










🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是Docker
Docker:就像一个“打包好的App”
想象一下,你写了一个很棒的程序,在自己的电脑上运行得很好。但当你把它发给别人,可能会遇到各种问题:
-
“这个软件需要 Python 3.8,但我只有 Python 3.6!”
-
“我没有你用的那个库,安装失败了!”
-
“你的程序要跑在 Linux,我的电脑是 Windows!”
💡 Docker 的作用:它就像一个“打包好的 App”,把你的软件、依赖、环境、系统配置等 全部封装到一个“容器” 里,别人拿到这个容器,就能直接运行,而不用关心它内部的细节。
🚀 把 Docker 想象成“集装箱”
传统运输 vs. 集装箱运输
以前(传统部署):
-
货物(程序)需要不同的包装方式(运行环境)
-
货物可能损坏(环境不兼容)
-
装卸麻烦(程序迁移难)
有了 Docker(容器部署):
-
货物装进标准化集装箱(Docker 容器)
-
不管运到哪里,集装箱里东西不变(程序环境一致)
-
码头和船只可以直接装卸(轻松部署到不同系统)
Docker 让软件像“集装箱”一样标准化、可移植、易部署! 🚢

2、什么是Ollama
Ollama 是一个本地运行大语言模型(LLM)的工具,它可以让你 在自己的电脑上直接运行 AI 模型,而不需要连接云端服务器。
💡 简单来说:Ollama 让你像运行普通软件一样,轻松在本地使用 ChatGPT、Llama、Mistral、Gemma 等大语言模型。
🚀 Ollama 的核心特点
-
本地运行 🏠
-
你不需要联网,也不用担心隐私问题,所有计算都在你的电脑上完成。
-
-
支持多种开源模型 📚
-
可以运行 Llama 3、Mistral、Gemma、Code Llama 等不同的大模型。
-
-
易于安装和使用 🔧
-
只需要几条命令,就能下载并运行 AI 模型。
-
-
轻量化优化 ⚡
-
适配 Mac(Apple Silicon)、Linux 和 Windows,支持 GPU 加速,让模型运行更快。
-
-
离线推理 🔒
-
适合不想依赖 OpenAI API 或其他云端 AI 服务的用户。
-
二、准备工作
1、操作系统
这里我们使用的操作系统为Centos 7.9,配置为4核8G,大家也可以使用其他的Linux发行版本,或者使用Windows。
2、镜像准备
如果已经安装了Docker,可以提前准备好镜像,ollama/ollama,镜像比较大,拉取会耗一些时间
三、安装
1、安装Docker
1.关闭防火墙
systemctl stop firewalld && systemctl disabled firewalld2.关闭SELinux
setenforce 03.更换yum源
rm -f /etc/yum.repos.d/*
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all && yum makecache4.安装依赖项
yum install -y yum-utils device-mapper-persistent-data lvm2
5. 添加Docker源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo6.安装Docker
yum install docker-ce -y7.添加Docker镜像加速器
vim /etc/docker/daemon.json
# 添加如下内容
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://noohub.ru",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://0c105db5188026850f80c001def654a0.mirror.swr.myhuaweicloud.com",
"https://5tqw56kt.mirror.aliyuncs.com",
"https://docker.1panel.live",
"http://mirrors.ustc.edu.cn/",
"http://mirror.azure.cn/",
"https://hub.rat.dev/",
"https://docker.ckyl.me/",
"https://docker.chenby.cn",
"https://docker.hpcloud.cloud",
"https://docker.m.daocloud.io"
]
}8.启动Docker
systemctl start docker2、启动Ollama
1.启动Ollama容器
docker run -itd -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama- docker run 运行一个新的 Docker 容器
- -itd 组合多个选项:
- ✅ -i(保持标准输入)
- ✅ -t(分配终端)
- ✅ -d(后台运行容器)
- -v ollama:/root/.ollama 挂载数据卷,把 ollama 这个 Docker 数据卷 绑定到容器的 /root/.ollama 目录,确保数据持久化(如下载的模型不会丢失)。
- -p 11434:11434 端口映射,把 宿主机(本机)的 11434 端口 映射到 容器 内部的 11434 端口,这样宿主机可以通过 http://localhost:11434 访问 Ollama 服务。
- --name ollama 指定 容器名称 为 ollama,方便管理和启动。
- ollama/ollama 使用的 Docker 镜像,这里是 官方的 Ollama 镜像。
如果是使用GPU运行,则用下面的命令启动
docker run -itd --name ollama --gpus=all -v ollama:/root/.ollama -p 11434:11434 ollama/ollama2.查看Ollama容器
docker ps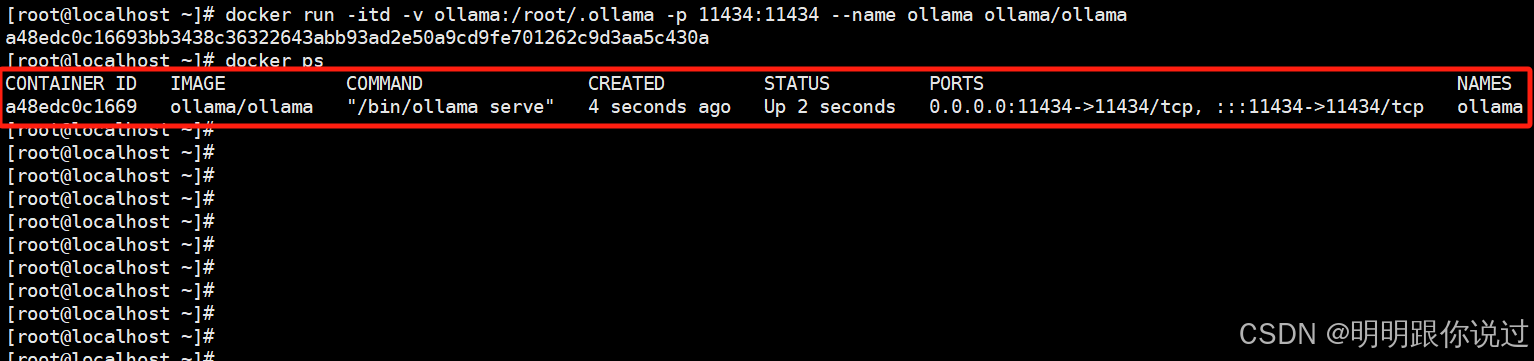
3、拉取Deepseek大模型
1.进入到容器中
docker exec -it ollama /bin/bash2.拉取模型
ollama pull deepseek-r1:7b
在官网中,有许多Deepseek的模型,这里主要是演示,所以拉取了一个较小的模型
官网地址:deepseek-r1
3.查看模型
ollama list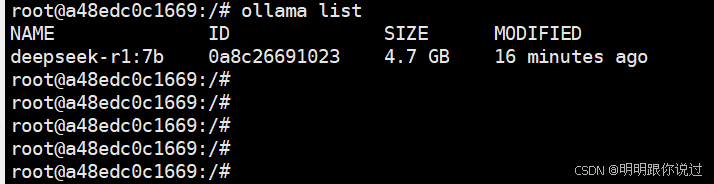
4、启动Deepseek
ollama run deepseek-r1:7b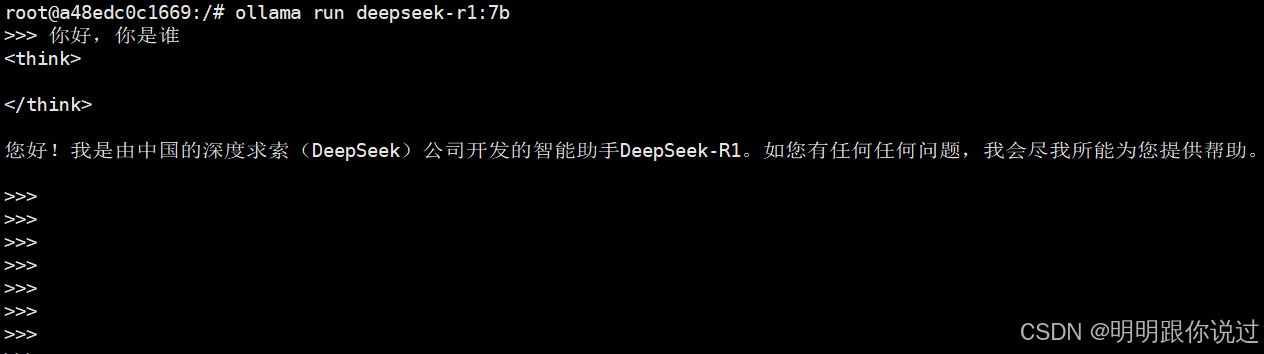
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!


















 5879
5879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











