







关于SVM求解最佳解我们有一系列的矩阵运算,还有拉格朗日算子,比较复杂,下面只说如何使用,不深究算数推导。
我们看下面这个图:
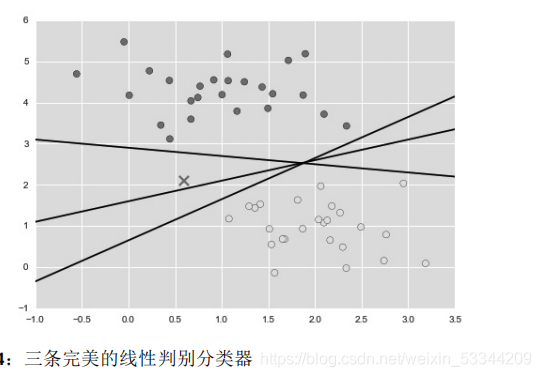
虽然这三个不同的分割器都能完美地判别这些样本,但是选择不同的分 割线,可能会让新的数据点(例如图 5-54 中的“X”点)分配到不同的标签。显然,“画一条分割不同类型的直线”还不够,我们需要进一步思考。
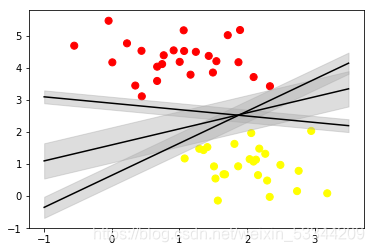
支持向量机提供了改进这个问题的方法,它直观的解释是:不再画一条 细线来区分类型,而是画一条到最近点边界、有宽度的线条。具体形式 如下面的示例所示:
来看看这个数据的真实拟合结果:用 Scikit-Learn 的支持向量机分 类器在数据上训练一个 SVM 模型。这里用一个线性核函数,并将 参数 C 设置为一个很大的数(C很大说明边界很硬,不允许有错误的点分类):
from sklearn.svm import SVC # "Support vector classifier"
model = SVC(kernel='linear', C=1E10)
model.fit(X, y)
Out[5]: SVC(C=10000000000.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
为了实现更好的可视化分类效果,创建一个辅助函数画出 SVM 的 决策边界:
def plot_svc_decision_function(model, ax=None, plot_support=True):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim() # 创建评估模型的网格
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x) xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# 画决策边界和边界
ax.contour(X, Y, P, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--']) # 画支持向量
if plot_support:
ax.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_svc_decision_function(model)
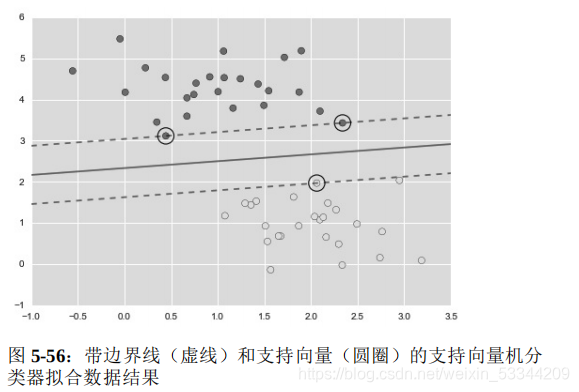
这就是两类数据间隔最大的分割线。你会发现有一些点正好就在边 界线上,在图 5-56 中用黑圆圈表示。这些点是拟合的关键支持 点,被称为支持向量,支持向量机算法也因此得名。在 Scikit- Learn 里面,支持向量的坐标存放在分类器的 support_vectors_ 属性中.
分类器能够成功拟合的关键因素,就是这些支持向量的位置——任 何在正确分类一侧远离边界线的点都不会影响拟合结果!从技术角度解释的话,是因为这些点不会对拟合模型的损失函数产生任何影响,所以只要它们没有跨越边界线,它们的位置和数量就都无关紧要.
这种对远离边界 的数据点不敏感的特点正是 SVM 模型的优点之一。
2、核函数的使用
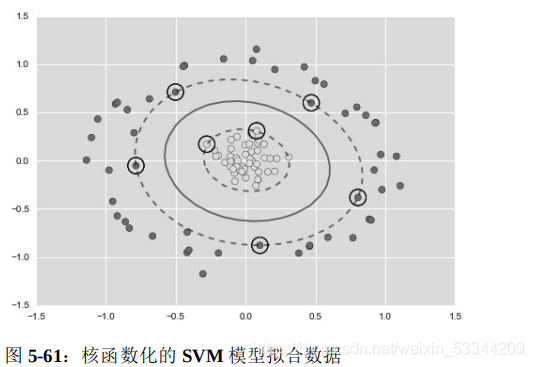
将 SVM 模型与核函数组合使用,功能会非常强大。我们在 5.6 节 介绍基函数回归时介绍过一些核函数。那时,我们将数据投影到多 项式和高斯基函数定义的高维空间中,从而实现用线性分类器拟合 非线性关系。 在 SVM 模型中,我们可以沿用同样的思路。为了应用核函数,引 入一些非线性可分的数据。
例如,一种简单的投影方法就是计算一个 以数据圆圈(middle clump)为中心的径向基函数:
r = np.exp(-(X ** 2).sum(1))
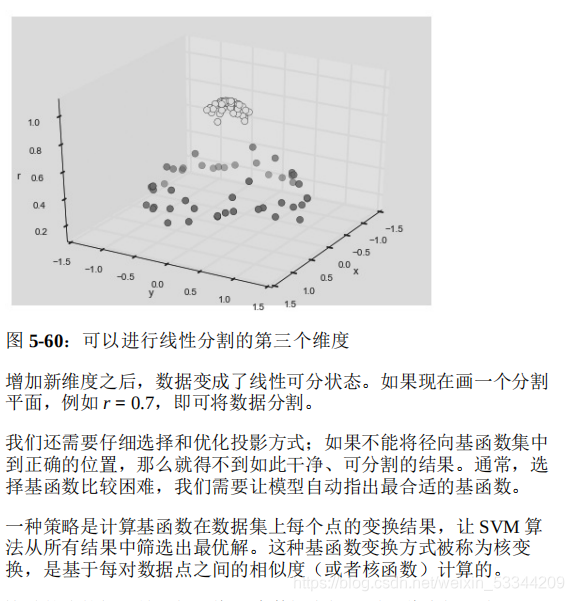
这种策略的问题是,如果将 N 个数据点投影到 N 维空间,当 N 不 断增大的时候就会出现维度灾难,计算量巨大。但由于核函数技巧 提供的小程序可以隐式计算核变换数据的拟合,也就是说,不需要建立完全的 N 维核函数投影空间!这个核函数技巧内置在 SVM 模型中,是使 SVM 方法如此强大的充分条 件。
在 Scikit-Learn 里面,我们可以应用核函数化的 SVM 模型将线性核 转变为 RBF(径向基函数)核,设置 kernel 模型超参数即可
clf = SVC(kernel='rbf', C=1E6) #超参数改为rbf
clf.fit(X, y)
Out[14]: SVC(C=1000000.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
In[15]:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn') plot_svc_decision_function(clf)
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=300, lw=1, facecolors='none');
3、SVM优化:软化边界
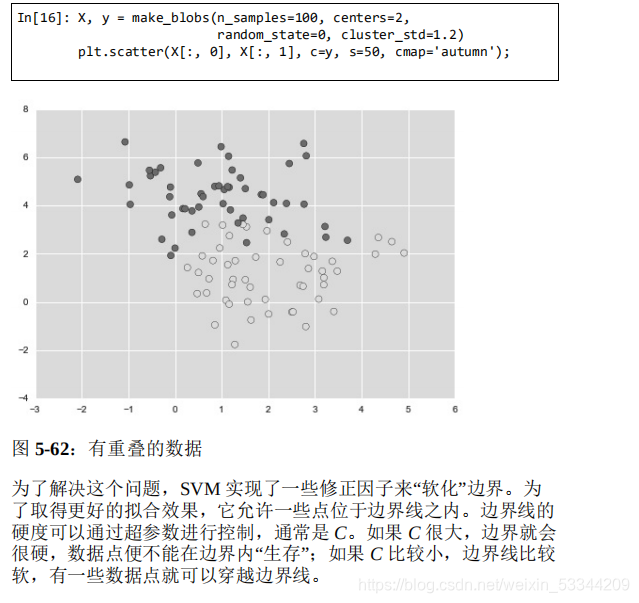
到目前为止,我们介绍的模型都是在处理非常干净的数据集,里面 都有非常完美的决策边界。但如果你的数据有一些重叠该怎么办 呢?例如,有如下所示一些数据
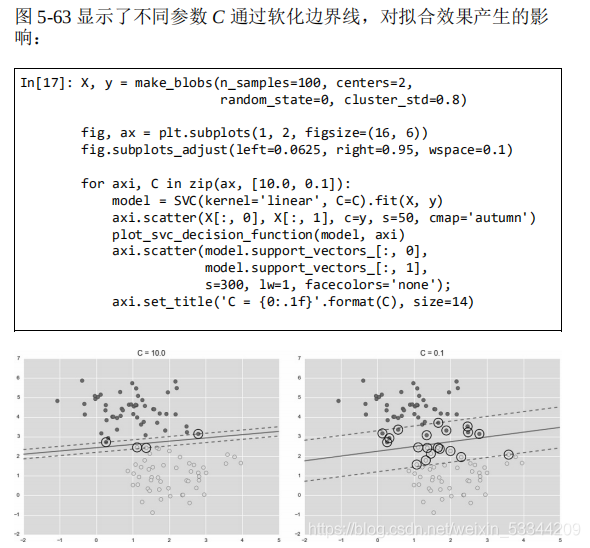
4、总结
前面已经简单介绍了支持向量机的基本原则。支持向量机是一种强大的 分类方法,主要有四点理由。
模型依赖的支持向量比较少,说明它们都是非常精致的模型,消耗内存少。
一旦模型训练完成,预测阶段的速度非常快。
由于模型只受边界线附近的点的影响,因此它们对于高维数据的学习效果非常好——即使训练比样本维度还高的数据也没有问题,而这是其他算法难以企及的。
与核函数方法的配合极具通用性,能够适用不同类型的数据。
但是,SVM 模型也有一些缺点。
随着样本量 N 的不断增加,最差的训练时间复杂度会达到 [N3]; 经过高效处理后,也只能达到 [N2]。因此,大样本学习的计算成 本会非常高。 训练效果非常依赖于边界软化参数 C 的选择是否合理。这需要通过 交叉检验自行搜索;当数据集较大时,计算量也非常大。
预测结果不能直接进行概率解释。这一点可以通过内部交叉检验进 行评估(具体请参见 SVC 的 probability 参数的定义),但是评估过程的计算量也很大。
由于这些限制条件的存在,我通常只会在其他简单、快速、调优难度小的方法不能满足需求时,才会选择支持向量机。但是,如果你的计算资源足以支撑 SVM 对数据集的训练和交叉检验,那么用它一定能获得极好的效果。

















 6194
6194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









