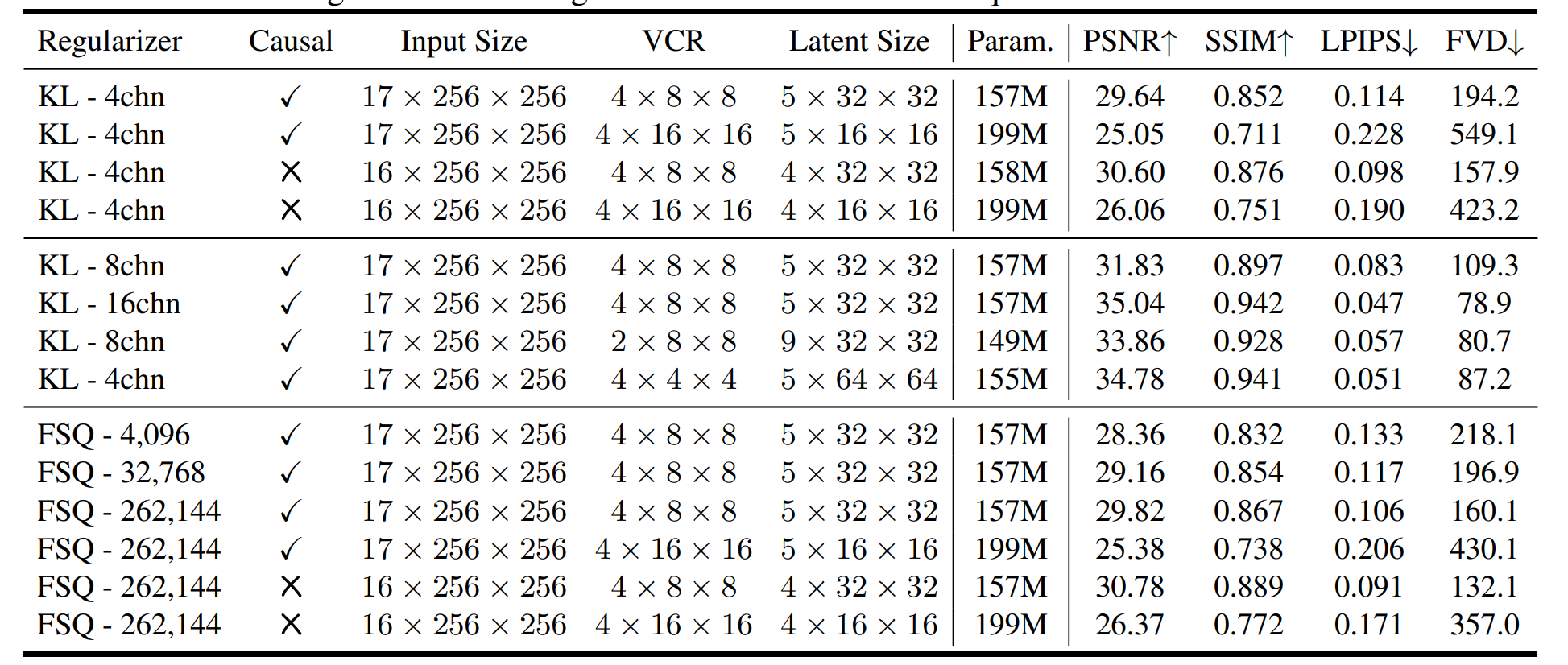
因此本文主要看非因果的FSQ-262144(4x8x8)的模型代码。
Encoder
2D convolutions实现 Spatial维度上/下采样:up/downsampling modulesAlphaBlender实现Temproal维度上/下采样:设置stride=2的avgpool或conv3d,两者的计算结果使用α进行线性加权,αcan be either learnable or a given hyperparameter. In this work, we adopt a pre-definedα = Sigmoid(0.2).- 其余部分使用
3D convolutions实现时空联合建模。
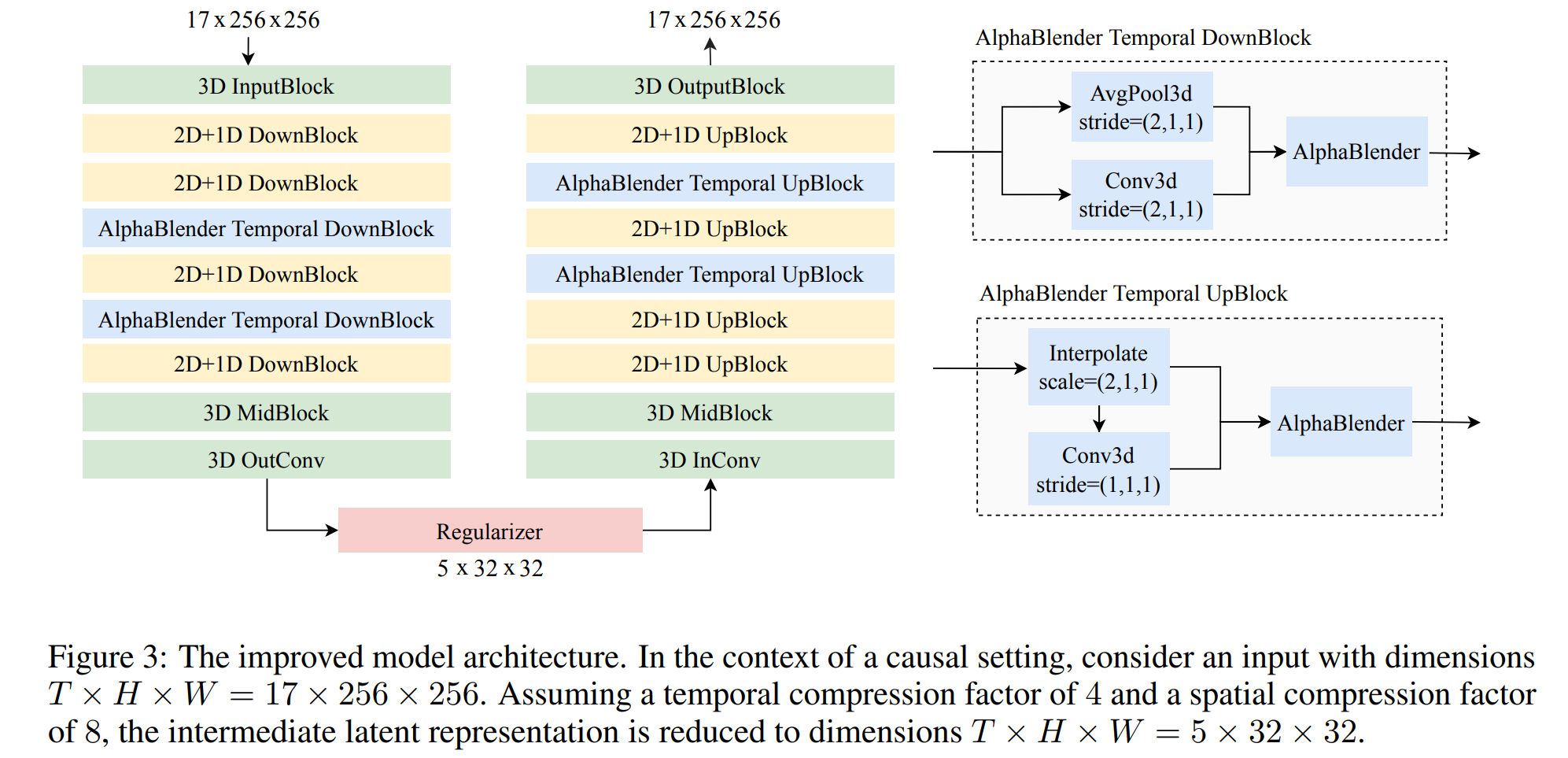
- Encoder3D:
- conv_in: Conv3d对齐输入channel
- down:
ResnetBlock和Downsample - down_temporal:
ResnetBlock1D和TimeDownsampleRes2x - mid:
ResnetNoncausalBlock+AttnBlockWrapper+ResnetNoncausalBlock - conv_out:Conv3d对齐输出channel
class Encoder3D(nn.Module):
def __init__(
self,
*,
ch,
out_ch=8,
ch_mult=(1, 2, 4, 8),
num_res_blocks,
dropout=0.0,
resamp_with_conv=True,
in_channels,
z_channels,
double_z=True,
norm_type="groupnorm",
**ignore_kwargs,
):
super().__init__()
use_checkpoint = ignore_kwargs.get("use_checkpoint", False)
self.ch = ch
self.temb_ch = 0
self.num_resolutions = len(ch_mult)
self.num_res_blocks = num_res_blocks
self.in_channels = in_channels
self.fix_encoder = ignore_kwargs.get("fix_encoder", False)
self.tempo_ds = [self.num_resolutions - 2, self.num_resolutions - 3]
self.norm_type = norm_type
# downsampling
make_conv_cls = self._make_conv()
make_attn_cls = self._make_attn()
make_resblock_cls = self._make_resblock()
self.conv_in = make_conv_cls(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
in_ch_mult = (1,) + tuple(ch_mult)
self.in_ch_mult = in_ch_mult
self.down = nn.ModuleList()
self.down_temporal = nn.ModuleList()
for i_level in range(self.num_resolutions):
block_in = ch * in_ch_mult[i_level]
block_out = ch * ch_mult[i_level]
block = nn.ModuleList()
attn = nn.ModuleList()
block_temporal = nn.ModuleList()
attn_temporal = nn.ModuleList()
for i_block in range(self.num_res_blocks):
block.append(
ResnetBlock(
in_channels=block_in,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout,
use_checkpoint=use_checkpoint,
norm_type=self.norm_type,
)
)
block_temporal.append(
ResnetBlock1D(
in_channels=block_out,
out_channels=block_out,
temb_channels=self.temb_ch,
dropout=dropout,
zero_init=True,
use_checkpoint=use_checkpoint,
norm_type=self.norm_type,
)
)
block_in = block_out
down = nn.Module()
down.block = block
down.attn = attn
down_temporal = nn.Module()
down_temporal.block = block_temporal
down_temporal.attn = attn_temporal
if i_level != self.num_resolutions - 1:
down.downsample = Downsample(block_in, resamp_with_conv)
if i_level in self.tempo_ds:
down_temporal.downsample = TimeDownsampleRes2x(block_in, block_in)
self.down.append(down)
self.down_temporal.append(down_temporal)
# middle
self.mid = nn.Module()
self.mid.block_1 = make_resblock_cls(
in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout,
use_checkpoint=use_checkpoint,
norm_type=self.norm_type,
)
self.mid.attn_1 = make_attn(block_in, norm_type=self.norm_type)
self.mid.block_2 = make_resblock_cls(
in_channels=block_in,
out_channels=block_in,
temb_channels=self.temb_ch,
dropout=dropout,
use_checkpoint=use_checkpoint,
norm_type=self.norm_type,
)
# end
self.norm_out = Normalize(block_in, norm_type=self.norm_type)
self.conv_out = make_conv_cls(
block_in,
2 * z_channels if double_z else z_channels,
kernel_size=3,
stride=1,
padding=1,
)
if self.fix_encoder:
for param in self.parameters():
param.requires_grad = False
def _make_attn(self) -> Callable:
return make_attn
def _make_resblock(self) -> Callable:
return ResnetNoncausalBlock
def _make_conv(self) -> Callable:
return nn.Conv3d
def forward(self, x):
temb = None
B, _, T, _, _ = x.shape
# downsampling
if x.shape[1] == 4 and self.conv_in.in_channels == 3:
raise ValueError("Mismatched number of input channels")
hs = [self.conv_in(x)]
for i_level in range(self.num_resolutions):
for i_block in range(self.num_res_blocks):
h = spatial_temporal_resblk(
hs[-1], self.down[i_level].block[i_block], self.down_temporal[i_level].block[i_block], temb
)
hs.append(h)
if i_level != self.num_resolutions - 1:
# spatial downsample
htmp = einops.rearrange(hs[-1], "b c t h w -> (b t) c h w")
htmp = self.down[i_level].downsample(htmp)
htmp = einops.rearrange(htmp, "(b t) c h w -> b c t h w", b=B, t=T)
if i_level in self.tempo_ds:
# temporal downsample
htmp = self.down_temporal[i_level].downsample(htmp)
hs.append(htmp)
B, _, T, _, _ = htmp.shape
# middle
h = hs[-1]
h = self.mid.block_1(h, temb)
h = self.mid.attn_1(h)
h = self.mid.block_2(h, temb)
# end
h = self.norm_out(h)
h = nonlinearity(h)
h = self.conv_out(h)
return h
ResnetBlock
就是原始的Conv2d的ResnetBlock(spatial维度建模)
Downsample
就是原始的Conv2d的Downsample(spatial维度压缩)
ResnetBlock1D
使用Conv1d实现temporal建模,输入shape=[(b,h,w), c, t]
class ResnetBlock1D(nn.Module):
def __init__(
self,
*,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout,
temb_channels=512,
zero_init=False,
use_checkpoint=False,
norm_type="groupnorm",
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm_type = norm_type
self.norm1 = Normalize(in_channels, norm_type=self.norm_type)
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if temb_channels > 0:
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
self.norm2 = Normalize(out_channels, norm_type=self.norm_type)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = nn.Conv1d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
else:
self.nin_shortcut = nn.Conv1d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
if zero_init:
self.conv2.weight.data.zero_()
self.conv2.bias.data.zero_()
self.use_checkpoint = use_checkpoint
def forward(self, x, temb):
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=UserWarning)
if x.grad is not None or x.grad_fn is not None:
use_checkpoint = True
else:
use_checkpoint = False
if use_checkpoint:
assert temb is None, "checkpointing not supported with temb"
return checkpoint(self._forward, (x,), self.parameters(), self.use_checkpoint)
else:
return self._forward(x, temb)
def _forward(self, x, temb=None):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
return x + h
TimeDownsampleRes2x
AlphaBlender实现Temproal维度上采样:设置stride=2的avgpool或conv3d,两者的计算结果使用α 进行线性加权,α can be either learnable or a given hyperparameter. In this work, we adopt a pre-defined α = Sigmoid(0.2).
class TimeDownsampleRes2x(nn.Module):
def __init__(
self,
in_channels,
out_channels,
mix_factor: float = 2.0,
):
super().__init__()
self.kernel_size = (3, 3, 3)
self.avg_pool = nn.AvgPool3d((3, 1, 1), stride=(2, 1, 1))
self.conv = nn.Conv3d(in_channels, out_channels, 3, stride=(2, 1, 1), padding=(0, 1, 1))
# https://github.com/PKU-YuanGroup/Open-Sora-Plan/blob/main/opensora/models/causalvideovae/model/modules/updownsample.py
self.mix_factor = torch.nn.Parameter(torch.Tensor([mix_factor]))
def forward(self, x):
alpha = torch.sigmoid(self.mix_factor)
pad = (0, 0, 0, 0, 0, 1)
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
x1 = self.avg_pool(x)
x2 = self.conv(x)
return alpha * x1 + (1 - alpha) * x2
ResnetNoncausalBlock
就是正常的Conv3d
class ResnetNoncausalBlock(nn.Module):
def __init__(
self,
*,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout,
temb_channels=512,
use_checkpoint=False,
norm_type="groupnorm",
):
super().__init__()
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.norm_type = norm_type
self.norm1 = Normalize(in_channels, norm_type=self.norm_type)
self.conv1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if temb_channels > 0:
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
self.norm2 = Normalize(out_channels, norm_type=self.norm_type)
self.dropout = torch.nn.Dropout(dropout)
self.conv2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
self.conv_shortcut = nn.Conv3d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
else:
self.nin_shortcut = nn.Conv3d(in_channels, out_channels, kernel_size=1, stride=1, padding=1)
self.use_checkpoint = use_checkpoint
def forward(self, x, temb):
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=UserWarning)
if x.grad is not None or x.grad_fn is not None:
use_checkpoint = True
else:
use_checkpoint = False
if use_checkpoint:
assert temb is None, "checkpointing not supported with temb"
return checkpoint(self._forward, (x,), self.parameters(), self.use_checkpoint)
else:
return self._forward(x, temb)
def _forward(self, x, temb=None):
h = x
h = self.norm1(h)
h = nonlinearity(h)
h = self.conv1(h)
if temb is not None:
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
h = self.norm2(h)
h = nonlinearity(h)
h = self.dropout(h)
h = self.conv2(h)
if self.in_channels != self.out_channels:
if self.use_conv_shortcut:
x = self.conv_shortcut(x)
else:
x = self.nin_shortcut(x)
return x + h
AttnBlockWrapper
使用Conv3d作为linear得到QKV
class AttnBlockWrapper(AttnBlock):
def __init__(self, in_channels, use_checkpoint=False, norm_type="groupnorm"):
super().__init__(in_channels, use_checkpoint=use_checkpoint, norm_type=norm_type)
self.q = torch.nn.Conv3d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
self.k = torch.nn.Conv3d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
self.v = torch.nn.Conv3d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
self.proj_out = torch.nn.Conv3d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
def attention(self, h_: torch.Tensor) -> torch.Tensor:
h_ = self.norm(h_)
q = self.q(h_)
k = self.k(h_)
v = self.v(h_)
b, c, t, h, w = q.shape
q, k, v = map(lambda x: rearrange(x, "b c t h w -> b t (h w) c").contiguous(), (q, k, v))
h_ = torch.nn.functional.scaled_dot_product_attention(q, k, v) # scale is dim ** -0.5 per default
return rearrange(h_, "b t (h w) c -> b c t h w", h=h, w=w, c=c, b=b)
FSQ
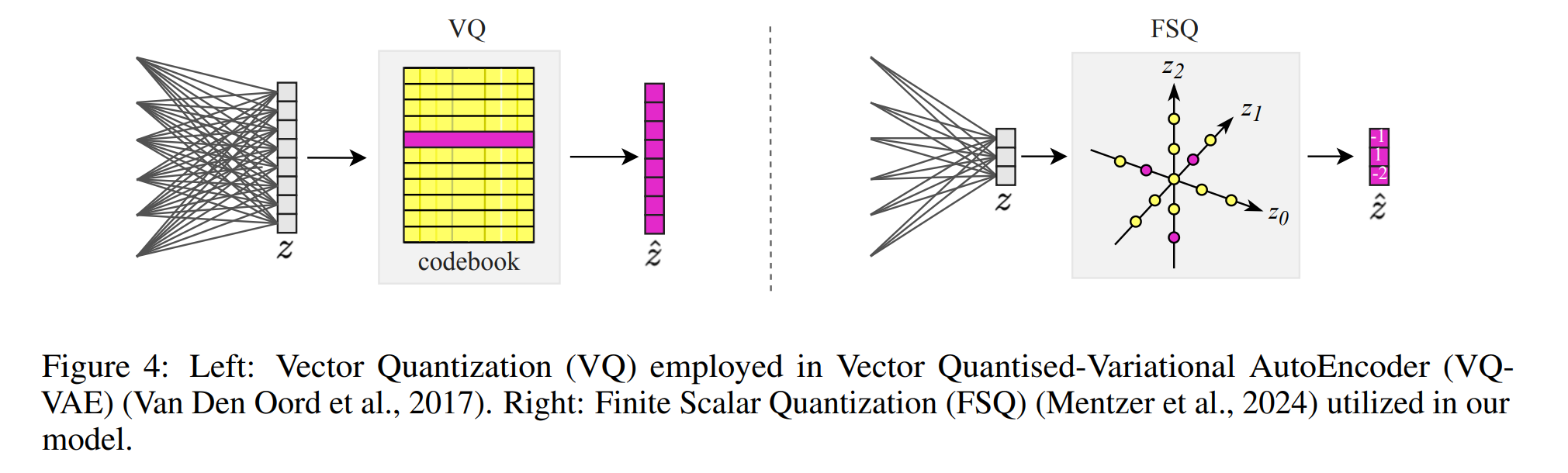
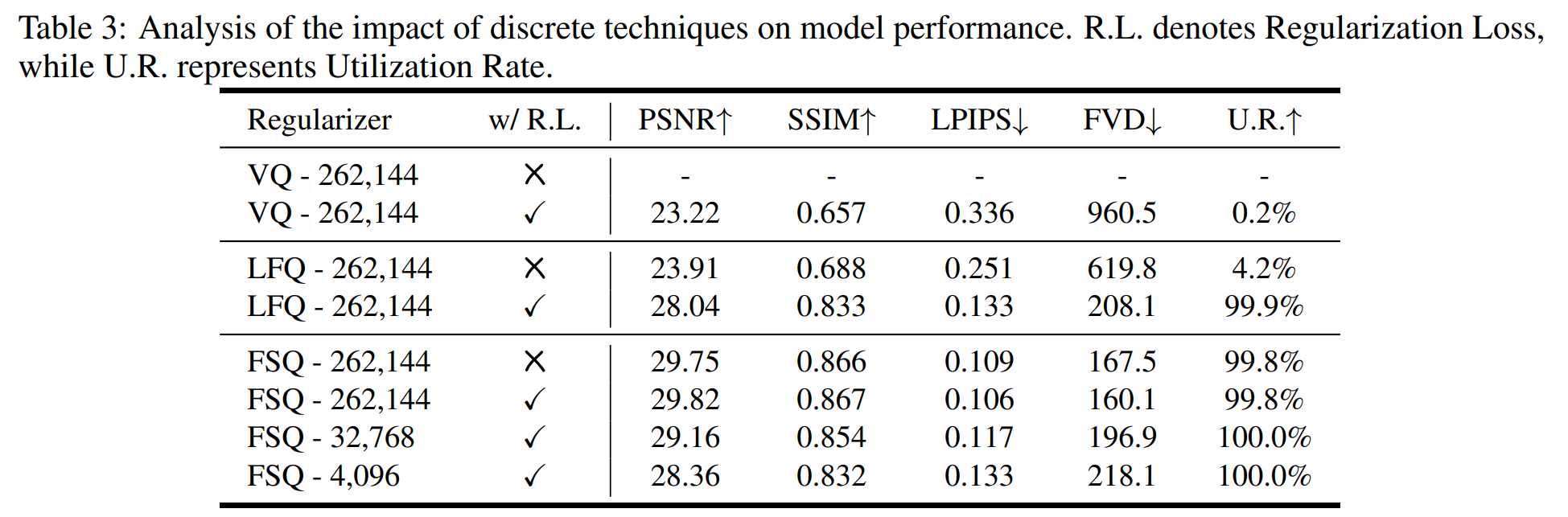
VQ 存在一些常见问题,如训练不稳定性和代码集崩溃,导致代码集利用率极低和重建质量不理想。
相比之下,LFQ 和 FSQ 通过直接优化隐式编码本,实现了近 100% 的编码本利用率。
FSQ 的二进制量化效果优于 LFQ 的二进制量化效果,因为它们实现了更好的重建保真度,这表明在量化过程中减少了信息损失。
Progressive Training
self-collected video dataset: divided into two subsets based on video quality: (1)Stage1: 10 million low-resolution videos (e.g., 480p); and (2) Stage2: 6 million high-resolution videos (e.g., 1080p).
- Stage1:video resolution of
128 × 128and used for initial model training. We train for50, 000 stepswith batch size16. - Stage2:
256 × 256and employed for fine-tuning. We fine-tune the decoder for another30, 000 stepswith batch size8.
利用帧频较低的训练数据能有效提高模型表现运动动态的能力(训练使用3FPS的video进行采样)。

Loss
4个很基础的VQGAN loss:
- reconstruction term(MSE)
- perceptual term(LIPSIS)
- adversarial term(GAN)
- regularization term:连续版本使用KL loss,离散版本使用entropy penalty 和 commitment loss。
OmniTokenizer (Image Video Joint VQVAE)
主要学如何实现Image和Video Joint Train

Encoder
Patchify
follow MAGVITv2,输入video (1+T) × H × W × 3,分开处理第一帧和剩余T帧,这样可以联合建模image和video。
- 划分为非重叠的patch:对于
image (HxWx3),划分spatial patch(每个patch大小为p x p),得到 L 1 = H p × W p L_1=\frac{H}{p} \times \frac{W}{p} L1=pH×pW个image patch(shape从[H,W,3]变成[L1, 3 x h x w])。对于video (T x H x W x 3),划分spatial-temporal patch(每个patch大小为t x p x p),得到 L 2 = H p × W p × T t L_2=\frac{H}{p} \times \frac{W}{p} \times \frac{T}{t} L2=pH×pW×tT个video patch(shape从[T,H,W,3]变成[L2, 3 x h x w x t])。 - Linear project:使用两层linear projector分别将两者的
embedding_dim对齐(batch, seq_len, embed_dim),得到image patch embedding和video patch embedding。 - concat:将image patch embedding和video patch embedding 沿着
seq_len维度concat。
这样一来patchify就实现了image/video的下采样(从H,W,T压缩为h,w,t),此外如何使用linear在时空encoder之后,可能还会使用pool的方式进一步下采样。
具体来说,文章实现了基于Linear和CNN的2种patchify方式:默认使用linear
if patch_embed == 'linear':
if defer_temporal_pool:
temporal_patch_size //= 2
self.temporal_patch_size = temporal_patch_size
self.temporal_pool = nn.AvgPool3d(kernel_size=(2, 1, 1))
else:
self.temporal_pool = nn.Identity()
if defer_spatial_pool:
self.patch_size = pair(patch_size // 2)
patch_height, patch_width = self.patch_size
self.spatial_pool = nn.AvgPool3d(kernel_size=(1, 2, 2))
else:
self.spatial_pool = nn.Identity()
self.to_patch_emb_first_frame = nn.Sequential(
Rearrange('b c 1 (h p1) (w p2) -> b 1 h w (c p1 p2)',
p1=patch_height, p2=patch_width),
nn.LayerNorm(image_channel * patch_width * patch_height),
nn.Linear(image_channel * patch_width * patch_height, dim),
nn.LayerNorm(dim)
)
self.to_patch_emb = nn.Sequential(
Rearrange('b c (t pt) (h p1) (w p2) -> b t h w (c pt p1 p2)',
p1=patch_height, p2=patch_width, pt=temporal_patch_size),
nn.LayerNorm(image_channel * patch_width *
patch_height * temporal_patch_size),
nn.Linear(image_channel * patch_width *
patch_height * temporal_patch_size, dim),
nn.LayerNorm(dim)
)
elif patch_embed == 'cnn':
self.to_patch_emb_first_frame = nn.Sequential(
# SamePadConv3d(image_channel, dim, kernel_size=(1, patch_height, patch_width), stride=(1, patch_height, patch_width)),
nn.Conv3d(image_channel, dim, kernel_size=(1, patch_height, patch_width), stride=(1, patch_height, patch_width)),
Normalize(dim, norm_type),
Rearrange('b c t h w -> b t h w c'),
)
self.to_patch_emb = nn.Sequential(
# SamePadConv3d(image_channel, dim, kernel_size=(temporal_patch_size, patch_height, patch_width), stride=(temporal_patch_size, patch_height, patch_width)),
nn.Conv3d(image_channel, dim, kernel_size=(temporal_patch_size, patch_height, patch_width), stride=(temporal_patch_size, patch_height, patch_width)),
Normalize(dim, norm_type),
Rearrange('b c t h w -> b t h w c'),
)
self.temporal_pool, self.spatial_pool = nn.Identity(), nn.Identity()
forward的时候也是既可以处理image,也可以处理video:
# 4 is BxCxHxW (for images), 5 is BxCxFxHxW
assert video.ndim in {4, 5}
first_frame, rest_frames = video[:, :, :1], video[:, :, 1:]
# derive patches
first_frame_tokens = self.to_patch_emb_first_frame(first_frame)
if rest_frames.shape[2] != 0: # video
rest_frames_tokens = self.to_patch_emb(rest_frames)
# simple cat
tokens = torch.cat((first_frame_tokens, rest_frames_tokens), dim=1)
else: # only image
tokens = first_frame_tokens
Spatial-Temporal Decoupled Transformer Architecture
4 window attention-based spatial layers (window size = 8) and 4 causal attention-based temporal layers:(hidden dimension = 512 ,latent dimension = 8)
window attentionis employed in the spatial dimension owing to its local aggregation capacity and efficiencycausal attentionis used in the temporal dimension to capture the motion in videos and ensure temporal coherence.
分别实现spatial transformer和temporal transformer:forward的时候类似VideoVAE+,先进行所有的空间建模,再进行所有的时序建模。
self.enc_spatial_transformer = Transformer(depth=spatial_depth, block=block, window_size=window_size, spatial_pos=spatial_pos, **transformer_kwargs)
self.enc_temporal_transformer = Transformer(
depth=temporal_depth, block='t' * temporal_depth, **transformer_kwargs)
if initialize: self.apply(self._init_weights)
# video shape, last dimension is the embedding size
video_shape = tuple(tokens.shape[:-1])
tokens = rearrange(tokens, 'b t h w d -> (b t) (h w) d')
# encode - spatial
tokens = self.enc_spatial_transformer(tokens, video_shape=video_shape, is_spatial=True)
hw = tokens.shape[1]
new_h, new_w = int(math.sqrt(hw)), int(math.sqrt(hw))
tokens = rearrange(tokens, '(b t) (h w) d -> b t h w d', b=b, h=new_h, w=new_w)
# encode - temporal
video_shape2 = tuple(tokens.shape[:-1])
tokens = rearrange(tokens, 'b t h w d -> (b h w) t d')
tokens = self.enc_temporal_transformer(tokens, video_shape=video_shape2, is_spatial=False)
# tokens = self.enc_temporal_transformer(tokens)
# codebook expects: [b, c, t, h, w]
tokens = rearrange(tokens, '(b h w) t d -> b d t h w', b=b, h=new_h, w=new_w)
LFQ
采用开源的github库:vector-quantize-pytorch
https://github.com/lucidrains/vector-quantize-pytorch
Progressive Training
- Stage1:
256×256的固定分辨率的image数据,为空间理解奠定基础。 - Stage2:
image+video joint时,空间分辨率randomly chosen from 128, 192, 256, 320, 384,视频帧采样17帧,数据增强只使用random horizontal flip!!训练的时候image batch和video batch交替进行。这种图像-视频联合训练阶段对于模型学习通用embedding至关重要,该embedding可以准确地捕捉单个帧的空间复杂性以及顺序视频数据的时间关系。
两个stage都训练了至少500K iterations。loss就是很基础了VQGAN的loss。
image video的交替batch训练通过PL的LightningDataModule在train时返回多个dataset的dataloader实现。只需要为不同的dataset指定不同的batch_size即可。
class VideoData(pl.LightningDataModule):
def __init__(self, args, shuffle=True):
super().__init__()
self.args = args
self.shuffle = shuffle
@property
def n_classes(self):
dataset = self._dataset(True)
return dataset[0].n_classes
def _dataset(self, train):
# load image and video dataset to datasets
if self.args.loader_type == 'sep':
# check if it's coinrun dataset (path contains coinrun and it's a directory)
if osp.isdir(self.args.data_path[0]) and 'coinrun' in self.args.data_path[0].lower():
if hasattr(self.args, 'coinrun_v2_dataloader') and self.args.coinrun_v2_dataloader:
Dataset = CoinRunDatasetV2
else:
Dataset = CoinRunDataset
if hasattr(self.args, 'smap_cond') and self.args.smap_cond:
dataset = Dataset(data_folder=self.args.data_path[0], args=self.args, train=train, get_seg_map=True)
elif hasattr(self.args, 'text_cond') and self.args.text_cond:
if self.args.smap_only:
dataset = Dataset(data_folder=self.args.data_path[0], args=self.args, train=train,
get_game_frame=False, get_seg_map=True, get_text_desc=True)
else:
dataset = Dataset(data_folder=self.args.data_path[0], args=self.args, train=train, get_text_desc=True)
elif self.args.smap_only:
dataset = Dataset(data_folder=self.args.data_path[0], args=self.args, train=train,
get_game_frame=False, get_seg_map=True)
else:
dataset = Dataset(data_folder=self.args.data_path[0], args=self.args, train=train)
else:
if hasattr(self.args, 'vtokens') and self.args.vtokens:
Dataset = HDF5Dataset_vtokens
dataset = Dataset(self.args.data_path[0], self.args.sequence_length,
train=train, resolution=self.args.resolution, spatial_length=self.args.spatial_length,
sample_every_n_frames=self.args.sample_every_n_frames)
elif hasattr(self.args, 'image_folder') and self.args.image_folder:
Dataset = FrameDataset
dataset = Dataset(self.args.data_path[0], self.args.sequence_length,
resolution=self.args.resolution, sample_every_n_frames=self.args.sample_every_n_frames)
elif hasattr(self.args, 'stft_data') and self.args.stft_data:
Dataset = StftDataset
dataset = Dataset(self.args.data_path[0], self.args.sequence_length, train=train,
sample_every_n_frames=self.args.sample_every_n_frames)
elif hasattr(self.args, 'smap_cond') and self.args.smap_cond:
Dataset = HDF5Dataset_smap
dataset = Dataset(self.args.data_path[0], self.args.data_path2, self.args.sequence_length,
train=train, resolution=self.args.resolution,
image_channels1=self.args.image_channels1,
image_channels2=self.args.image_channels2)
elif hasattr(self.args, 'text_cond') and self.args.text_cond:
Dataset = HDF5Dataset_text
dataset = Dataset(self.args.data_path[0], self.args.sequence_length, self.args.text_emb_model,
train=train, resolution=self.args.resolution, image_channels=self.args.image_channels,
text_len=self.args.text_seq_len, truncate_captions=self.args.truncate_captions)
elif hasattr(self.args, 'sample_every_n_frames') and self.args.sample_every_n_frames>1:
Dataset = VideoDataset if osp.isdir(self.args.data_path[0]) else HDF5Dataset
dataset = Dataset(self.args.data_path[0], self.args.sequence_length,
train=train, resolution=self.args.resolution, sample_every_n_frames=self.args.sample_every_n_frames)
else:
if "UCF" in self.args.data_path[0]:
Dataset = VideoDataset if osp.isdir(self.args.data_path[0]) else HDF5Dataset
dataset = Dataset(self.args.data_path[0], self.args.sequence_length,
train=train, resolution=self.args.resolution)
elif "imagenet" in self.args.data_path[0]:
dataset = ImageDataset(self.args.data_path[0], data_list=self.args.train_datalist[0] if train else self.args.val_datalist[0], train=train, resolution=self.args.resolution)
return [dataset]
else:
datasets = []
for dataset_path, train_list, val_list in zip(self.args.data_path, self.args.train_datalist, self.args.val_datalist):
if "UCF" in dataset_path or 'k400' in train_list or 'k600' in train_list or "sthv2" in train_list or "ucf" in train_list or "moment" in train_list:
dataset = DecordVideoDataset(dataset_path, train_list if train else val_list, self.args.fps, self.args.sequence_length,
train=train, resolution=self.args.resolution, resizecrop=self.args.resizecrop)
datasets.append(dataset)
elif "imagenet" in dataset_path or 'openimage' in dataset_path:
dataset = ImageDataset(
dataset_path, train_list if train else val_list, train=train, resolution=self.args.resolution, resizecrop=self.args.resizecrop
)
datasets.append(dataset)
elif "imagenet" in train_list or "celeb" in train_list or "ffhq" in train_list:
dataset = ImageDataset(
dataset_path, train_list if train else val_list, train=train, resolution=self.args.resolution, resizecrop=self.args.resizecrop
)
datasets.append(dataset)
return datasets
def _dataloader(self, train):
# get image and video datasets
dataset = self._dataset(train)
# print(self.args.batch_size)
if isinstance(self.args.batch_size, int):
self.args.batch_size = [self.args.batch_size]
assert len(dataset) == len(self.args.sample_ratio) == len(self.args.batch_size)
dataloaders = []
# create dataloaders for each dataset with different batch sizes
for dset, d_batch_size in zip(dataset, self.args.batch_size):
if dist.is_initialized():
sampler = data.distributed.DistributedSampler(
dset, num_replicas=dist.get_world_size(), rank=dist.get_rank()
)
else:
sampler = None
dataloader = data.DataLoader(
dset,
batch_size=d_batch_size,
num_workers=self.args.num_workers,
pin_memory=False,
sampler=sampler,
shuffle=sampler is None and train
)
dataloaders.append(dataloader)
return dataloaders
def train_dataloader(self):
return self._dataloader(True)
def val_dataloader(self):
return self._dataloader(False)[0]
def test_dataloader(self):
return self.val_dataloader()
@staticmethod
def add_data_specific_args(parent_parser):
parser = argparse.ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument('--loader_type', type=str, default='sep', choices=['sep', 'joint'])
parser.add_argument('--data_path', type=str, nargs="+", default=['./UCF-101/videos_split/'])
parser.add_argument('--train_datalist', type=str, nargs="+", default=['./ucf_train.txt'])
parser.add_argument('--val_datalist', type=str, nargs="+", default=['./ucf_val.txt'])
parser.add_argument('--sample_ratio', type=float, nargs="+", default=[1])
parser.add_argument('--fps', type=int, default=16)
parser.add_argument('--resizecrop', action="store_true")
parser.add_argument('--sequence_length', type=int, default=16)
parser.add_argument('--resolution', type=int, default=128)
parser.add_argument('--batch_size', type=int, nargs="+", default=[32])
parser.add_argument('--num_workers', type=int, default=8)
parser.add_argument('--image_channels', type=int, default=3)
parser.add_argument('--smap_cond', type=int, default=0)
parser.add_argument('--smap_only', action='store_true')
parser.add_argument('--text_cond', action='store_true')
parser.add_argument('--vtokens', action='store_true')
parser.add_argument('--vtokens_pos', action='store_true')
parser.add_argument('--spatial_length', type=int, default=15)
parser.add_argument('--sample_every_n_frames', type=int, default=1)
parser.add_argument('--image_folder', action='store_true')
parser.add_argument('--stft_data', action='store_true')
return parser
MAGE(Mask Image VQVAE)
主要学如何引入image mask加速的
VQGAN的Encoder,Codebook,Decoder完全没改(直接load pretrained VQGAN权重,训练的时候也冻结VQGAN的Encoder和Decoder以及Codebook),只是在VQGAN的codebook后面,加了一个MaskEncoder(就是一个BERT),mask操作的是latent index,而不是原始的pixel。就是VQGAN里面嵌套了一个MAE,MAE重建的不是pixel,而是vq codebook的latent index!
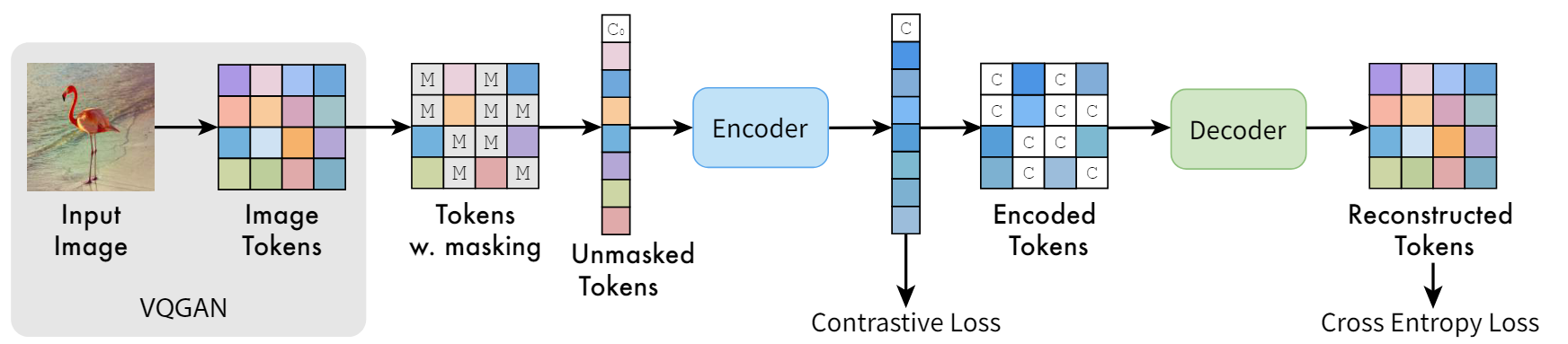
MaskEncoder
代码写的很奇怪:mask是加在token_indices上,另外使用一个BERT Embedding对index进行embeding,这个embedding是重新学的,和VQ codebook的embedding没有关系。
另一种思路:不再单独定义BERT embedding,而是直接对VQ得到的VQ latent embedding进行mask,然后使用2层的MLP升高维度(8 -> 512 -> 768),在前面插入1个可学习的CLS token,然后直接送入MAE transformer。
- masking ratio:
[0.5, 1], 截断高斯分布以0.55为中心,左截断0.5,右截断1。
# MAGE variant masking ratio (gaussian distribution: [0.5, 1.0])
self.mask_ratio_min = mask_ratio_min
self.mask_ratio_generator = stats.truncnorm((mask_ratio_min - mask_ratio_mu) / mask_ratio_std,
(mask_ratio_max - mask_ratio_mu) / mask_ratio_std, loc=mask_ratio_mu, scale=mask_ratio_std)
- BERT Embedding:负责将VQ得到的latent index转换为embedding(但是这个emebdding不是VQ codebook的embedding,而是重新学的BERT embedding)。包含原始
1024个VQ codebook index,又加入1000个class token index(作者在github中说实际上是冗余的,只需要1个即可),再加入1个mask token index。
# bert_vocab = vqgan_codebook(1024 token) + cls_token(1000) + mask_token(1)
self.codebook_size = config.params.n_embed # 1024
vocab_size = self.codebook_size + 1000 + 1 # 1024 codebook size, 1000 classes, 1 for mask token = 2025
# 可以将fake_class_label设置为大于或等于 1024 且小于 1024+1000+1 的任何值, 但预先训练的模型将其设置为 1100(同样,这是一个遗留问题)。
self.fake_class_label = self.codebook_size + 1100 - 1024 # fake cls token label: the first token in the 1000 class token
self.mask_token_label = vocab_size - 1 # mask token label: the last token in the vocab
self.token_emb = BertEmbeddings(vocab_size=vocab_size, # vocab_size = codebook_size(1024) + class(1000) + mask_token(1)
hidden_size=embed_dim, # hidden_size=1024
max_position_embeddings=256+1,
dropout=0.1)
Mask,AddCLS ,Drop
- get mask:得到VQGAN的
token_indices([batch_size, seq_len])之后,根据mask_ratio_min和mask_rate分别使用sorted(noise)的方法得到token_drop_mask和token_all_mask两个mask的模板。token_all_mask是表示所有token中需要mask的token。token_drop_mask表示masked token中需要drop的token。
# masking: all token num = seq_len,
bsz, seq_len = token_indices.size()
mask_ratio_min = self.mask_ratio_min
mask_rate = self.mask_ratio_generator.rvs(1)[0] # get random mask ratio between [0.5, 1.0]
# num_dropped_tokens is 50% of seq_len, num_masked_tokens is mask_ratio% of seq_len
num_dropped_tokens = int(np.ceil(seq_len * mask_ratio_min)) # the number of dropped tokens
num_masked_tokens = int(np.ceil(seq_len * mask_rate)) # the number of masked tokens
# get random mask by sorted(noise)
# it is possible that two elements of the noise is the same, so do a while loop to avoid it
while True:
noise = torch.rand(bsz, seq_len, device=x.device) # noise in [0, 1] for all token idx, shape torch.Size([1, 196])
sorted_noise, _ = torch.sort(noise, dim=1) # ascend: small is remove, large is keep
cutoff_drop = sorted_noise[:, num_dropped_tokens-1:num_dropped_tokens] # torch.Size([1, 1])
cutoff_mask = sorted_noise[:, num_masked_tokens-1:num_masked_tokens] # torch.Size([1, 1])
token_drop_mask = (noise <= cutoff_drop).float() # random mask of dropped tokens [0/1]
token_all_mask = (noise <= cutoff_mask).float() # random mask of masked tokens [0/1]
if token_drop_mask.sum() == bsz*num_dropped_tokens and token_all_mask.sum() == bsz*num_masked_tokens:
break
else:
print("Rerandom the noise!") # print(mask_rate, num_dropped_tokens, num_masked_tokens, token_drop_mask.sum(dim=1), token_all_mask.sum(dim=1))
- replace mask token index and add cls token index:然后根据
token_all_mask将token_indices中mask_token的index替换为BERT vocab中的mask_token_label,再token_indices最前面加上cls token的index即fake_class_label,(原始unmask vq token的index和BERT vocab中的index一样,因此不用改变)。同样,因为增加了cls token,对应的 mask 也需要在最前面增加一个。
# mask token idx replace with mask_token_label
token_indices[token_all_mask.nonzero(as_tuple=True)] = self.mask_token_label
# print("Masekd num token:", torch.sum(token_indices == self.mask_token_label, dim=1))
# concate class token: torch.Size([1, 196]) concat torch.Size([1, 1]) -> torch.Size([1, 197])
token_indices = torch.cat([torch.zeros(token_indices.size(0), 1).cuda(device=token_indices.device), token_indices], dim=1)
token_indices[:, 0] = self.fake_class_label # replace the first zero_pad token with fake class token
# add 0 to unmask fake class token
token_drop_mask = torch.cat([torch.zeros(token_indices.size(0), 1).cuda(), token_drop_mask], dim=1)
token_all_mask = torch.cat([torch.zeros(token_indices.size(0), 1).cuda(), token_all_mask], dim=1)
token_indices = token_indices.long()
- emebdding all BERT token index:使用可学习的token embedding对得到的所有index进行embedding操作。
index->embedding
# bert embedding for all token_indices: torch.Size([1, 197]) -> torch.Size([1, 197, 768])
input_embeddings = self.token_emb(token_indices)
# print("Input embedding shape:", input_embeddings.shape)
bsz, seq_len, emb_dim = input_embeddings.shape
- drop part of masked token:注意,在送入MAE Encoder之前,没有drop所有的mask token,而是
只drop了最低mask rate=0.5 对应的那部分masked token!!,即token_drop_mask模板中对应的那部分。还有部分masked token的index embedding是被送入了的。
# dropping: torch.Size([1, 197, 768]) -> torch.Size([1, 99, 768])
token_keep_mask = 1 - token_drop_mask
input_embeddings_after_drop = input_embeddings[token_keep_mask.nonzero(as_tuple=True)].reshape(bsz, -1, emb_dim)
- MAE transformer建模:将cls token作为global token 学习所有index token的信息。
# apply Transformer blocks
x = input_embeddings_after_drop
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
# print("Encoder representation shape:", x.shape)
MaskDecoder
送入Decoder transformer前,先用一层linear进行降维,降低到decoder_embed_dim
# embed tokens
x = self.decoder_embed(x)
使用CLS token复制为与原始序列长度一样的token(即整个序列是由CLS token组成的),然后将unmask的token替换掉对应位置的CLS token:
# append mask tokens to sequence: replace mask token with cls token
if self.pad_with_cls_token:
mask_tokens = x[:, 0:1].repeat(1, token_all_mask.shape[1], 1)
else:
mask_tokens = self.mask_token.repeat(token_all_mask.shape[0], token_all_mask.shape[1], 1)
# put undropped tokens into original sequence
x_after_pad = mask_tokens.clone()
x_after_pad[(1 - token_drop_mask).nonzero(as_tuple=True)] = x.reshape(x.shape[0] * x.shape[1], x.shape[2])
# set undropped but masked positions with mask
x_after_pad = torch.where(token_all_mask.unsqueeze(-1).bool(), mask_tokens, x_after_pad)
最后,给得到的所有token加上Position embedding,送入decoder的transformer中:
# add pos embed
x = x_after_pad + self.decoder_pos_embed_learned
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
最终,使用MLM layer计算解码序列中每个token对于BERT Embedding的vocab中每个token的logits:
word_embeddings = self.token_emb.word_embeddings.weight.data.detach()
x = self.mlm_layer(x, word_embeddings)
# MLM layer = linear + gelu + layer norm
class MlmLayer(nn.Module):
def __init__(self, feat_emb_dim, word_emb_dim, vocab_size):
super().__init__()
self.fc = nn.Linear(feat_emb_dim, word_emb_dim)
self.gelu = nn.GELU()
self.ln = nn.LayerNorm(word_emb_dim)
self.bias = nn.Parameter(torch.zeros(1, 1, vocab_size))
def forward(self, x, word_embeddings):
mlm_hidden = self.fc(x)
mlm_hidden = self.gelu(mlm_hidden)
mlm_hidden = self.ln(mlm_hidden)
word_embeddings = word_embeddings.transpose(0, 1)
logits = torch.matmul(mlm_hidden, word_embeddings)
logits = logits + self.bias
return logits
Mask token decode
每个masked token在BERT embedding中的logits最大值就是对应预测的index,可以使用其计算CE loss:
def forward_loss(self, gt_indices, logits, mask):
bsz, seq_len = gt_indices.size()
# logits and mask are with seq_len+1 but gt_indices is with seq_len
loss = self.criterion(logits[:, 1:, :self.codebook_size].reshape(bsz*seq_len, -1), gt_indices.reshape(bsz*seq_len))
loss = loss.reshape(bsz, seq_len)
loss = (loss * mask[:, 1:]).sum() / mask[:, 1:].sum() # mean loss on removed patches
return loss
train and inference
- 训练的时候,是一次性预测出所有masked token index,并计算loss。
- 推理的时候(iterative decoding),
start from a blank imagewith all the tokens masked out,虽然每次可以算出所有masked token index,但是只取confidence最高的一部分token,然后迭代进行masked token index 的预测,直到预测出全部masked token。
Contrastive loss
这部分代码没开:
- 对MAE encoder得到的feature进行
average pooling和normalized,然后送入2层的MLP。使用InfoNCEloss进行对比学习的训练,提升理解表征。
其实这里的Contrastive loss也可以考虑换成CLIP做teacher进行蒸馏。
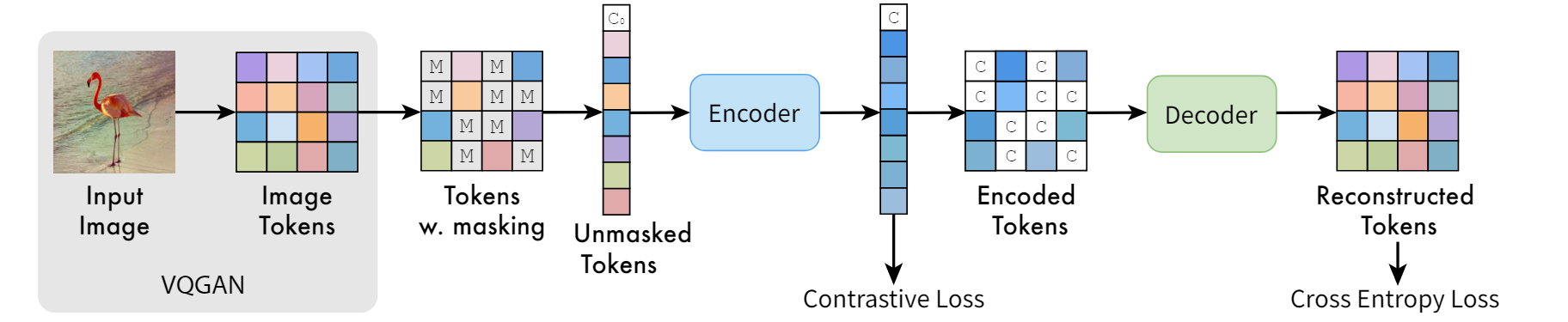
MaskGiT
和MAGE不同的点在于,没有对比学习,直接对vq codebook得到的embedding zq做Mask。
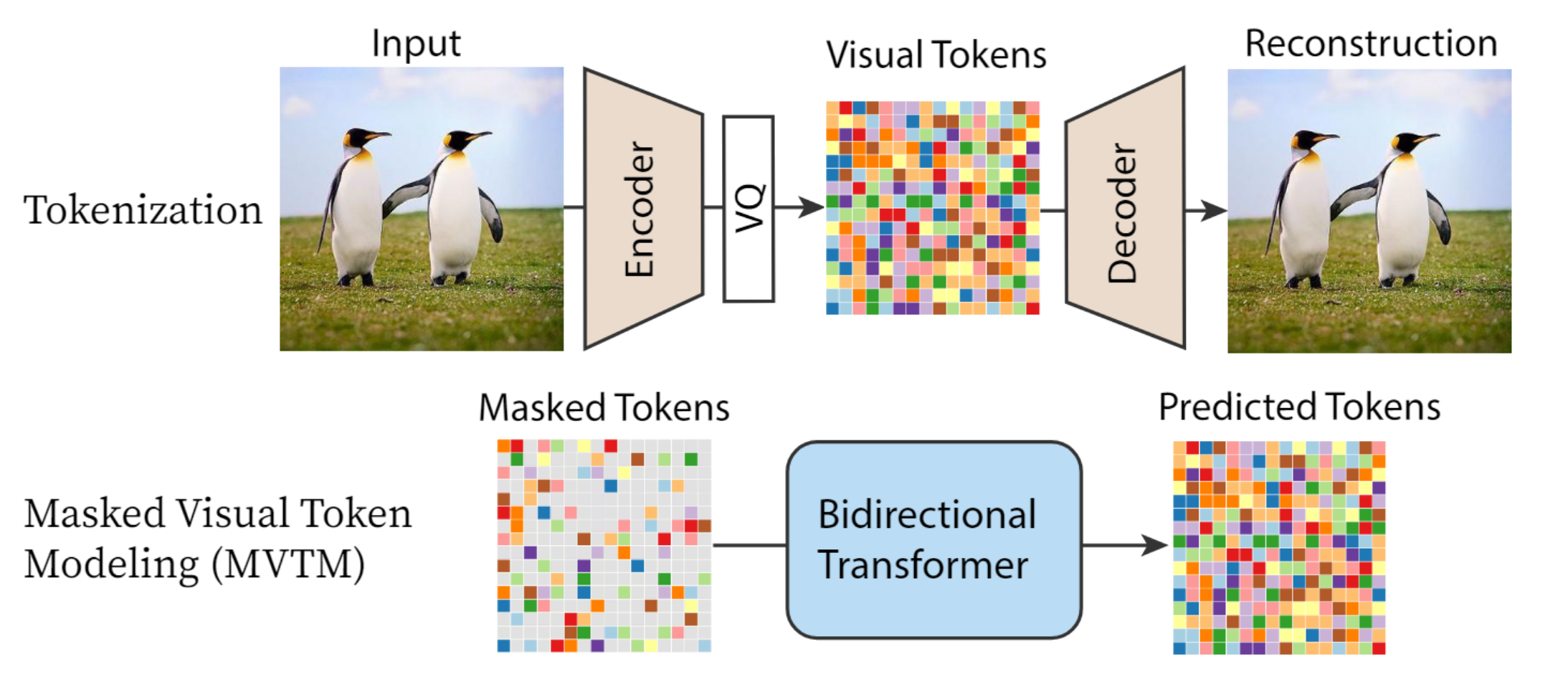
MaskVIT(Mask Video VQVAE)
主要学如何引入video mask加速的
由于没开代码,只根据文章对其进行分析,实现细节不得而知。
- VQGAN时序上:没有额外的建模,还是使用image预训练的VQGAN。只压缩了spatial,得到的 latent feature还是16帧的。
- video mae:根据history frame token和current frame unmasked token,预测current frame masked token。
- Bidirectional Window Transformer:不得不说有点像
Conv2D+Conv3D交替。只是换成了Window Attention,window size of1 × 16 × 16(spatial window) andT × 4 × 4(spatiotemporal window)。

- 迭代解码:也是逐帧进行的。

BEITv2
学如何patch level 的 Mask



















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











