






刘二大人lecture5,Exercise5-1解答
import torch
import matplotlib.pyplot as plt
import numpy as np
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model1 = LinearModel()
criterion1 = torch.nn.MSELoss(size_average=False)
optimizer1 = torch.optim.SGD(model1.parameters(),lr=0.01)
model2 = LinearModel()
criterion2 = torch.nn.MSELoss(size_average=False)
optimizer2 = torch.optim.Adagrad(model2.parameters(),lr=0.01)
model3 = LinearModel()
criterion3 = torch.nn.MSELoss(size_average=False)
optimizer3 = torch.optim.RMSprop(model3.parameters(),lr=0.01)
loss_list1 = []
loss_list2 = []
loss_list3 = []
for epoch in range(100):
y_pred1 = model1(x_data)
y_pred2 = model2(x_data)
y_pred3 = model3(x_data)
loss1 = criterion1(y_pred1,y_data)
loss2 = criterion2(y_pred2,y_data)
loss3 = criterion3(y_pred3,y_data)
loss_list1.append(loss1.item())
loss_list2.append(loss2.item())
loss_list3.append(loss3.item())
optimizer1.zero_grad()
loss1.backward()
optimizer1.step()
optimizer2.zero_grad()
loss2.backward()
optimizer2.step()
optimizer3.zero_grad()
loss3.backward()
optimizer3.step()
x = np.arange(50)
plt.plot(x,loss_list1[:50],label='loss_sgd')
plt.plot(x,loss_list2[:50],label='loss_Adagrad')
plt.plot(x,loss_list3[:50],label='loss_RMSprop')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()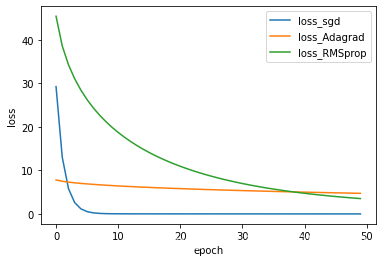


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











