






k8s 开船记-首航:博客站点从 docker swarm 切换到 k8s

昨天晚上,我们将博客站点的生产环境从 docker swarm 集群切换到了 k8s 集群,开船到目前,航行非常平稳,可以说首航成功!
k8s 集群是我们用10台阿里云服务器自己搭建的,1台 master 配置是2核4G,9台 nodes 配置都是4核8G,kubernetes 版本是 1.16.3 。
博客站点请求入口没有走 ingress ,直接通过 service 监听 30080 端口,阿里云负载均衡转发请求到该端口。
![]()
apiVersion: v1
kind: Service
metadata:
name: blog-web
namespace: production
spec:
type: NodePort
selector:
app: blog-web
ports:
- nodePort: 30080
port: 80
targetPort: 80
![]()
博客站点(blog-web)是通过 DaemonSet 方式部署的,每个 node 都会运行 blog-web pod ,这样的好处是可以将负载均分到各个 node 进行处理,而且在新服务器添加到集群后可以立即分担负载。
![]()
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: blog-web
namespace: production
labels:
name: blog
...
![]()
在将部署环境从 docker swarm 切换到 k8s 的过程中,主要遇到2个问题。
一个问题是服务名称包含下划线的问题。docker swarm 服务名称中默认就包含下划线,k8s 坚决不允许服务名称中包含下划线,而我们的博客应用调用的一些 web api 用的是包含下划线的主机名,为了减少代码修改工作,我们采用了变通的解决方法,借助 coredns 在 dns 解析时重写主机名。
rewrite stop {
name regex ([a-zA-Z0-9-]+)_([a-zA-Z0-9-]+).$ {1}-{2}.production.svc.cluster.local
answer name ([a-zA-Z0-9-]+)-([a-zA-Z0-9-]+)\.production\.svc\.cluster\.local\.$ {1}_{2}
}
另一个问题是 k8s 的 yaml 配置文件不支持直接读取环境变量,docker swarm 是直接支持的,通过 envsubst 搞定。
envsubst < daemonset-production-blog-web.yaml | kubectl apply -f -
匆忙之间写了这篇开船首航记,不到之处,望谅解。
最后推荐一篇对于了解 k8s 非常有帮助的英文博文 —— An introduction to Kubernetes 。
k8s 开船记-触礁:四涡轮发动机撞坏3个引发502故障

(图片来自网络)
非常抱歉,这次开船触礁故障给您带来麻烦了,请您谅解。
在我们昨天发布 k8s 开船记首航博文后,有园友在评论中发来贺词——“泰坦尼克号出发了[狗头]”,借此吉言,今天船就触礁了,还好不是冰山。在触礁后,我们收到了唯一一封贺电,贺电署名——“隔壁正在打酱油的 docker swarm 集群”。
触礁时间发生在今天上午 10:18~10:30 左右,当时航行用的是四涡轮发动机(4个nodes)。
10:18 左右开始,3与4号发动机(k8s-n3与k8s-n4节点)被撞坏熄火,重新点火屡屡失败(重启 blog-web pod 失败),syslog 错误日志如下。
Dec 14 10:18:01 k8s-n3 kubelet[702]: E1214 10:18:01.739352 702 pod_workers.go:191]
Error syncing pod 9b27ac6f-5518-4e12-862f-63b1254457d2 ("blog-web-r4zld_production(9b27ac6f-5518-4e12-862f-63b1254457d2)"), skipping: failed to "StartContainer" for "blog-web" with CrashLoopBackOff: "back-off 2m40s restarting failed container=blog-web pod=blog-web-r4zld_production(9b27ac6f-5518-4e12-862f-63b1254457d2)
10:20 左右,2号发动机(k8s-n2)也被撞坏熄火。
Dec 14 10:20:12 k8s-n2 kubelet[703]: E1214 10:20:12.138738 703 pod_workers.go:191]
Error syncing pod 4ab7b193-cf0d-4a41-b83a-689d546acb2f ("blog-web-4dh84_production(4ab7b193-cf0d-4a41-b83a-689d546acb2f)"), skipping: failed to "StartContainer" for "blog-web" with CrashLoopBackOff: "back-off 2m40s restarting failed container=blog-web pod=blog-web-4dh84_production(4ab7b193-cf0d-4a41-b83a-689d546acb2f)"
唯一幸免的是1号发动机(k8s-n1),但是纵使它使尽浑身解数也无法驱动巨轮前进,于是只能停船发 502 求救信号。
我们收到求救信号后,通过下面的命令手动修改了 livenessProbe 的超时时间,daemonset 重新部署 pods 后恢复了正常。
kubectl edit daemonset blog-web
之后,我们启动了5号发动机(k8s-n5),k8s 尼克号又出发了。
对于故障原因,有待进一步排查。
blog-web daemonset 的健康检查配置:
![]()
livenessProbe:
httpGet:
path: /alive
port: 80
initialDelaySeconds: 10
periodSeconds: 3
readinessProbe:
exec:
command:
- curl
- -H
- 'X-Forwarded-Proto:https'
- --resolve
- www.cnblogs.com:80:127.0.0.1
initialDelaySeconds: 30
periodSeconds: 5
![]()
以下的 syslog 错误日志有待排查确认:
![]()
Dec 14 10:18:53 k8s-n2 dockerd[1045]: time="2019-12-14T10:18:53.719195677+08:00" level=info msg="Container ddf3e4ed0dd63878dd1c87cb63cfd57d712f8719fb097e6c8ef15587eb3f81da failed to exit within 30 seconds of signal 15 - using the force"
Dec 14 10:18:54 k8s-n2 dockerd[1045]: time="2019-12-14T10:18:54.008174148+08:00" level=error msg="stream copy error: reading from a closed fifo"
Dec 14 10:18:54 k8s-n2 dockerd[1045]: time="2019-12-14T10:18:54.056924047+08:00" level=error msg="Error running exec 827374c9541db5b8d69383798c961078cba8fee08d1c8b93e84622b6a9caa61c in container: OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused \"process_linux.go:101: executing setns process caused \\\"exit status 1\\\"\": unknown"
Dec 14 10:18:54 k8s-n2 dockerd[1045]: time="2019-12-14T10:18:54.129287298+08:00" level=warning msg="ddf3e4ed0dd63878dd1c87cb63cfd57d712f8719fb097e6c8ef15587eb3f81da cleanup: failed to unmount IPC: umount /var/lib/docker/containers/ddf3e4ed0dd63878dd1c87cb63cfd57d712f8719fb097e6c8ef15587eb3f81da/mounts/shm, flags: 0x2: no such file or directory"
![]()
k8s 开船记-修船:改 readinessProbe ,去 DaemonSet ,上 Autoscaler

(图片来自网络)
改 readinessProbe
对于昨天 k8s 尼克号发生的触礁事故,我们分析下来主要是2个原因,一是当时4个节点不够用造成部分容器负载过高而宕机,二是 readinessProbe 健康检查配置不合理,造成重启后的容器无法通过健康检查。
skipping: failed to "StartContainer" for "blog-web" with CrashLoopBackOff.
CrashLoopBackOff 是指容器“启动 -> 挂了 -> 又启动了 -> 又挂了…”。(参考资料: Kubernetes Troubleshooting Walkthrough - Pod Failure CrashLoopBackOff)
对于原因一,已改为在访问低峰也用5个节点。
对于原因二,将 readinessProbe 的配置由
readinessProbe:
initialDelaySeconds: 30
periodSeconds: 5
改为
![]()
readinessProbe:
initialDelaySeconds: 40
periodSeconds: 5
successThreshold: 1
failureThreshold: 5
timeoutSeconds: 5
![]()
readinessProbe 健康检查决定 service 是否将请求转发给该容器处理。(参考资料:Kubernetes Liveness and Readiness Probes: How to Avoid Shooting Yourself in the Foot)
initialDelaySeconds 表示在容器启动后进行第一次检查的等待时间(默认是0秒)。
periodSeconds 表示每隔多长时间进行检查(默认是30秒)。
successThreshold 表示几次检查通过才算成功(默认是1次)
failureThreshold 表示几次检查失败才算失败(默认是3次),失败后会重启容器。
timeoutSeconds 检查的超时时间(默认是1秒),当时我们用的就是默认值,而容器中的 ASP.NET Core 应用第一次请求时预热时间比较长,使用默认值很容易造成检查超时,现在改为5秒。
去 DaemonSet
使用 DaemonSet 是因为我们对 k8s 还不熟悉,在用开渔船(docker swarm)的方式驾驶巨轮(k8s),docker swarm compose 中用的是 mode: global ,换到 k8s 后我们就用了对应的替代 DaemonSet ,却不知道 k8s 强大的功能之一 —— 自动伸缩(autoscaling)。昨天故障时,DaemonSet 的部署方式是雪上加霜,部分 pod 挂了,剩下的 pod 即使负载再高,也不会启动新的 pod 分担负载。
在这次修船中将 DaemonSet 改为 Deployment
kind: DaemonSet
kind: Deployment
上 Autoscaler
自动伸缩(autoscaling)这个 k8s 强大的功能之一,让我们体会到了现代化的巨轮与落后的渔船(docker swarm)之间的巨大差别。之前只在云上看到到自动伸缩,现在船上就有,而且使用起来很简单,比如我们需要根据容器的 CPU 占用情况自动伸缩 pod ,采用了下面的配置。
![]()
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: blog-web
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: blog-web
minReplicas: 5
maxReplicas: 12
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 90
![]()
关于自动伸缩的参考资料:
* Horizontal Pod Autoscaler Walkthrough
* How to autoscale apps on Kubernetes with custom metrics
这次修船到此,预计明天开上新船。
k8s 开船记:升级为豪华邮轮(高可用集群)与遇到奇怪故障(dns解析异常)

之前我们搭建的 k8s 集群只用了1台 master ,可用性不高,这两天开始搭建高可用集群,但由于之前用 kubeadm 命令创建集群时没有使用 --control-plane-endpoint 参数,无法直接升级现有集群,只能重新创建高可用(High-Availability)集群。
高可用集群的原理很简单,多台 master ,每台都保存集群数据(etcd),所有 nodes 通过专门搭建的负载均衡访问 api server ,这样当部分 master 宕机时,对集群正常运行无影响。
我们用了 3 台 master ,但是在第 1 台 master 服务器开始创建高可用的集群时,遇到了一个做梦也没想到的问题。
kubeadm init \
--kubernetes-version v1.16.3 \
--control-plane-endpoint "k8s-api:6443" --upload-certs \
--image-repository registry.aliyuncs.com/google_containers \
--pod-network-cidr=192.168.0.0/16 --v=6
为了省事,我们没有自己另外部署负载均衡,而是直接使用了阿里云内网负载均衡( 四层 tcp 转发),在 master 的 hosts 中将上面的 k8s-api 解析到阿里云负载均衡的 IP 。

但是创建集群总是失败,错误信息如下
[kubelet-check] Initial timeout of 40s passed.
I1217 08:39:21.852678 20972 round_trippers.go:443] GET https://k8s-api:6443/healthz?timeout=32s in 30000 milliseconds
排查后发现是因为阿里云四层负载均衡不支持转发请求给同一台服务器,也就是发请求的服务器与转发的后端服务器不能是同一台服务器。
后来我们采用了一个变通的方法解决了问题,在 master 服务器上不将 k8s-api 解析到负载均衡的 IP ,而是解析到 master 自己的 IP ,只在 nodes 上解析到负载均衡 IP 。
当我们搭建好高可用集群,还没来得及享受高上大的豪华邮轮,就遭遇一个奇怪的 dns 解析问题。在容器内解析主机名时速度很慢,有时解析成功,有时解析失败,不管是 k8s 的 service 名称,还是手工添加的 dns 解析记录,还是阿里云的 redis 服务,都有这个问题。dns 解析服务用的是 coredns ,pod 网络用的是 calico 。当时集群中有 3 台 maste 与 1 台 node ,开始以为是 k8s 网络的问题, 搭建这个集群时开始用的是 flannel 网络,后来改为 calico ,但折腾很长时间都无济于事,昨天晚上为此精疲力尽,一气之下在睡觉之前将集群中的所有服务器都关机。
今天开机后,又遇到了一个做梦也没想到的事情,问题竟然神奇的消失了,本以为这只是升级豪华邮轮过程中的一个小插曲。
今天下班前,又又遇到了一个做梦也没想到的事情,线上在用的之前搭建的只有 1 台 master 的非高可用集群中部分 nodes 也出现了同样的 dns 解析问题(用的是 flannel 网络),根据刚刚学到的经久不衰的绝招,将出现问题的 nodes 重启,问题立马消失。
2个不同的集群,使用的是不同的 pod 网络,而且使用的是不同的网络地址段(分别是 192.168.0.0/16 与 10.244.0.0/16),竟然出现了同样的 dns 解析问题,而且都通过重启可以解决,这个诡异的问题给我们的开船记出了一道难题。
但是由俭入奢易,由奢入俭难,豪华邮轮已经准备好了,我们再也不想开渔船了(docke swarm),不管怎么样,船还得继续开。
【更新】
12月19日 22:37:对于 dns 解析问题,根据 TianhengZhou 在评论中的建议部署了 nodelocaldns ,部署所采用的脚本如下。
sed 's/k8s.gcr.io/gcr.azk8s.cn\/google_containers/g
s/__PILLAR__DNS__SERVER__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml |
kubectl apply -f -
参考资料:
k8s 开船记-故障公告:自建 k8s 集群在阿里云上大翻船
非常非常抱歉,新年上班第一天, 在今天阿里云上气候突变情况下,由于我们开船技术差,在今天 10:15~12:00 左右的访问高峰,我们竟然把船给开翻了,造成近2个小时整个博客站点无法访问,由此给您带来很大很大的麻烦,恳请您的谅解。
翻船经过如下。
翻船前的船只情况
博客站点正在使用的 k8s 集群一共用了 9 台 worker 节点服务器,在访问低峰时用 5 台,另外 4 台处于关机状态,在进入访问高峰前启动。所以我们用 cron 定时任务在工作日每天早上启动 4 台服务器,每天晚上关闭 4 台服务器。为了节约成本,这 4 台服务器用的是阿里云抢占式实例,由此带来的风险是如果启动时当前可用区对应的实例库存不足,就会启动失败。
还有一个正在搭建中的高可用 k8s 集群,运行着 1 台 master 与 1 台 worker 节点,另外 2 台 master 与 1 台 worker 处于关机状态。
在 k8s 集群之前使用的 docker swarm 集群处于待弃用状态,运行着 1 台 manager 与 1 台 worker 节点,其他节点都处于关机状态,用的也是阿里云抢占式实例。
风云突变,船只颠簸
今天新年上班第一天,阿里云上生意非常火爆,我们的服务器所在可用区的所有4核8G的抢占式实例全部售罄,造成定时启动 k8s 集群节点服务器的任务全部失败,仅有的 5 台服务器在访问高峰不堪重负,开始出现 502 ,当我们发现后,尝试通过阿里云 ecs 控制台启动这些服务器,但依然因库存不足而无法启动。
操作有错误发生:
i-bp10c3nww9y26s9yppcq : 库存不足,请您尝试其它类型的实例规格 或者 其它可用区/地域的实例。您可以选择变配到其他规格,然后启动。更改实例规格
RequestId: 86752D85-39F0-4FEC-875B-80A3269D0B23
紧急自救,却遭意外雷击而翻船
手动启动服务器失败后,我们赶紧新购服务器添加到集群,本以为等服务器加好就能恢复,哪知却遭遇新的意外情况,新加服务器上所有博客站点的 pod 都启动失败。
NAME READY STATUS RESTARTS AGE
blog-web-bw87z 0/1 CrashLoopBackOff 4 4m36s
Pod 启动失败是因为其中的博客站点容器 dns 解析失败,无法解析所依赖的服务的地址。
接着情况变得越来越严重,不仅新加服务器因 dns 解析问题无法启动 pod ,而且集群中已有服务器也因为这个问题无法启动 pod 。本来已有 5 台还能支撑部分请求,但由于这个意外的 dns 解析问题,集群中除了1-2台博客应用的 pod 还在运行,其他全挂了,这时整个博客站点全是 502 错误,k8s 巨轮就这么翻了。
救援行动,旧渔船挺身而出
巨轮翻了后,我们开始救援行动,首当其冲就是另外一艘建造中的更高级的巨轮 —— k8s 高可用集群,新购服务器加到这个集群,准备用这个集群处理负载,哪知这个集群也出现了异常情况,pod 也是无法启动,一直处于 ContainerCreating 状态。
NAME READY STATUS RESTARTS AGE
blog-web-b2ggt 0/1 ContainerCreating 0 4m48s
Error from server: Get https://10.0.2.82:10250/containerLogs/production/blog-web-b2ggt/blog-web: dial tcp 10.0.2.82:10250: connect: connection refused
这时唯一的救命稻草就是那艘准备弃用的旧渔船 —— docker swarm 集群,这个集群中处于关机状态的节点服务器也因为库存不足而无法启动,只能新加服务器,赶紧把 k8s 集群中的那些服务器拿过来用镜像更换系统后加入 docker swarm 集群。
sudo rm -rf /var/lib/docker/swarm && \
service docker restart && \
docker swarm join --token xxx 10.0.151.251:2377
当 docker swarm 集群投入使用并加到一定量的服务器后,博客站点才恢复正常。
开船的迷茫
恢复正常后,我们立即去排查出现 dns 解析问题的 k8s 集群,发现所有 worker 节点都出现了 dns 解析问题, 上次我们也被 dns 解析问题坑过(详见 k8s 开船记:升级为豪华邮轮(高可用集群)与遇到奇怪故障(dns解析异常)),只是上次只有部分节点出现这个问题,这次是所有 worker 节点,上次是通过重启服务器解决的,难道这次也要重启才能解决?
于是将 worker 节点全部重启,重启后所有 pod 都正常运行了,这时我们恍然大悟,后悔莫及,当时营救翻船最简单快速的方法就是重启所有 worker 节点服务器。
开着旧渔船,回想着靠岸待修理的巨轮,望着茫茫大“云”,我们更加迷茫了。使用 docker swarm 时多次遭遇奇怪的网络问题,通过重启节点服务器解决,开始我们怀疑水(云),后来我们怀疑船(docker swarm),于是下定决心换掉渔船,换上巨轮(k8s),结果又遇到到了奇怪的网络问题(dns 解析问题是网络问题引起的),现在我们该怀疑谁呢?.
对于这次大翻船,最重要的原因是我们过多地使用了抢占式实例,是我们的过错,我们会吸取教训,调整服务器的部署。
这次大故障给您带来麻烦了,再次恳请您的谅解。
.NET Core 开车记:Data Protection Key 过期问题与登录页面访问慢
K8s 船还没修好,.net core 车又出了问题,开着 k8s 豪华邮轮、飚着 .net core 极品飞车的好事真是多磨。
自从我们用上 .net core ,就一直被 .net core 的一个慢性病所折磨,这个病叫 Data Protection Key 新陈代谢综合症,通常3-6个月发作一次。发作时的症状是新登录用户在登录后依然是未登录状态。病因是 Data Protection Key 默认3个月刷新一次,在这个刷新的新陈代谢阶段,新旧 key 并存,新的登录 cookie 用新的 key 进行加密/解密,旧的登录 cookie 用旧的 key 解密,但有时某种未知情况会造成新陈代谢时出现功能性紊乱,新 key 加密的 cookie 却用旧 key 解密失败,造成解密失败,登录 cookie 失效。
昨天下班的时候这个新陈代谢综合症又发作了,幸好我们及时发现,立即采取急救措施,重启所有应用恢复了正常。在急救时,我们犯了一个错,忘了重启了文件上传应用,结果造成一段时间无法上传图片。
Keys have a 90-day lifetime by default. When a key expires, the app automatically generates a new key and sets the new key as the active key. As long as retired keys remain on the system, your app can decrypt any data protected with them. (From docs.microsoft.com)
新陈代谢综合症急救好之后,开车没多久,昨天晚上又出现了新的病情,用户登录站点突发急性消化不良症,访问登录页面响应速度很慢。排查后发现大量 http get 请求涌向登录页面,对应容器的 CPU 占用一直 150% 左右(平时不到 20%)。虽然源于大量请求,但是让人想不通的是这个登录页面只是显示一下 mvc 视图,没有耗资源的操作,没有任何数据库访问操作,即使这么大请求也应该能撑住。尝试给登录页面加上 ResponseCache ,问题依旧。尝试启动更多容器处理请求,问题依旧。
进一步排查中发现这个突发急性症状起源于一篇博文被设置为登录后才能访问,大量访问这篇博文的请求都跳转到了登录页面(这些请求本身也比较异常,可能是机器请求),于是在登录页面的 mvc action 中屏蔽这些请求,但病情没有丝毫改善,这时可以确认性能瓶颈不在 mvc action 。
知道药用错地方后,立即跳出当前 mvc action ,放眼整个请求处理管线上的那些 middeware 。望着日志中不断出现的大量错误,一个 middlware 立马映入眼帘,它就是用于给 serilog 日志提供更多上下文信息的 LogEnrichmentMiddleware ,在这个 middleware 中加上屏蔽异常请求的代码后立马药到病除,急性消化不良症就这样完成了急救。
![]()
public class LogEnrichmentMiddleware
{
private static readonly ILogger Logger = Log.ForContext<LogEnrichmentMiddleware>();
private readonly RequestDelegate _next;
public LogEnrichmentMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task Invoke(HttpContext httpContext)
{
// 屏蔽异常请求
if (httpContext.Request.Query.TryGetValue("returnUrl", out var returnUrl) &&
WebUtility.UrlDecode(returnUrl) == "***")
{
httpContext.Response.StatusCode = StatusCodes.Status404NotFound;
return;
}
var properties = new ILogEventEnricher[]
{
new PropertyEnricher("RequestUrl", httpContext.Request.GetDisplayUrl()),
new PropertyEnricher("RequestMethod", httpContext.Request.Method),
new PropertyEnricher("UserAgent", httpContext.Request.Headers[HeaderNames.UserAgent].ToString()),
new PropertyEnricher("Ip", httpContext.Connection.RemoteIpAddress.ToString())
};
using (LogContext.Push(properties))
{
await _next(httpContext);
var statusCode = httpContext.Response.StatusCode;
if (statusCode >= 400 && statusCode != 404)
Logger.Warning("Unsuccessful response {StatusCode}", httpContext.Response.StatusCode);
}
}
}
![]()
抱歉,这2个问题给您带来麻烦了,请您谅解。我们会进一步分析病因,争取根治这2个病症,让 .net core 这辆车飚得更稳。
K8s 开船记-全站登船:Powered by .NET Core on Kubernetes

今天 18:30 左右,我们迈出了 kubernetes 航行的关键一步——全站登船,完成了全站应用部署从 docker swarm 集群向 k8s 集群的切换,以前所未有的决心与信心重新开起这艘巨轮,而这次航行能否成功就看明天访问高峰时狂风巨浪下的表现。
部署在 k8s 上的应用会在页脚显示下面的信息,如果航行失败,"Kubernetes" 会变成 "Linux" 。
Powered by .NET Core on Kubernetes
Kubernetes 集群部署情况如下。
用了3台2核4G阿里云服务器作为 master 搭建了高可用集群,worker 节点目前用了12台4核8G阿里云服务器,明天根据负载情况看是否需要加服务器。
Kuberneres 网络插件使用的是 calico 。
DNS 服务器使用的是 coredns ,由于之前遭遇过因为 dns 解析问题造成翻船,这次部署了 nodelocaldns 在每个节点进行本机 dns 缓存(相关博文)。
Ingress Controller 使用的是 kubernetes 社区维护的 kubernetes/ingress-nginx,还有一个 nginx 公司与社区共同维护的 nginxinc/kubernetes-ingress,我们推荐使用前者(相关博文)。
博客站点的部署采用了 HPA(Horizontal Pod Autoscaler) ,基于 CPU 与 QPS 监控指标进行自动伸缩,监控指标数据来自 prometheus (相关博文)。
部署工具用的是 helm ,helm 强大的模板引擎让我们可以用一个模板搞定 90% 以上应用的部署(相关博文)。
目前一共部署了 115 个应用 pod ,56 个应用 service 。
【更新】
11:06~11:10 左右,博客后台出现 502 ,原因是运行中的博客后台 pod 健康检查失败,重新启动的 pod 也健康检查失败,博客后台暂时切换到 docker swarm
【故障公告】部署在 k8s 上的博客后台昨天与今天在访问高峰多次出现 502
非常抱歉,从昨天上午开始,部署在 k8s 集群上的博客后台(基于 .NET Core 3.1 + Angular 8.2 实现)出现奇怪问题,一到访问高峰就多次出现 502 ,有时能自动恢复,有时需要我们手动删除 pod ,由此给您带来麻烦,请您谅解。
我们的应用都部署在同一个 k8s 集群上,就这一个应用出现这个问题,很是奇怪,估计还是应用本身的问题,我们正在进一步排查。
为了避免再次出现这个问题,今天中午我们已经将博客后台暂时单独部署到 docker swarm 集群上。
k8s 开船记-脚踏两只船:用 master 服务器镜像克隆出新集群
自从2020年2月23日 园子全站登船 之后,我们一边感叹“不上船不知道,一上船吓一跳” —— kubernetes 比 docker swarm 强大太多,一边有一个杞人忧天的担忧 —— 假如整个 kubernetes 集群宕机怎么办?
随着在船上的日子越来越长,随着对 kubernetes 越来越依赖,我们的杞人忧天也越来越难以挥去...。终于有一天,一个贬义的俗语让我们豁然开朗 —— “脚踏两只船”,如果只有1个集群,kubernetes 再怎么工业级标准,也无法让我们高枕无忧,唯有2个集群。于是,我们找到了自己的解忧之道 —— 再开一艘船。
再开一艘船的前提条件是再造一艘船,而造船的最佳方式显然是从现有的这艘船克隆出一艘新船。对应到我们的 kubernetes 集群是用阿里云 ecs 服务器自己搭建的场景,最佳方式就是用已有集群 master 服务器的阿里云 ecs 镜像创建新集群。
带着这个美好想法,我们开始动手造船 —— 克隆新 kubernetes 集群,但很快就遇到了残酷的现实。k8s天不怕地不怕,就怕名儿换(换IP地址或者主机名),而通过镜像创建的 master 服务器使用的是不同IP地址与主机名,虽然不改主机名不会给新集群带来问题,但是对命名控们来说这是无法接受的,于是修改新 master 的IP地址与主机名成为克隆的2个挑战。
经过努力,我们终于战胜了这2个挑战,成功克隆出了新集群,今天通过这篇博文分享一下主要操作步骤。
背景信息
-
已有集群 master 主机名是 k8s-master0,IP地址是 10.0.1.81
-
新集群 master 主机名是 kube-master0,IP地址是 10.0.9.171
-
已有集群 kubernetes 版本是 1.17.0,新集群 kubernetes 版本是 1.20.2
-
master 服务器操作系统是 ubuntu 18.04
准备工作
-
已有集群 master 服务器 k8s-master0 打快照,创建镜像,用镜像创建新服务器 kube-master0
修改IP地址
从 10.0.1.81 改为 10.0.9.171
1)将 /etc/kubernetes 目录中与IP地址关联的配置替换为新IP地址
涉及的配置文件
/etc/kubernetes/kubelet.conf
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/manifests/kube-apiserver.yaml
通过下面的命令快速完成修改
oldip=10.0.1.81
newip=10.0.9.171
cd /etc/kubernetes
find . -type f | xargs sed -i "s/$oldip/$newip/"
2)给 etcd 启动命令添加参数
打开 /etc/kubernetes/manifests/etcd.yaml,给command 添加
--initial-cluster-state=new
--force-new-cluster
注:不太确定该步骤是否必需,当时第一次修改IP之后集群总是无法正常运行,加了上面的参数才解决,集群正常运行才能进行第4步的操作。
3)通过 iptables 将旧 IP 地址映射到新 IP 地址
iptables -t nat -A OUTPUT -d 10.0.1.81 -j DNAT --to-destination 10.0.9.171
4)修改集群中与旧IP地址相关的配置
通过下面的命令重启集群使之前的修改生效,恢复集群的基本运行,可以执行 kubectl 命令
systemctl daemon-reload && systemctl restart kubelet && systemctl restart docker
替换 kubeadm-config ConfigMap 中的旧IP地址配置
kubectl -n kube-system edit cm kubeadm-config
%s/10.0.1.81/10.0.9.171
5)重新生成 etcd-server 证书(这个证书与IP地址关联)
cd /etc/kubernetes/pki/etcd
rm server.crt server.key
kubeadm init phase certs etcd-server
6)更新当前用户的 .kube/config
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
7)去掉在第2步给 etcd 启动命令添加的参数
# --initial-cluster-state=new# --force-new-cluster
8)重启 kubelet 与 docker 服务使修改生效
systemctl daemon-reload && systemctl restart kubelet && systemctl restart docker
9)新集群恢复正常运行
NAME STATUS ROLES AGE VERSION
k8s-master0 Ready master 376d v1.17.0
注:这时 master 的主机名还没修改
升级 kubernetes 版本
这与克隆新集群没有关系,是我们在克隆过程中顺便升级,详见 Kubernetes 升级过程记录:从 1.17.0 升级至最新版 1.20.2
修改主机名
从 k8s-master0 改为 kube-master0
1)将宿主机 hostname 修改为 kube-master0
hostnamectl set-hostname kube-master0
2)替换 /etc/kubernetes/manifests 中与主机名相关的配置
oldhost=k8s-master0
newhost=kube-master0
cd /etc/kubernetes/manifests
find . -type f | xargs sed -i "s/$oldhost/$newhost/"
3)导出集群中 k8s-master0 的 node 配置文件
kubectl get node k8s-master0 -o yaml > kube-master0.yml
4)将配置文件中的 k8s-master0 替换为 kube-master0
sed -i "s/k8s-master0/kube-master0/" kube-master0.yml
5)通过 etcdctl 命令从 etcd 数据库中删除 /registry/minions/k8s-master0
docker exec -it $(docker ps -f name=etcd_etcd -q) /bin/sh
etcdctl --endpoints 127.0.0.1:2379 --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key /registry/minions/k8s-master0
运行上面的删除命令后,k8s-master0 就会从 kubectl get nodes 的输出列表中消失。
6)用之前导出并修改的 node 配置文件部署 kube-master0
kubectl apply -f kube-master0.yml
部署后 kube-master0 出现中 kubectl get nodes 的输出列表中,但处于 NotReady 状态
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-master0 NotReady control-plane,master 21h v1.20.2
在这个地方折腾了不少时间,其实问题很简单,kubelet 使用的证书是与主机名绑定的,修改主机名后证书失效了。
7)重新生成 kubelet 使用的证书
查看 /etc/kubernetes/kubelet.conf
users:
- name: default-auth
user:
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
用 openssl 命令查看证书绑定的 common name (CN)
$ openssl x509 -noout -subject -in kubelet-client-current.pem
subject=O = system:nodes, CN = system:node:k8s-master0
证书绑定的是旧主机名,需要针对新主机名重新生成证书
kubeadm init phase kubeconfig kubelet
运行上面的命令重新生成证书后,/etc/kubernetes/kubelet.conf 中 users 部分变成下面的内容:
users:
- name: system:node:kube-master0
user:
client-certificate-data:
***...
client-key-data:
***...
重启 kubelet
systemctl restart kubelet
kubelet 重启后,kube-master0 就进入了 Ready 状态
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-master0 Ready control-plane,master 18h v1.20.2
到此,修改IP地址与主机名已成功完成。
新船启航
生成 node 加入集群的命令
$ kubeadm token create --print-join-command
通过生成的 join 命令加入新的 node
kubeadm join k8s-api:6443 --token ***** --discovery-token-ca-cert-hash *****
删除所有旧的 NotReady 状态的 node
kubectl delete node $(kubectl get nodes | grep NotReady | cut -d " " -f1)
克隆出的新船启航!
NAME STATUS ROLES AGE VERSION
kube-master0 Ready control-plane,master 21h v1.20.2
kube-node1 Ready <none> 7d17h v1.20.2
kube-node2 Ready <none> 6d16h v1.20.2
kube-node3 Ready <none> 5d19h v1.20.2
参考资料:
【故障公告】突然猛增的巨量请求冲垮一共92核CPU的k8s集群
非常抱歉,今天下午2点左右开始,博客站点突然猛增的巨量请求让k8s集群的节点服务器不堪重负,造成网站无法正常访问,由此给您带来麻烦,请您谅解。
当时k8s集群一共6台node服务器,2台32核64G,2台8核64G,1台8核16G,1台4核6G,博客站点一共跑了19个pod,如果不是突然猛增的巨量请求,可以稳稳撑住。
但是今天下午的请求排山倒海,比昨天还要高(昨天GA统计的UV超过1000万,其中有很多异常请求),服务器CPU们拼尽全力也无法扛住,最终兵败如山倒。
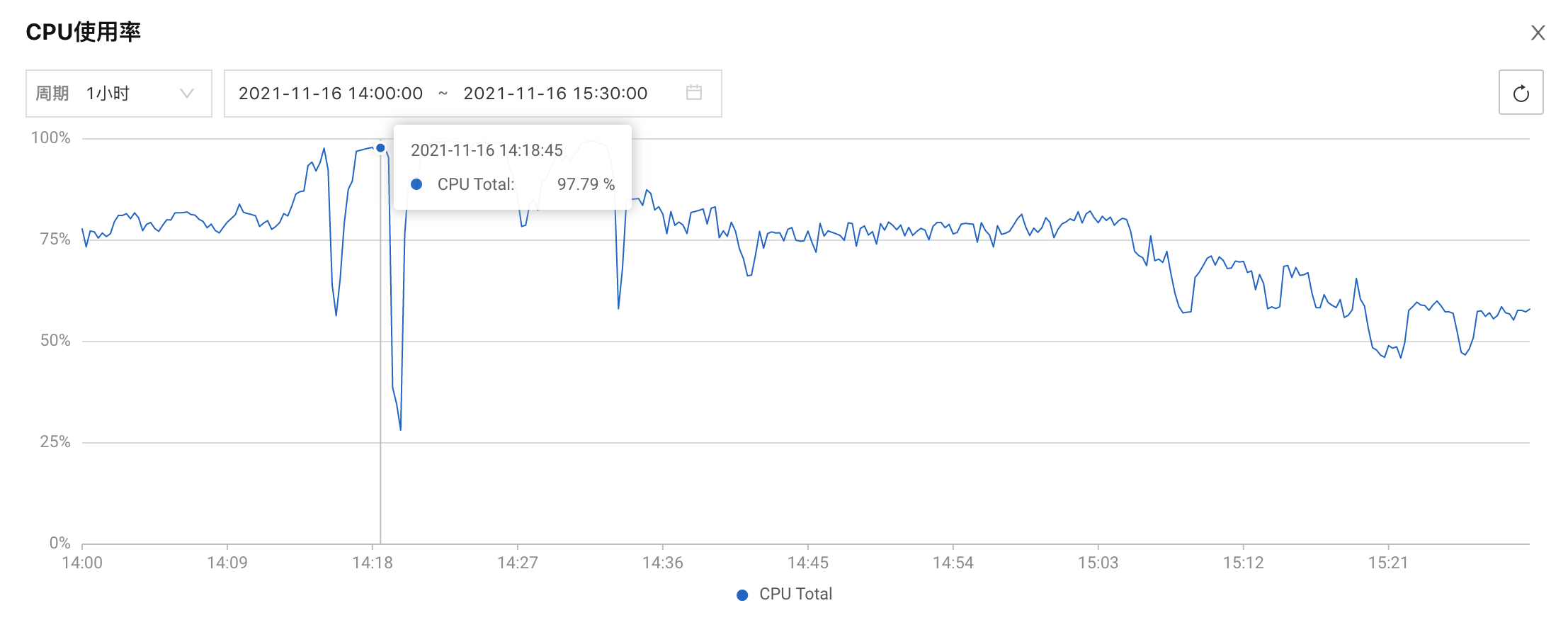
发现故障后,我们开始加服务器,一共加了5台服务器(2台8核64G,1台16核64G,2台4核8G),并逐步将 pod 切换到新加的服务器。
刚刚热身并完成健康检查的 pod 们从未经受如此的高并发考验,切换后刚上战场就倒下的情况频频出现,所以,虽然加了足够的服务器,但恢复正常需要一个过程,一边要等新 pod 撑住,一边发现体力不支的旧 pod 并强制结束,直到 15:30 之后才逐渐恢复正常。
经过初步分析,这些突增的请求多数是非正常用户的请求,这样的请求没有访问热点,每次请求的 url 不一样,让缓存有力使不上。
这次故障就向大家简单汇报到这。
这次的请求量增幅是我们之前从未遇到过的,我们毫无准备,而且目前k8s集群还没实现自动伸缩,我们还需要时间去准备。
非常抱歉,今天下午 16:30-17:15 期间,由于出现突发故障,造成园子无法正常访问,由此给您带来麻烦,请您谅解。
故障经过如下:
16:30 开始,Kubernetes 集群上博客站点的部分 pod 出现请求执行时间慢(5-10秒)的问题。
16:43 开始,请求执行时间慢的问题更加严重,开始出现执行时间超过10秒的请求。
16:50 开始,出现大量数据库连接超时的日志:
System.Data.SqlClient.SqlException (0x80131904): Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
同时数据库服务器的 CPU 从正常时期的 30% 以下飙升至 45% 多。
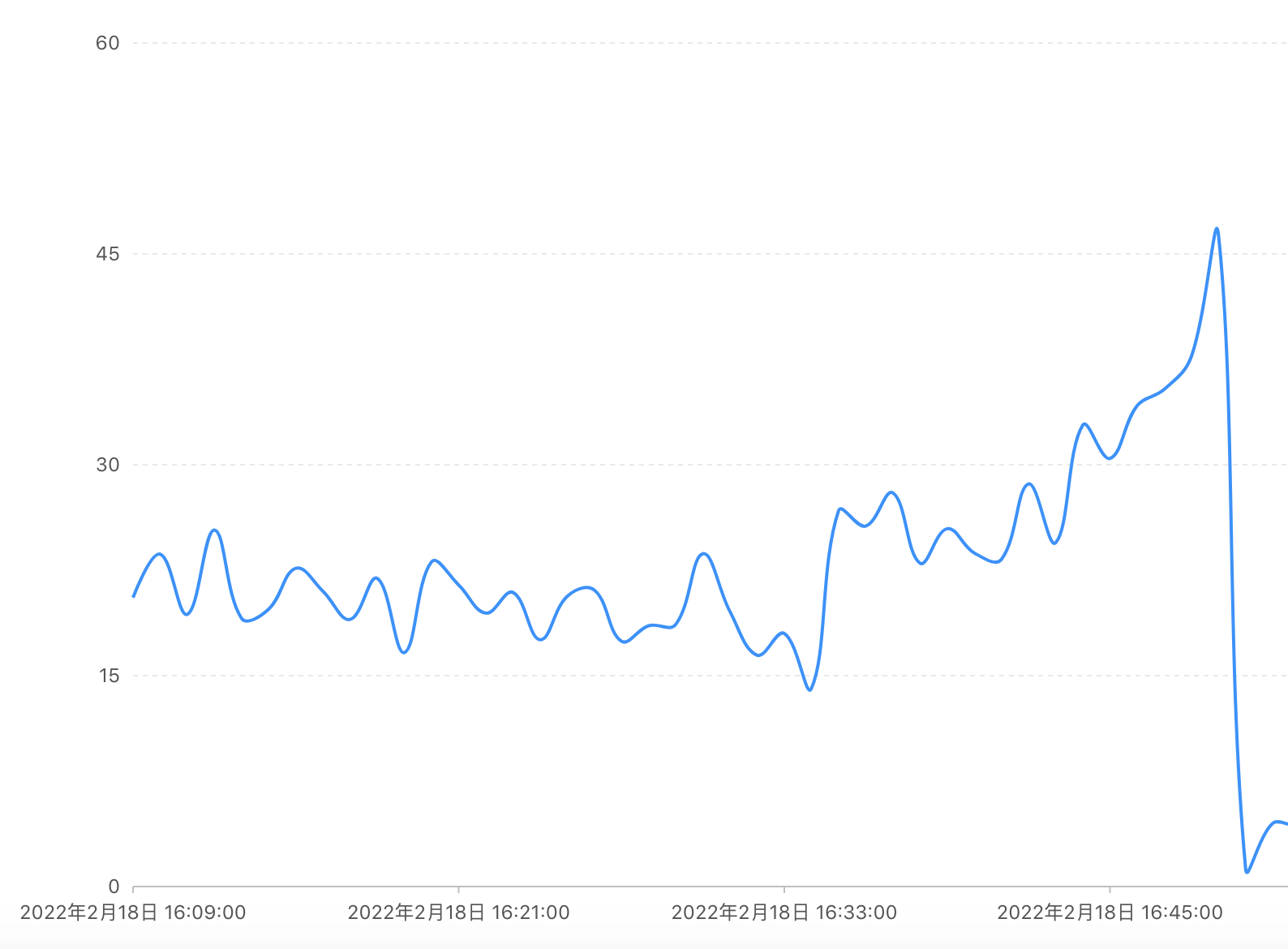
这时我们判断数据库服务器可能会超载,于是做了一个艰难的决定——按下“高速中换轮胎”的紧急按钮,启动了数据库的主备切换。

16:55 左右完成主备切换,但数据库的主备切换会造成 pod 因健康检查失败而重启,在访问高峰的高并发请求下,重启后的 pod 很容易出现不堪重负的无奈情况。
直到 17:10 左右才基本恢复。
最后剩下一款体质较差的 pod,重启后一接入负载总是不堪重负,落到它上面的请求就响应缓慢,拿它一点办法没有。
后来,急中生笨方法,既然体质弱的现实无法改变,那就接受这个现实,不让它干活就行,怎么让它不干活呢?在旧 pod 被删除之后与新 pod 启动完成健康检查之前,这个阶段 pod 是不干活的,只要让它一直处在这个阶段就行。于是盯着这款 pod,一等它完成健康检查有负载进来就删除它,用这个笨方法熬过访问高峰,体质弱的 pod 就能继续干活了。
(故障完)
【故障公告】k8s 开船记:增加控制舱(control-plane)造成的翻船
春节期间我们更换了 kubernetes 生产集群,旧集群的 kubernetes 版本是 1.17.0,新集群版本是 1.23.3,新集群上部署了 dapr,最近准备将更多独立部署的服务器部署到 k8s 集群上,比如 redis, memcached, mongodb。
新集群和旧集群一样都是高可用集群,但新集群开始只用了 1 个 control-plane 节点,今天本来的任务是给新集群再增加 2 个 control-plane 节点,实现高可用。
如何加入 control-plane 节点呢? k8s 没有直接提供生成 join 命令的命令,下面的命令只能用于加入 worker 节点。
kubeadm token create --print-join-command
之前我们是在创建集群的时候,在执行 kubeadm init 命令之后就操作加入 control-plane 节点,kubeadm init 会生成加入命令
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8s-api:6443 --token ****** \
--discovery-token-ca-cert-hash ****** \
--control-plane --certificate-key ******
上面的命令实际上就是 token create --print-join-command 的输出加上 --control-plane 与 --certificate-key,但之前使用的 certificate-key 已经过期。
开始我们用下面的命令生成 certificate-key 加入集群
kubeadm certs certificate-key
但加入失败,报错信息如下
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
error execution phase control-plane-prepare/download-certs: error downloading certs: error downloading the secret: Secret "kubeadm-certs" was not found in the "kube-system" Namespace. This Secret might have expired. Please, run kubeadm init phase upload-certs --upload-certs on a control plane to generate a new one
于是改用 upload-certs 命令
$ kubeadm init phase upload-certs --upload-certs
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
*****
将 upload-certs 命令生成的 certificate-key 用于 kubeadm join 命令,这个 key 果然可以,但是在加入过程中卡在了下面的地方
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
[kubelet-check] Initial timeout of 40s passed.
本以为新 control-plane 节点加入不了不会影响现有集群的正常运行,但一个残酷的现实突然而至 —— 已有且仅有的那台 control-plane 上 api-server 容器突然无法启动了,syslog 中的其中一条错误信息如下
"Unable to authenticate the request due to an error" err="Post "https://k8s-api:6443/apis/authentication.k8s.io/v1/tokenreviews": dial tcp 10.0.9.171:6443: connect: connection refused"
这时虽然 api-server 不能正常工作,但 worker 节点上的 pod 都正常运行,应用暂时没有受影响。
面对这样如履薄冰的场景,我们首先想到的是先恢复旧集群,将负载切换到旧集群,然后从容地处理新集群的问题,但故障如此会开玩笑,旧集群的 api-server 竟然也无法正常启动。
CONTAINER ID IMAGE COMMAND CREATED STATUS
0f30ff71a13d 0cae8d5cc64c "kube-apiserver --ad…" 5 seconds ago Up 3 seconds
命运会作弄人,故障也学会了。
面对如履薄冰与故障的作弄,我们做出了一个铤而走险的决定 —— 更新所有证书,之前成功操作过,但当时集群中没有负载。
用下面的命令三下五除二地完成了证书更新
$ cd /etc/kubernetes/pki/$ mv {apiserver.crt,apiserver-etcd-client.key,apiserver-kubelet-client.crt,front-proxy-ca.crt,front-proxy-client.crt,front-proxy-client.key,front-proxy-ca.key,apiserver-kubelet-client.key,apiserver.key,apiserver-etcd-client.crt} ~/$ kubeadm init phase certs all --control-plane-endpoint "k8s-api:6443"$ cd /etc/kubernetes/$ mv {admin.conf,controller-manager.conf,kubelet.conf,scheduler.conf} ~/$ kubeadm init phase kubeconfig all --control-plane-endpoint "k8s-api:6443"
接下来就是重启 control-plane 节点服务器使用更新的证书。
重启的结局却是 —— 满园尽是502
走险失败后立即进入紧急抢险,用当前 control-plane 节点今天凌晨的快照创建镜像,用镜像重置整个系统。
重置后的 control-plane 节点成功启动后,从 control-plane 节点上看集群应该恢复了正常,worker 节点都处于 ready 状态,绝大多数 pod 都处于 running 状态,但是 pod 中的应用却不能正常工作,比如连不上其他服务、ingress 规则失效等。
开始以为要将所有 worker node 退出并重新加入集群才能恢复,但是在第1个 worker node 上操作退出时却卡在下面的地方
$ kubeadm reset
[reset] Unmounting mounted directories in "/var/lib/kubelet"
后来想到重启所有 worker node 试试,果然是任何时候重启大招不能忘,重启后很快一切恢复正常。
非常抱歉,今天 19:10~19:50 期间由于 k8s 集群操作引发全站全站故障,由此给您带来很大的麻烦,请您谅解。

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









