







 本文详细解析了操作系统中进程管理的关键概念,包括写时拷贝技术(Copy-on-Write)的必要性,避免了不必要的内存开销;进程终止时的return0代表正常退出,非零值表示错误,并介绍了通过wait和waitpid函数进行进程等待以回收资源和获取退出信息的重要性,防止僵尸进程产生。同时,探讨了进程退出码的含义和使用,以及exit和_exit的区别。
本文详细解析了操作系统中进程管理的关键概念,包括写时拷贝技术(Copy-on-Write)的必要性,避免了不必要的内存开销;进程终止时的return0代表正常退出,非零值表示错误,并介绍了通过wait和waitpid函数进行进程等待以回收资源和获取退出信息的重要性,防止僵尸进程产生。同时,探讨了进程退出码的含义和使用,以及exit和_exit的区别。
目录
为什么要进行写时拷贝?
因为只会拷贝父子进程修改的数据,其他数据共享,代码共享,且提高了内存的使用率
创建子进程时直接分开数据不行吗?
1. 若创建子进程时,将父进程的数据全部拷贝一份,子进程不一定会全部读取,若全部读取也不一定全部修改,造成空间浪费。
2. 若只将需要修改的数据在创建子进程时进行拷贝,不就可以了。
技术角度不可能实现,除了我们知道的直接修改的数据外,还会有间接被修改的数据(数据都还没有运行,怎么会知道要修改的值有哪些呢)
3. 会增加 fork() 的成本,内存冗余和运行时间
进程终止
写代码时,最后的 return 0 是什么?
return 代表代码跑完了,0是进程的退出码,0代表结果运行成功,非零代表运行失败,不同的非零值代表着不同的原因。return 将退出码返回给父进程;
查看退出码
echo $?在bash中,显示最近一次对应程序执行完毕时的退出码。bash 是我们创建的所有进程的父进程


查看c语言的退出码含义
#include <stdio.h>
#include<string.h>
int main()
{
int i = 0;
for(i=0;i<=100;i++)
{
printf("[%d]: %s\n",i,strerror(i));
}
return 0;
}
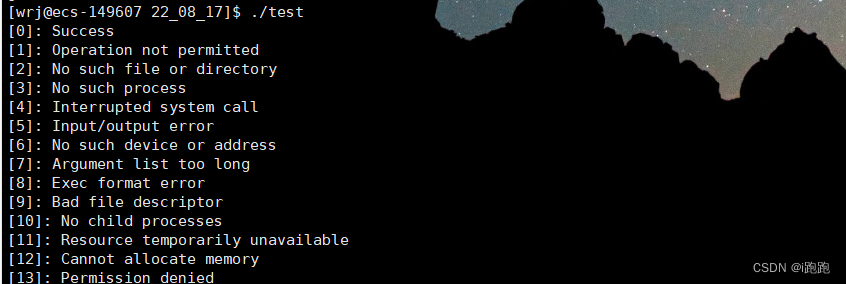
不同退出码对应的含义不是固定的,在c语言中是这一个意思,系统下可能是另外一个意思;
对于退出码,我们也可以自己定义,目前只需要了解到不同退出码含义不同即可。
进程终止的常见做法
1. 在 main 函数中 return
在 main 函数中 return 代表着进程终止,在其他函数中 return 代表着函数运行完成
2. exit()
在任意位置调用,可以引起进程的终止,括号内的数字相当于 return 后面的退出码,exit(退出码)


exit是一个函数调用,头文件是 stdlib.h ,终止进程后会刷新缓存区:


3. _exit
用法和 exit() 一样,不过 _exit是一个系统调用,头文件是 unistd.h ,exit 本质上是调用了 _exit()
进程终止后不会有刷新操作:


进程等待
为什么要进程等待?
父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
子进程退出,父进程不回收,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。且想杀也杀不掉
一个已经死去的进程;
并且父进程派给子进程的任务完成的如何,我们需要知道子进程运行完成,结果对还是不对,或者是否正常退出。
如何等待?
1. wait
调用成功,返回子进程的 pid,失败则返回-1
//头文件和类型如下
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
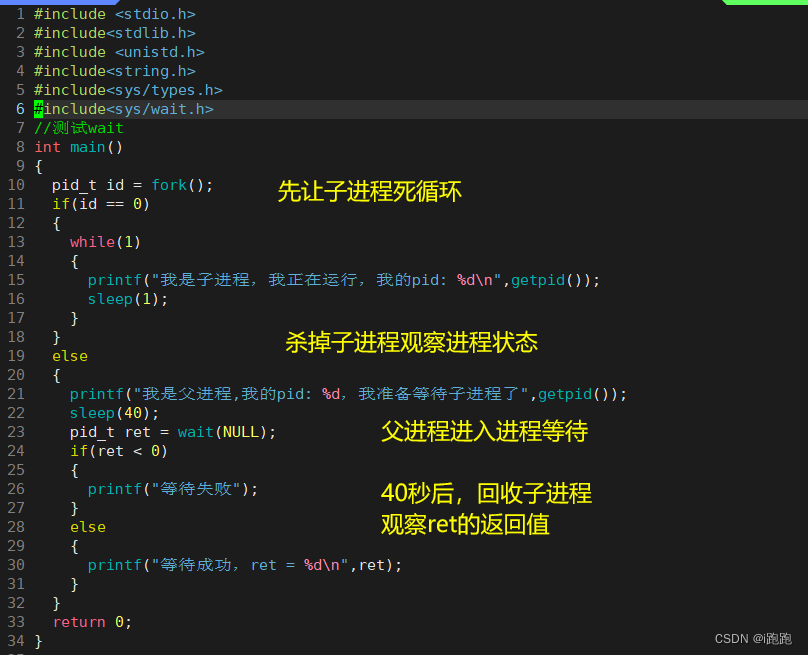
此刻父子进程都是等待状态:

接下来杀掉子进程:
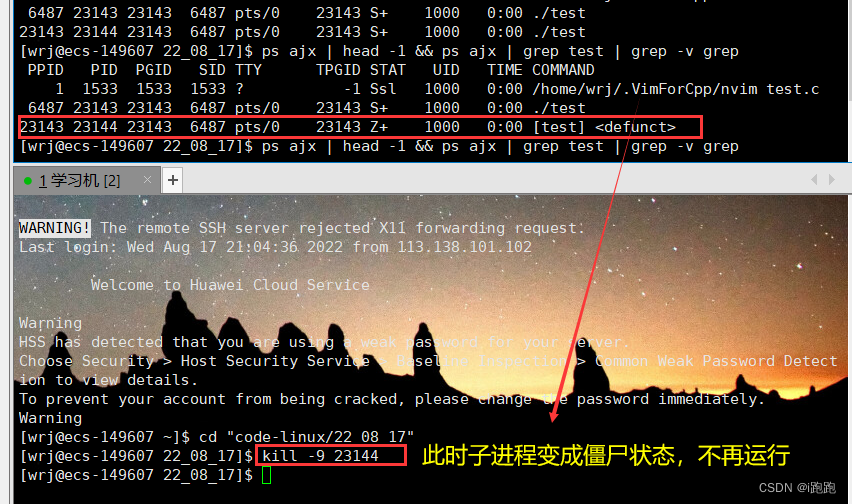
等待父进程40秒过后,读取子进程状态并回收:
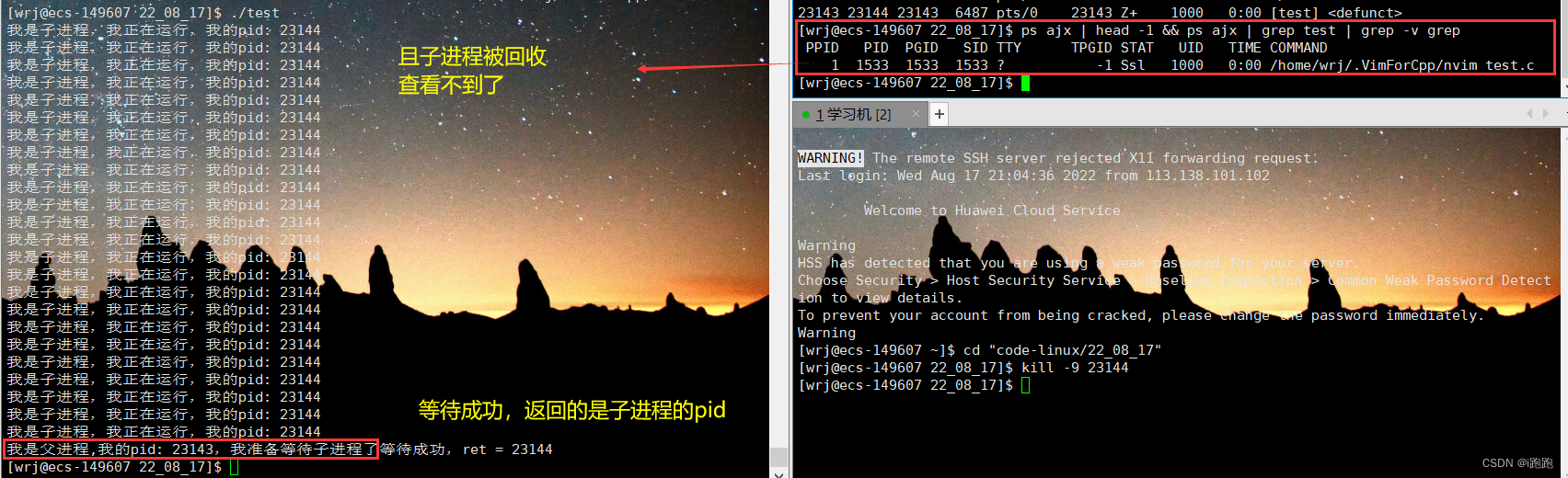
2. waitpid
pid_t waitpid(pid_t pid, int *status, int options);
如果返回值大于0,等待子进程成功,返回的是子进程pid
返回值小于0,等待子进程失败
参数中:
pid > 0 ,是几,就代表等待哪一个子进程,指定等待
pid = -1,等待任意进程
options = 0:代表着阻塞等待,等待进程结束的过程
本来父进程是 R 状态,在等待子进程退出的过程中,父进程的 task_struct 会被添加到子进程的等待队列中,父进程变为 S 状态,此时就是阻塞等待,当子进程结束后,父进程被唤醒变成 R 状态,读取子进程的退出信息,回收子进程。
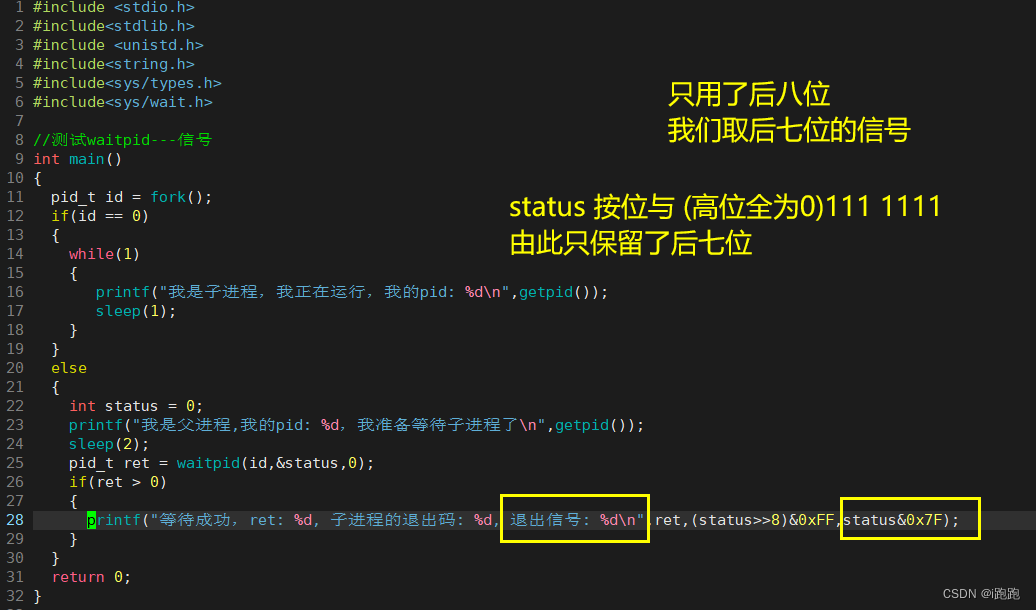
status:是一个输出型参数,通过调用此函数,从函数内部(子进程的进程控制块)拿出来的特定数据 -- 退出码和信号
status 这个参数按比特位来查看,只看整数的低16位:
当进程正常退出时:
低16位中,次8位保存的是退出码,后8位为0,验证:

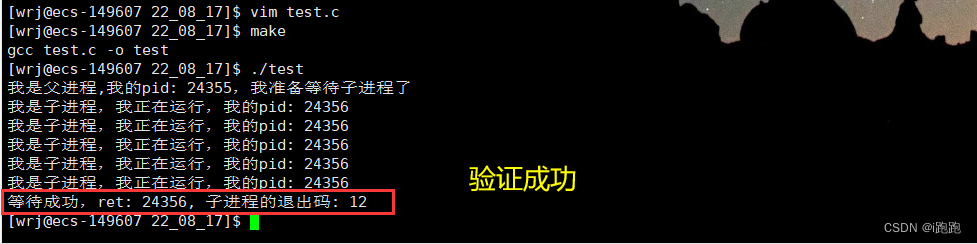
当进程异常退出时:
status 只用了后八位,其中后七位保存的是信号:

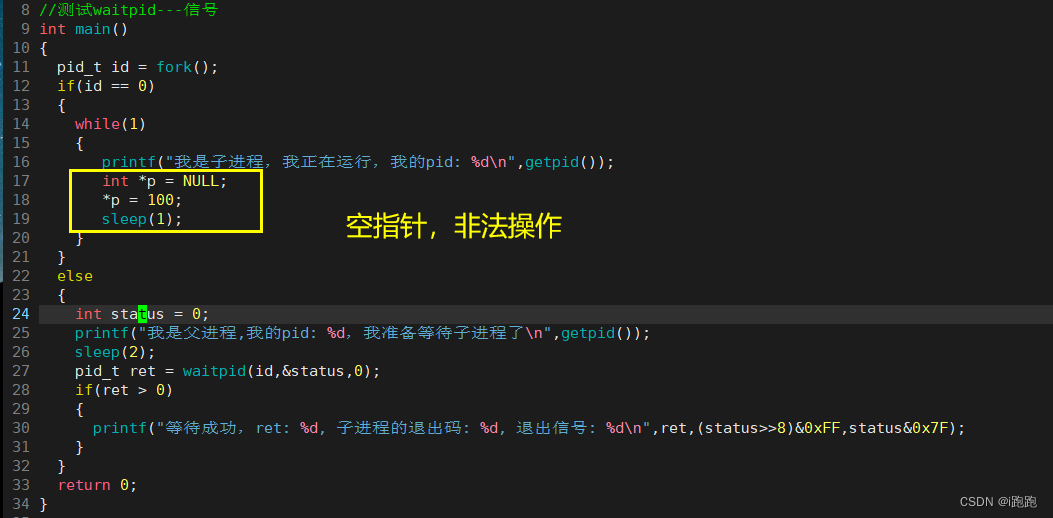
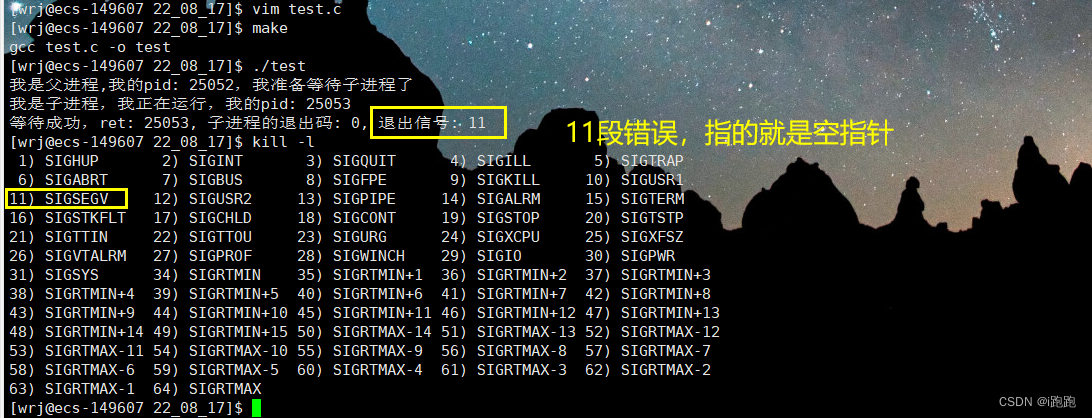
当程序内部产生异常,导致进程终止,就会返回对应的信号,以空指针为例:
宏判断是否异常--提取退出码
在Linux下,系统为我们提供了两个宏:
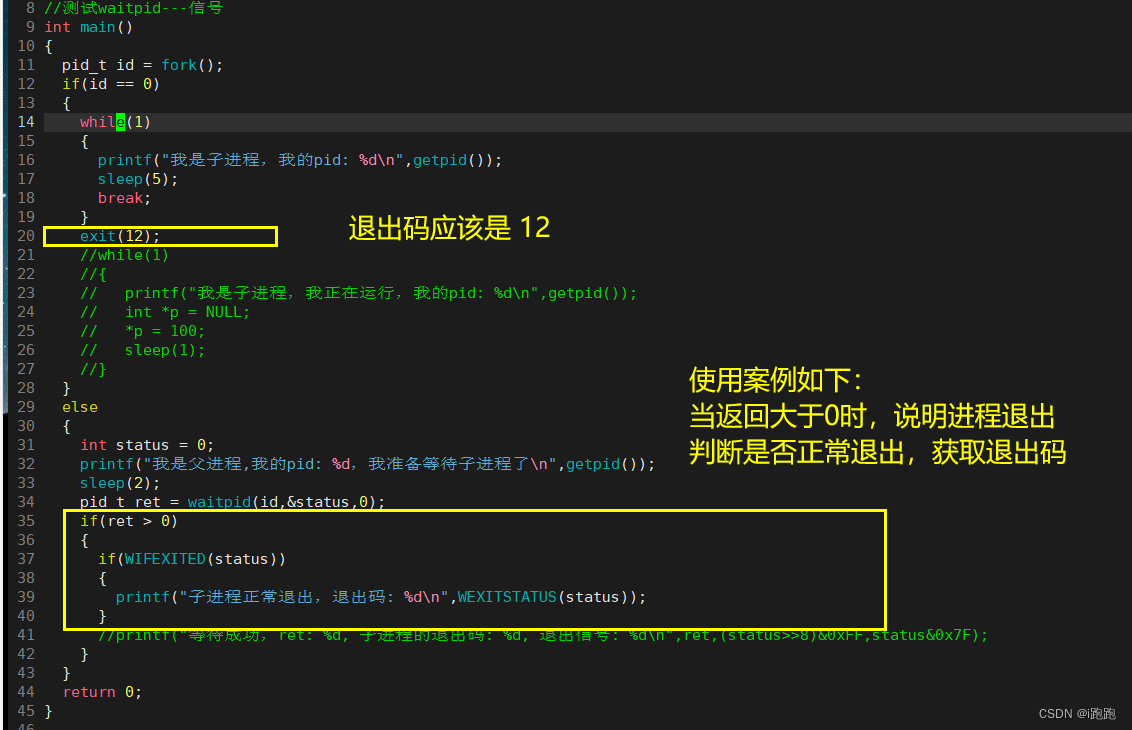
WIFEXITED(status):查看进程是否正常退出
WEXITSTATUS(status):查看进程的退出码



















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











