




 文章探讨了ReservoirComputing(RC),一种基于随机固定网络的神经网络扩展,强调了ESN的工作原理、组成部分、训练过程,以及深度储备池计算在硬件上的进展和理论泛化上限的研究。北京大学和哈工大深圳的研究团队分别在硬件实现和模型泛化上取得了突破。
文章探讨了ReservoirComputing(RC),一种基于随机固定网络的神经网络扩展,强调了ESN的工作原理、组成部分、训练过程,以及深度储备池计算在硬件上的进展和理论泛化上限的研究。北京大学和哈工大深圳的研究团队分别在硬件实现和模型泛化上取得了突破。
Reservoir Computing, 也叫Echo state network(回声网络), 被视为是神经网络(Neural Network)的一种拓展框架。
目录
5.1 北京大学黄如院士-杨玉超教授团队在深度储备池计算硬件研究中取得进展
5.2 哈工大(深圳)赵毅教授团队:储备池计算模型的更紧致泛化上限
5.4 演化储备池计算机揭示神经网络预测性能与因果涌现强度的双向耦合 (更新中-ing)
一、ESN
Echo state networks (ESN)
Echo state networks provide an architecture and supervised learning principle for recurrent neural networks (RNNs). The main idea is (i) to drive a random, large, fixed recurrent neural network with the input signal, thereby inducing in each neuron within this "reservoir" network a nonlinear response signal, and (ii) combine a desired output signal by a trainable linear combination of all of these response signals.
给定一段信号:u(0), u(1), ... , u(Nt-1);
目标值:v(1), v(2), ... , v(Nt)
学习黑箱模型M,可得预测v(Nt+1), v(Nt+2), ...
ESN的思想
使用大规模随机稀疏网络(储备池)作为信息处理媒介,将输入信号从低维的输入空间映射到高维的状态空间,在高维的状态空间采用线性回归方法对网络的部分连接权进行训练,而其他连接权随机产生,并在网络训练过程中保持不变。这种思想在Steil关于传统递归神经网络的经典算法(Atiya-Parlos)的研究中也得到了验证:递归神经网络输出连接权改变迅速,而内部连接权则以高度耦合的方式缓慢改变。也就是说,如果递归神经网络内部连接权选择合适,在对网络进行训练时可以忽略内部连接权的改变。
ESN的结构和训练步骤
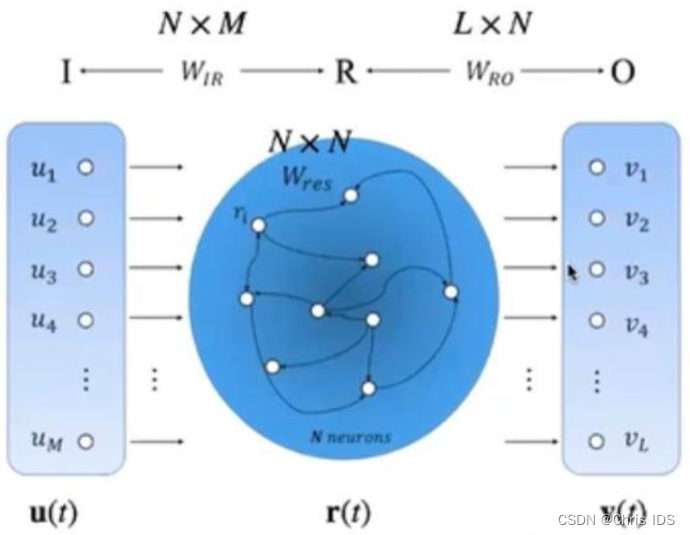
结构如上图:r(t)为“储备池”,它有以下特点:
(1)包含数目更多的神经元;
(2)神经元之间的连接关系随机产生;
(3)神经元之间的连接具有稀疏性。
上面的两个参数矩阵![]() 都是事先给定的数值,在训练的过程中只需要计算
都是事先给定的数值,在训练的过程中只需要计算即可。
整个计算过程如下所示:
(1)从输入到储备池(reservoir)的运算:;
(2)储备池中r ( t ) 的更新:;
(3)从储备池到输出:;
(4)损失函数:;
(5)使损失函数最小化 ……
比较官方的解释
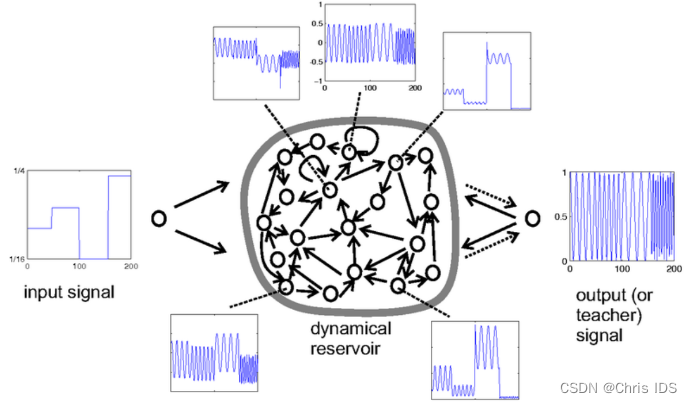
- Step 1: Provide a random RNN. (i) Create a random dynamical reservoir RNN, using any neuron model (in the frequency generator demo example, non-spiking leaky integrator neurons were used). The reservoir size N is task-dependent. In the frequency generator demo task, N=200 was used. (ii) Attach input units to the reservoir by creating random all-to-all connections. (iii) Create output units. If the task requires output feedback (the frequency-generator task does), install randomly generated output-to-reservoir connections (all-to-all). If the task does not require output feedback, do not create any connections to/from the output units in this step.
- Step 2: Harvest reservoir states. Drive the dynamical reservoir with the training data D for times n=1,…,nmax . In the demo example, where there are output-to-reservoir feedback connections, this means to write both the input u(n) into the input unit and the teacher output y(n) into the output unit ("teacher forcing"). In tasks without output feedback, the reservoir is driven by the input u(n) only. This results in a sequence x(n) of N-dimensional reservoir states. Each component signal x(n) is a nonlinear transform of the driving input. In the demo, each x(n) is an individual mixture of both the slow step input signal and the fast output sinewave (see the five exemplary neuron state plots in Figure
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









