






你是否曾在数据科学项目中为生成一个符合需求的数据集而头疼?比如,当你需要演示一个清晰的聚类算法时,却发现随机生成的数据点杂乱无章;或者当你试图展示一个非线性决策边界时,手动调整参数却始终无法达到理想效果。传统的数据生成方法往往需要编写冗长的代码、反复调试分布参数,甚至还要依赖运气才能得到满意的结果。
直到我发现了 DrawData——这个神奇的 Python 库彻底改变了我的数据生成方式。它允许你像在白板上作画一样,用鼠标直接绘制数据集,几秒钟内就能得到符合你预期的数据分布。无论是用于教学演示、算法测试,还是机器学习模型的原型设计,DrawData 都能让你的工作变得更加高效和有趣。
DrawData 发现之旅
最近负责一个机器学习入门研讨会,需要准备一些直观的案例来演示聚类、分类和回归算法。我希望数据集能清晰展现不同算法的特点——比如完美的球形簇、螺旋分布,或者经典的 XOR 模式。然而,手动生成这些数据并不容易:
-
为了构造聚类数据,我不得不反复调整
sklearn.datasets.make_blobs的参数,确保类别之间足够分离。 -
想要一个漂亮的螺旋数据集?那就得写一段复杂的极坐标转换代码。
-
更别提非线性边界的数据了,稍有不慎,生成的点就会混成一团,毫无区分度。
就在我几乎要放弃的时候,我发现了 DrawData。它的概念简单到令人难以置信:直接在 Jupyter Notebook 里用鼠标绘制数据点,然后一键导出为 DataFrame。我半信半疑地试了一下,结果——它不仅真的能用,而且生成的数据完全符合我的设想!
DrawData 是什么?为什么它如此强大?
DrawData 的核心功能可以用一句话概括:“所见即所得”的数据生成工具。它提供了一个交互式画布,让你可以:
-
自由绘制数据点:用不同颜色(代表不同类别)直接在图表上点击或拖动,生成散点数据。
-
调整数据分布:你可以控制点的密度、形状,甚至绘制复杂的模式(如环形、月牙形或自定义曲线)。
-
一键导出:生成的数据可以直接转换为 Pandas DataFrame,无缝对接 Scikit-learn、PyTorch 等机器学习库。
它的应用场景非常广泛:
-
教学演示:让学生直观理解不同数据分布对算法的影响。
-
快速原型设计:在真实数据尚未准备好时,用合成数据测试模型。
-
数据增强:为特定任务生成补充数据,比如模拟边缘案例。
如何使用 DrawData
安装和使用 drawdata 非常简单。如果已经安装了 Python,那么你已经完成了一半。以下是入门方法:
安装库:
pip install drawdata
在 Jupyter notebook:中导入并初始化它:
from drawdata import draw_scatter
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
draw_scatter()

运行代码时,会弹出一个交互式小部件。然后,你可以单击并拖动鼠标在画布上绘制点。每次单击都会将数据添加到你的自定义数据集,你稍后可以将其导出为 Pandas DataFrame 或 NumPy 数组等格式。
用法:ScatterWidget
你可以加载散点图小部件以立即开始绘图。
from drawdata import ScatterWidget
widget = ScatterWidget()
widget
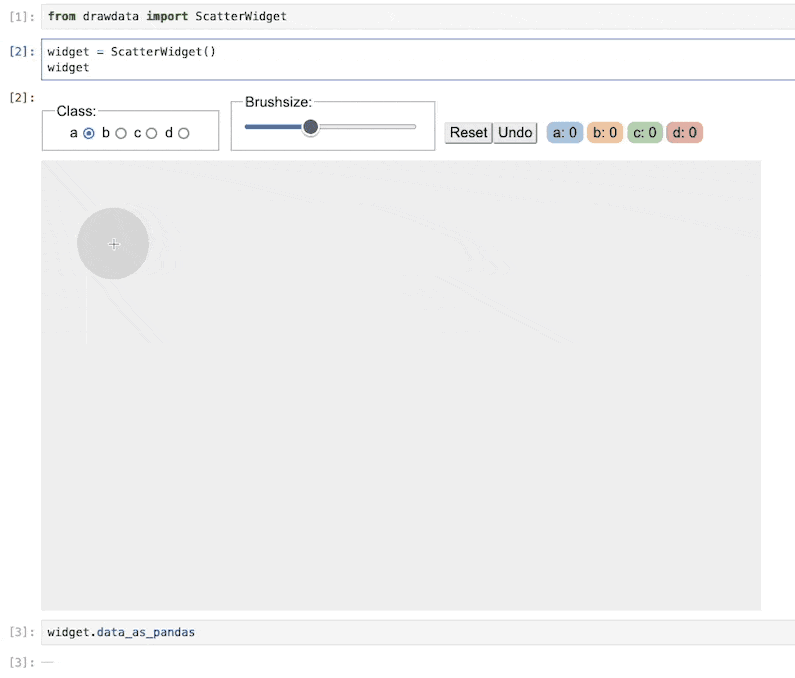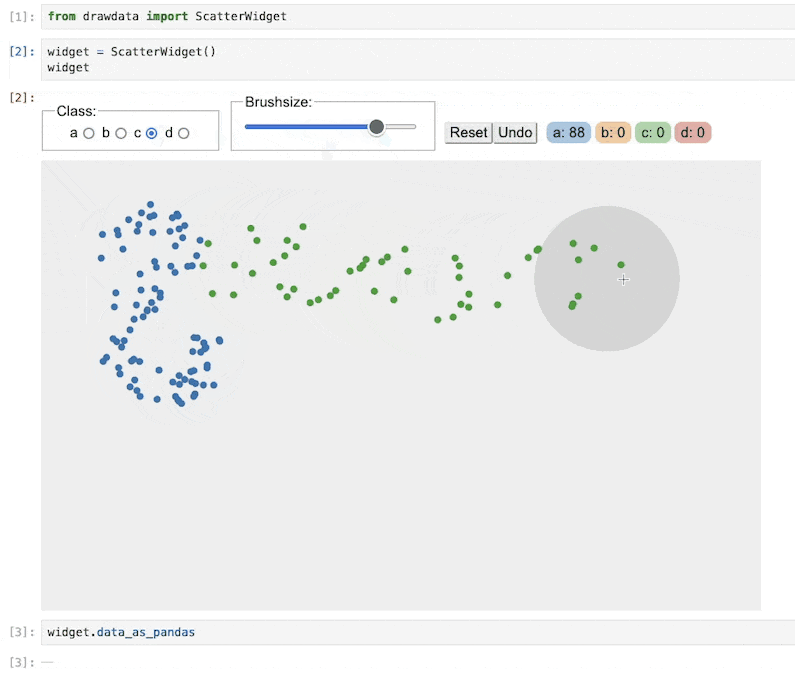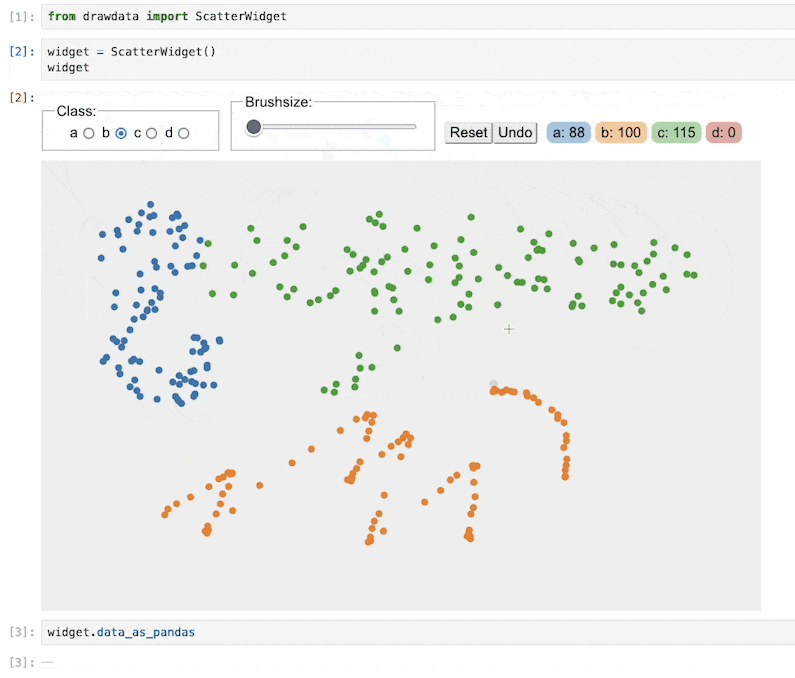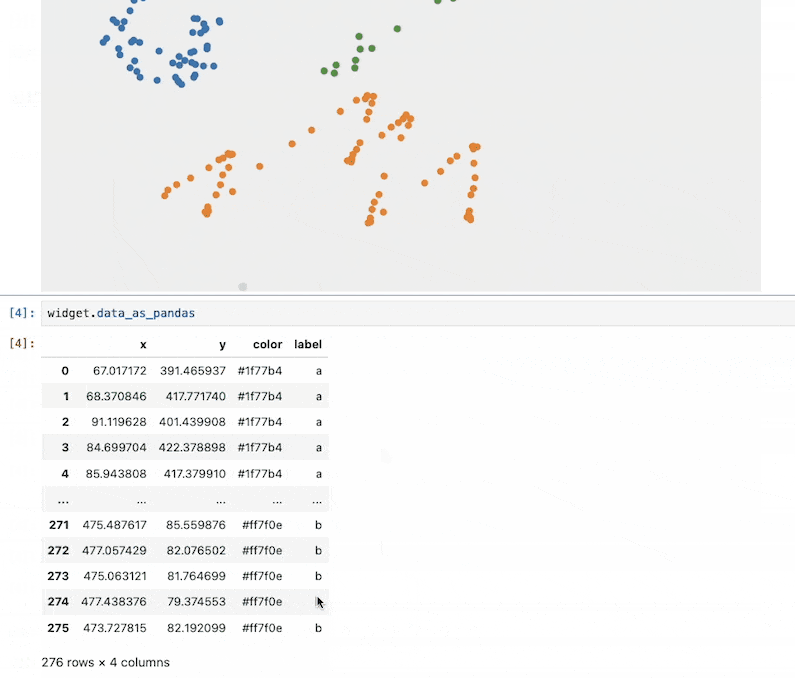
如果你想使用刚刚绘制的数据集,可以通过以下方式进行:
# Get the drawn data as a list of dictionaries
widget.data
# Get the drawn data as a dataframe
widget.data_as_pandas
widget.data_as_polars
如果你想使用绘制的数据进行 scikit-learn 操作,你可能会喜欢这个属性:
X, y = widget.data_as_X_y
此属性的假设是,如果您使用了多种颜色,则表示您对分类感兴趣,而如果你只绘制了一种颜色,则表示你对回归感兴趣。在回归的情况下,y将参考 y 轴。
高级用法
该项目在底层使用anywidget ,因此我们的工具应该可以在 Jupyter、VSCode 和 Colab 中使用。这样将获得一个可以与ipywidgets本地交互的适当小部件。
以下是更新绘图触发新 scikit-learn 模型进行训练的示例:
from drawdata import ScatterWidget
widget = ScatterWidget()
import matplotlib.pyplot as plt
from IPython.core.display import HTML
from sklearn.linear_model import LogisticRegression
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pylab as plt
import numpy as np
import ipywidgets
widget = ScatterWidget()
output = ipywidgets.Output()
@output.capture(clear_output=True)
def on_change(change):
df = widget.data_as_pandas
if len(df) and (df['color'].nunique() > 1):
X = df[['x', 'y']].values
y = df['color']
display(HTML("<br><br><br>"))
fig = plt.figure(figsize=(12, 12));
classifier = DecisionTreeClassifier().fit(X, y)
disp = DecisionBoundaryDisplay.from_estimator(
classifier, X,
response_method="predict_proba"if len(np.unique(df['color'])) == 2else"predict",
xlabel="x", ylabel="y",
alpha=0.5,
);
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k");
plt.title(f"{classifier.__class__.__name__}");
plt.show();
widget.observe(on_change, names=["data"])
on_change(None)
ipywidgets.HBox([widget, output])
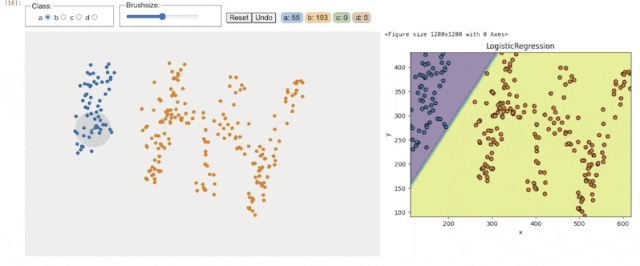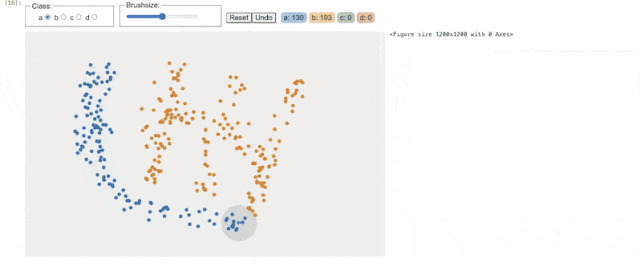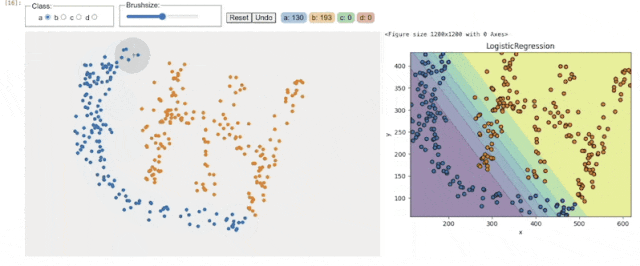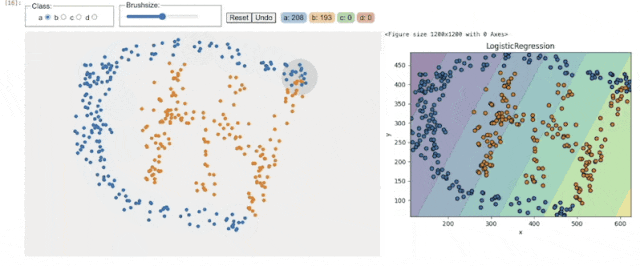
用法:BarWidget
from drawdata import BarWidget
widget = BarWidget(collection_names=["usage", "sunshine"], n_bins=24)
widget
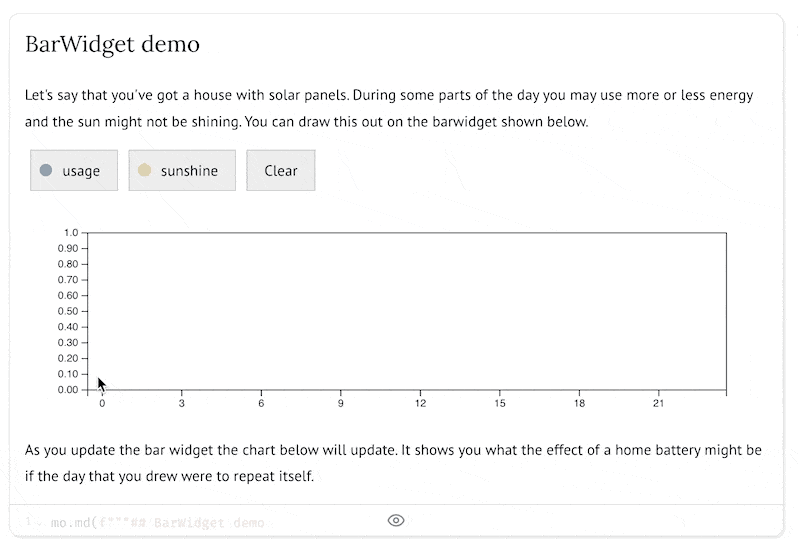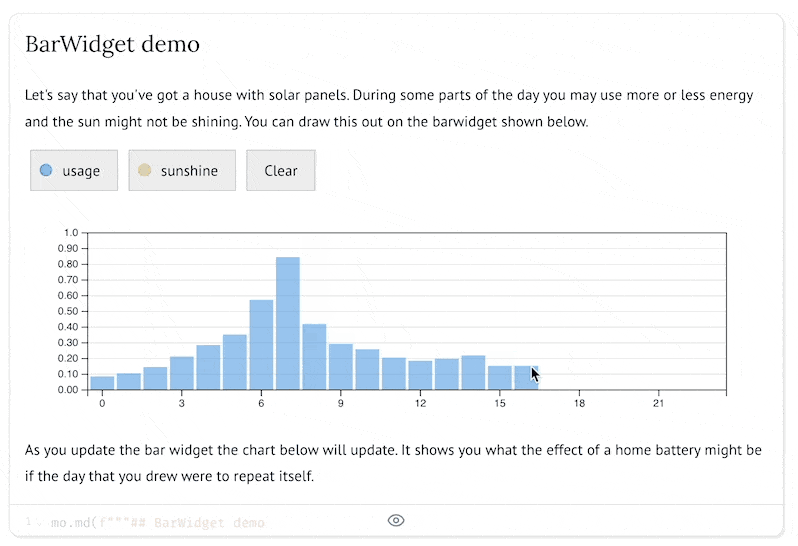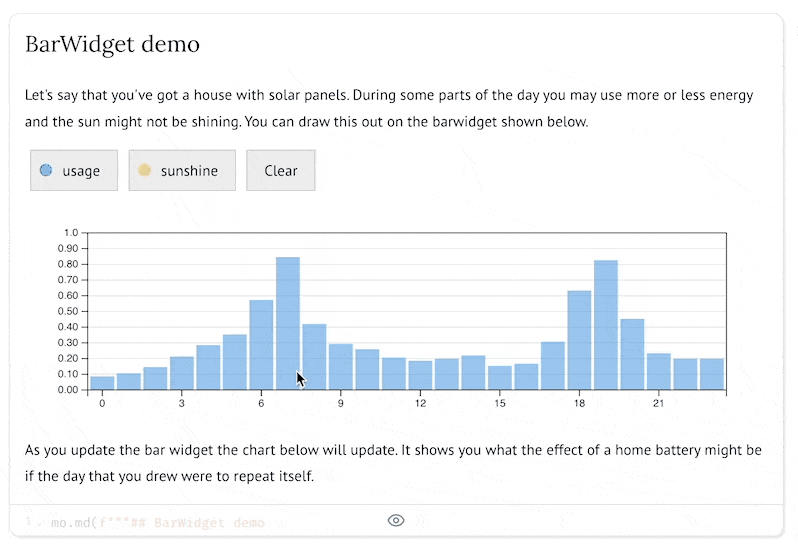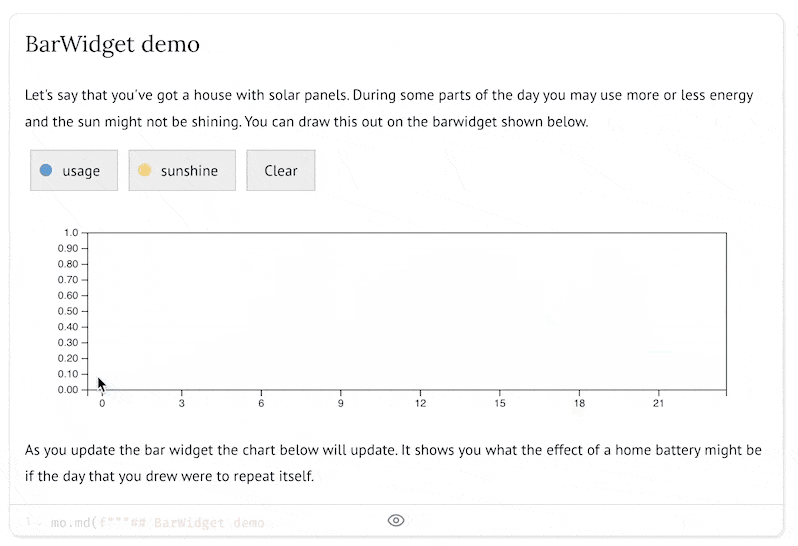
为什么 DrawData 是数据科学的游戏规则改变者?
1. 教学神器:让抽象概念“看得见”
作为一名机器学习讲师,我深知一个直观的数据集对教学有多重要。传统数据集(如 Iris 或 MNIST)虽然经典,但往往不够灵活——它们无法按需调整来匹配特定算法的讲解需求。
DrawData 彻底解决了这个问题。比如在讲解 k-means 聚类时,我不再需要说“假设数据分布是这样的…”,而是直接画出三个完美分离的簇,让学生亲眼看到算法如何迭代收敛。在演示决策边界时,我可以随手绘制一个非线性可分的数据集,让SVM或神经网络的分类效果一目了然。
更棒的是,它的互动性极大提升了课堂参与度。当我现场绘制数据集时,学生们的反应往往是:“哇,原来数据可以这样生成!”这种即时反馈让枯燥的理论变得生动起来。
2. 快速原型设计:没有数据?那就画一个!
在真实项目中,我们常遇到“数据尚未就绪”的困境——也许标注还没完成,或者第三方数据源延迟了。此时,DrawData 能让你几分钟内生成替代数据集,快速验证想法。
-
想测试一个新聚类算法?画几个分布复杂的簇试试。
-
需要调试分类模型?手动绘制线性可分或异或(XOR)模式的数据。
-
甚至可以用它模拟异常检测场景,比如故意画几个离群点。
这种“即时数据”的能力,让算法开发不再被数据采集阻塞,尤其适合黑客马拉松、论文实验或内部技术预研。
3. 释放创造力:数据科学也可以“玩”出来
数据科学不仅是数学和代码,更是一种创造性工作。DrawData 把数据生成变成了数字画布,让你像艺术家一样“雕刻”数据分布:
-
想做一个螺旋状聚类?画出来!
-
需要月牙形分类边界?随手一描!
-
甚至能模拟现实中的复杂模式,比如地理分布或用户行为聚类。
这种体验打破了“数据必须来自现实”的刻板印象,让我们回归到问题本质——用最直接的方式表达数据关系。
技术揭秘:DrawData 如何实现“画布变数据”?
DrawData 的核心技术并不复杂,但设计极其巧妙:
-
交互式捕获:基于 Matplotlib 的交互式后端,实时记录鼠标轨迹和点击坐标。
-
动态映射:将屏幕像素坐标转换为标准化数据范围(如0-1区间),并支持自定义缩放。
-
多格式输出:生成的数据可直接转为 Pandas DataFrame,或导出为 CSV/JSON,兼容主流工具链(如Scikit-learn、PyTorch)。
以下是一个例子:
from drawdata import draw_scatter
import matplotlib.pyplot as plt
# 初始化绘图画布
plt.figure(figsize=(6, 6))
draw_scatter()
# 访问生成的数据
from drawdata.utils import get_data
x, y = get_data()
利用这些 x 和 y 值,你可以:
-
将数据保存到 CSV 文件以供日后使用。
-
将其加载到 Pandas DataFrame 中进行分析。
-
将其用作 scikit-learn 模型的输入。
DrawData实战指南
四大核心应用场景
课堂魔法师
-
教授SVM决策边界?随手画出非线性可分数据集
-
演示DBSCAN密度聚类?快速勾勒不同密度的点群
-
实时调整数据分布,让"假设性举例"变成可视化现实
可视化实验室
-
测试新开发的D3.js图表时,即时生成匹配测试用例
-
验证matplotlib自定义主题时,快速创建对比数据集
-
制作演示PPT时,绘制与演讲内容完美契合的示意图
算法外科医生
-
当随机森林出现异常分类时,构建"极端案例"数据集
-
调试聚类算法时,故意创造重叠率不同的点群
-
测试模型鲁棒性时,绘制包含特定噪声模式的数据
协作画布
-
团队脑暴时多人接力绘制数据模式
-
机器学习研讨会上实时收集参会者创作的数据集
-
编程教学中让学生亲手"画"出第一个数据集
现实约束与应对策略
维度局限 → 解决方案:
-
通过特征组合模拟高维关系(如绘制X/Y轴代表PCA成分)
-
结合
sklearn.datasets生成高维数据后,用DrawData创建可视化投影
环境依赖 → 平替方案:
-
在Colab中运行后导出CSV到本地环境
-
使用
pyautogui录制绘图动作生成自动化脚本
精度补偿 → 增强技巧:
-
导出后使用
scipy.ndimage.gaussian_filter平滑分布 -
通过
sklearn.utils.resample进行数据增强 -
用
numpy.random.normal添加可控噪声
进阶技巧锦囊
-
动态教学:结合IPython.display实时显示算法在绘制数据上的演变
-
混合创作:将DrawData生成的数据与真实数据按比例混合
-
模式移植:分析绘制数据的统计特征,用GAN生成扩展数据集
DrawData重新定义了数据科学的创作范式——它把"数据准备"这个传统上最枯燥的环节,变成了最具创造力的过程。就像摄影师需要理解光线一样,数据科学家通过亲手"绘制"数据,能获得对数据-模型关系更本质的认知。
"工具最大的价值不在于它能做什么,而在于它让你成为什么样的思考者。DrawData最革命性的地方,是让数据生成从被动接受变成了主动创造。" —— 数据科学教育家Sarah Chen
今天就用pip install drawdata开启你的数据创作之旅。试着完成这个挑战:绘制一个让KNN准确率低于50%的魔鬼数据集!
为什么你该试试 DrawData?
DrawData 的出现,让数据生成从一项繁琐的编程任务变成了一个充满创造力的过程。无论你是数据科学家、教育工作者,还是机器学习爱好者,这个库都能让你的工作更加高效。
如果你也曾为生成理想数据集而烦恼,不妨试试 DrawData——它可能就是你一直在寻找的“数据画笔”。
-
对教师:告别“假设数据”的尴尬,让抽象算法可视化。
-
对工程师:快速验证想法,不再被数据短缺卡住进度。
-
对爱好者:用最有趣的方式理解数据与模型的关系。
它像数据的“素描本”,让机器学习从第一天起就变得直观、互动且充满创造力。如果你还没尝试过,现在正是时候——毕竟,谁能拒绝“画”出理想数据集的能力呢?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









