




前言
ELMo:将上下文当作特征,但是无监督的语料和我们真实的语料还是有区别的,不一定符合我们特定的任务,是一种双向的特征提取。
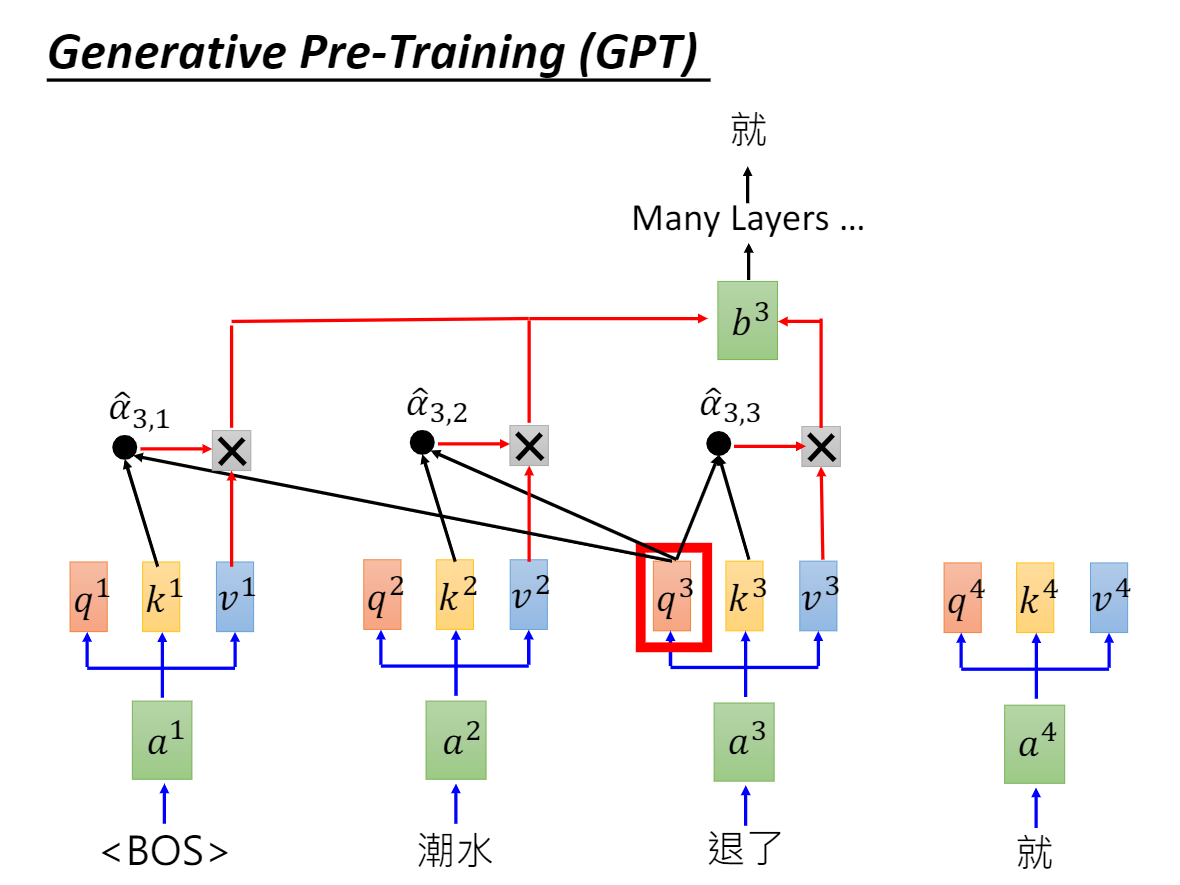
OpenAI GPT: 通过transformer decoder学习出来一个语言模型,不是固定的,通过任务 fine-tuning,用transfomer代替ELMo的LSTM。
OpenAI GPT其实就是缺少了encoder的transformer:当然也没了encoder与decoder之间的attention。
OpenAI GPT虽然可以进行fine-tuning,但是有些特殊任务与pre-training输入有出入,单个句子与两个句子不一致的情况,很难解决,还有就是decoder只能看到前面的信息。
GPT适用于生成任务(自回归语言模型,任务更难但潜力更大), BERT适合判别。
GPT1大概1亿参数,BERT-base类似, BERT-large大概3.4亿
类似GPT2大概13亿参数
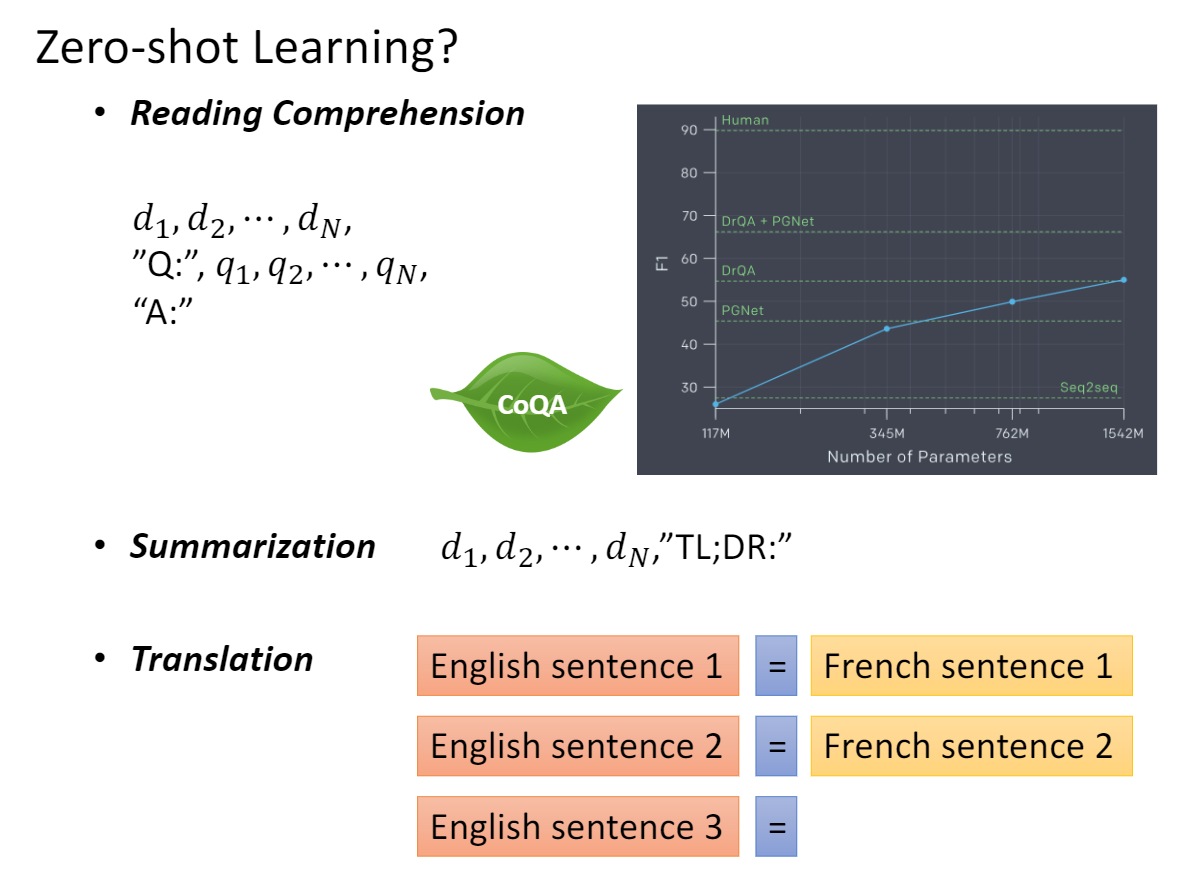

True LM (预训练没有句子级别任务)
有监督微调时:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









