






去重完发现答案不对,原来是查重...
既然是查重那么对应字段的记录数量一定大于1,我们先给记录统计一下:
select email,count(*)
from Person
group by email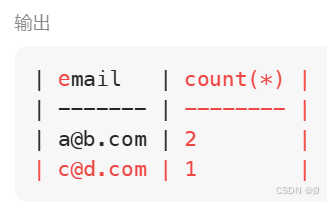
很好,现在可以看到哪个字段有重复了。接下来就是把重复的字段返回去
🤓👆诶这个我会,加限制条件count(*)>1不就行了?
select email,count(*)
from Person
group by email
where count(*) > 1
诶卧槽怎么不对🤔一定是顺序问题
select email,count(*)
from Person
where count(*) > 1
group by email
确实是顺序问题,不过不是代码的顺序,而是MySQL的运行顺序。这里贴一个写的比较清楚的文章: 面试官:MySQL中SQL的执行顺序是怎样的?_mysql的sql执行顺序-优快云博客
可以看到where的运行顺序在group by之前,而我们需要再group by之后添加条件,那么这里用到的是having子句。直接复制菜鸟的定义:
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
直接上代码:
# Write your MySQL query statement below
select email
from Person
group by email
having count(*) > 1count()我们移动到下面用,不然返回的答案也是带有计数的


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









