






目录
3、train_test_split()函数:将数据集划分为测试集与训练集
一、前言
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
二、数据预处理整体流程
1、导入库
2、导入数据集
3、处理缺失数据
4、进行Label编码
5、拆分数据为训练集和测试集
6、特征标准化
三、数据预处理详细步骤
1、导入库
#导入库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.impute import SimpleImputer2、导入数据集
#读取数据
dataset = pd.read_csv(r"D:\Desktop\CC是小陈\Machine Learning\Data.csv")
print(dataset)3、处理缺失数据
#处理缺失值
imputer = SimpleImputer(missing_values=np.nan,strategy = 'mean')
imputer = imputer.fit(dataset.iloc[:,1:3])
dataset.iloc[:,1:3] = imputer.transform(dataset.iloc[:,1:3])
print(dataset)
'''
可以转化为:
salary_mean = dataset['Salary'].mean()
age_mean = dataset['Age'].mean()
dataset['Salary'].fillna(salary_mean,inplace=True)
dataset['Age'].fillna(age_mean,inplace=True)
print(dataset)'''
4、进行Label编码
#进行Label编码 转化字符串或类别标签
labelencoder_x = LabelEncoder()
dataset.iloc[:,0] = labelencoder_x.fit_transform(dataset.iloc[:,0])
print(dataset)
labelencoder_y = LabelEncoder()
dataset.iloc[:,3] = labelencoder_y.fit_transform(dataset.iloc[:,3])
print(dataset)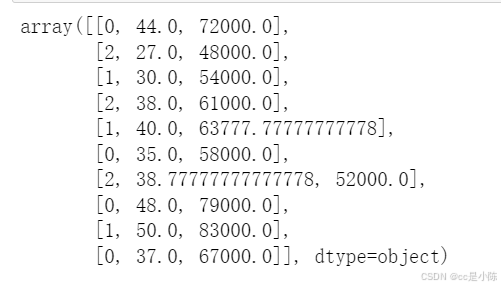

5、拆分数据为训练集和测试集
#将数据拆分为训练集和测试集
x = dataset.iloc[:,1:3] # 获取索引为1-2的列
y = dataset.iloc[:,3]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2,random_state =0)6、特征标准化
#特征标准化
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test) 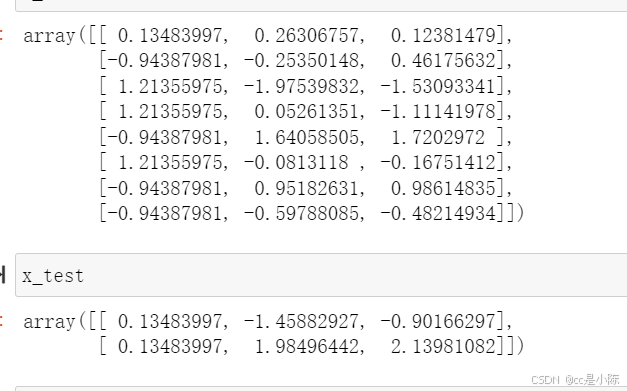
四、总结
1、数据预处理
在机器学习中,数据预处理很重要。通俗来讲,数据预处理就是对原始数据进行清洗和转换,主要包括数据清洗、数据标准化等。有效的数据预处理能够减少模型过拟合的风险,同时也能提升模型性能的准确性和稳定性。数据预处理主要包括以下几种:
(1)数据清洗:数据清洗主要包括重复值处理、缺失值处理、异常值处理等,进而提高数据质量和模型性能;
(2)数据标准化:是将数据转化为均值为0、标准差为1的分布;
(3)数据归一化:是将数据缩放到某个特定的范围,有助于提高机器学习性能;
(4)类别编码:即将类别特征转化为数值形式,以便机器学习算法能够处理;
(5)特征选择:选择相关性比较高的特征,去除无关或冗余的特征;
(6)特征缩放:调整特征的范围,使其在相似的范围内;
(7)特征构造:从现有的特征中构建新的特征,进而发现隐藏的数据之间的关系;
(8)降维:减少特征数据,保留主要的维度信息。如:PCA主成分分析;
(9)数据增强:通过对数据进行变换增加数据的多样性,进而提高模型的泛化能力;
(10)数据平衡:通过欠采样、过采样等方法处理数据类别不平衡问题;
2、LabelEncoder
是 scikit-learn中用于将标签(或分类数据)转换为归一化编码的类。即它会将标签(通常是字符串或整数)映射到从 0 到 n_classes-1 的整数上,其中 n_classes 是唯一标签的数量。这个过程对于大多数机器学习算法来说是必要的,因为大多数算法都期望输入数据是数值型的。
3、train_test_split()函数:将数据集划分为测试集与训练集
(1)X:所要划分的整体数据的特征集;
(2)Y:所要划分的整体数据的结果;
(3)test_size:测试集数据量在整体数据量中的占比;
(4)random_state:若不填或填0,每次生成的数据都是随机,可能不一样;若为整数,每次生成的数据相同;
4、Imputer处理缺损数据
(1)sklearn.impute.SimpleImputer 是 Scikit-learn 库中的一个类,用于处理数据集中缺失值的插补。它通过替换缺失值为统计值(例如均值、中位数或众数)或指定的常数来处理缺失数据。以下是 SimpleImputer 的详细介绍:
missing_values: 指定需要替换的缺失值。默认值为np.nan,表示替换 NaN 值。strategy: 指定替换策略。可选值包括:
mean: 用均值替换缺失值。仅适用于数值数据。median: 用中位数替换缺失值。仅适用于数值数据。most_frequent: 用众数(出现频率最高的值)替换缺失值。适用于数值和分类数据。constant: 用常数替换缺失值。需要同时指定fill_value参数。fill_value: 在strategy='constant'时,指定替换缺失值的常数。默认值为None。add_indicator: 是否添加二进制指示变量,用于指示缺失值的位置。默认值为False。
(2)SimpleImputer方法概要:
fit(X, y=None): 拟合 imputer,计算用于替换缺失值的统计值;transform(X): 使用拟合的 imputer 替换缺失值;fit_transform(X, y=None): 结合fit和transform,对数据集进行拟合并替换缺失值;

















 8117
8117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









