







以下内容为自己学习记录,可供参考。
1.创建新实例
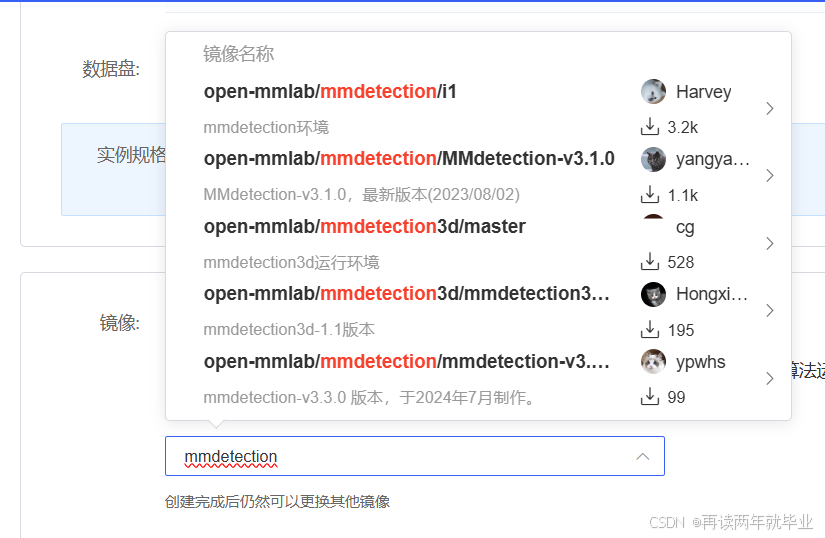
首先,在平台租用实例时,可以在社区镜像中选择mmdetection,这样租用的实例就拥有mmdetection所需要的所有配置。(建议下载点击量第二的那个,第一个使用的是mmcv-full)
2.创建自己的coco数据集
我使用的标注软件为labelme,获取的标注文件是json文件。需要将json文件转换为coco数据集格式。将json文件和图片文件放在同一文件夹中输入。
# 命令行执行: python labelme2coco.py --input_dir images --output_dir coco --labels labels.txt
# 输出文件夹必须为空文件夹
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
from sklearn.model_selection import train_test_split
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def to_coco(args, label_files, train):
# 创建 总标签data
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
# 创建一个 {类名 : id} 的字典,并保存到 总标签data 字典中。
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip() # strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
if class_id == -1:
assert class_name == "__ignore__" # background:0, class1:1, ,,
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name, )
)
if train:
out_ann_file = osp.join(args.output_dir, "annotations", "instances_train2017.json")
else:
out_ann_file = osp.join(args.output_dir, "annotations", "instances_val2017.json")
for image_id, filename in enumerate(label_files):
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0] # 文件名不带后缀
if train:
out_img_file = osp.join(args.output_dir, "train2017", base + ".tif")
else:
out_img_file = osp.join(args.output_dir, "val2017", base + ".tif")
print("| ", out_img_file)
# ************************** 对图片的处理开始 *******************************************
# 将标签文件对应的图片进行保存到对应的 文件夹。train保存到 train2017/ test保存到 val2017/
img = labelme.utils.img_data_to_arr(label_file.imageData) # .json文件中包含图像,用函数提出来
imgviz.io.imsave(out_img_file, img) # 将图像保存到输出路径
# ************************** 对图片的处理结束 *******************************************
# ************************** 对标签的处理开始 *******************************************
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
# out_img_file = "/coco/train2017/1.jpg"
# out_ann_file = "/coco/annotations/annotations_train2017.json"
# osp.dirname(out_ann_file) = "/coco/annotations"
# file_name = ..\train2017\1.jpg out_ann_file文件所在目录下 找 out_img_file 的相对路径
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1999
1999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









