







【Flink-1.17-教程】-【五】Flink 中的时间和窗口(2)时间语义
1)Flink 中的时间语义
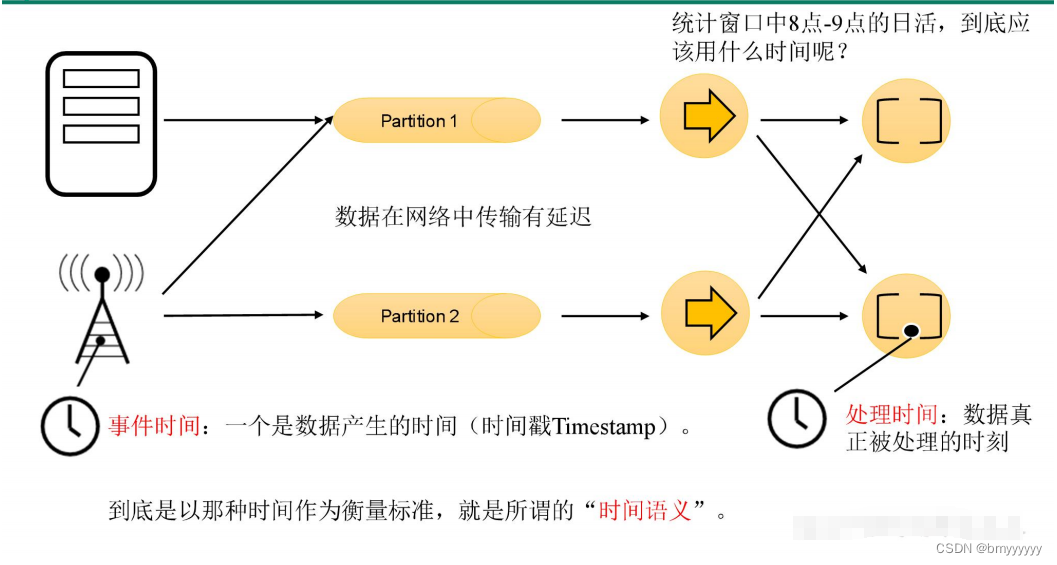
在流处理中,时间是一个非常核心的概念,是整个系统的基石。比如,我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口的内数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个应用使用什么样的时间语义。本文将介绍 Flink 的 Event Time、Processing Time 和 Ingestion Time 三种时间语义。
2)时间语义的分类
2.1.处理时间(process time)
处理时间是指的执行操作的各个设备的时间。对于运行在处理时间上的流程序,所有的基于时间的操作(比如时间窗口)都是使用的设备时钟,比如,一个长度为1个小时的窗口将会包含设备时钟表示的1个小时内所有的数据。
假设应用程序在 9:15am分启动,第1个小时窗口将会包含9:15am到10:00am所有的数据,然后下个窗口是10:00am-11:00am,等等。
处理时间是最简单时间语义,数据流和设备之间不需要做任何的协调,他提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,处理时间没有办法保证确定性,容易受到数据传递速度的影响
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









