






写在前面:机器学习专栏为本人初步学习机器学习与人工智能课程的笔记总结与实践汇总,大部分内容是自己在学习完相应课程后对黄海广机器学习笔记的再总结
什么是机器学习
机器学习是人工智能的一个子领域,它使计算机能够通过经验来学习和改进。具体来说,机器学习涉及到开发算法和统计模型,这些模型能够从数据中学习并做出预测或决策,而不需要明确的编程指令。在学习机器学习我们在计算机中编写了一个程序,让它可以从经验中获取知识,我们叫它“学习者”,就像婴儿通过观察和尝试来学习识别不同的物体一样,“学习者”也可以通过观察数据来学习识别模式。以识别猫咪的简单案例来分析:
- 数据收集:
假设我们给“学习者”展示很多图片,其中一些是猫咪的图片,一些不是。这些图片就是“学习者”学习的基础。 - 学习过程:
“学习者”开始观察这些图片,尝试找出猫咪图片的共同特征。这可能包括猫咪的耳朵、眼睛、胡须等。这个过程不需要我们告诉“学习者”具体要寻找什么,它自己会尝试找出规律。 - 模式识别:
随着“学习者”看越来越多的图片,它开始能够识别出哪些特征是猫咪独有的。这个过程就像是它在大脑中构建了一个“猫咪模板”。 - 预测和分类:
一旦“学习者”认为自己已经学会了如何识别猫咪,我们就可以给它一些新的图片,让它尝试告诉我们这些图片中是否有猫咪。这就是“预测”。 - 反馈和改进:
如果“学习者”识别错误了,我们会告诉它哪里错了,然后它就可以根据这个反馈来调整自己的“猫咪模板”,以便下次做得更好。 - 自动化和应用:
经过足够的学习和调整,“学习者”变得非常擅长识别猫咪。现在,我们可以让它自动处理大量图片,快速地告诉我们哪些是猫咪。
机器学习:就像是一个不断学习和进步的过程,它通过观察和实践来提高自己的技能。
算法:可以想象成是“学习者”的大脑,里面装满了帮助它学习和做决策的规则和公式,这个就是我们开发者做的工作,将学习算法编写成程序让计算机执行。
模型:是“学习者”通过学习数据后形成的一种内部表示,它帮助“学习者”理解和预测世界。
训练:就像教育一样,是“学习者”通过数据学习的过程。
特征:是“学习者”用来识别和区分不同事物的关键属性或标志。
机器学习中有许多不同类型的学习算法。主要的两种类型被我们称之为监督学习和无监督学习。监督学习是指我们将教会计算机去如何完成任务,而在无监督学习中,我们打算让它自己进行学习。
机器学习的应用非常广泛,包括图像识别、语音识别、推荐系统、自然语言处理、医疗诊断、股票市场分析等。
监督学习 Supervised Learning
以上述的猫咪识别的例子就是一个典型的监督学习案例。再猫咪识别的案例中,我们给出了许多猫咪的图片并告诉这些图片就是猫,然后运用学习算法,来辨别没有见过的新猫咪图片。这个其实是一个分类问题。
下面继续介绍监督学习的另一个案例:预测房价
在这个简单的案例中,我们只使用房屋面积作为预测房价的特征,当然实际上影响房价的因素并不只有大小,跟其他的因素例如房子地段,楼层高度,周围配套等都有关系。
下面是一个表格记录了房屋交易价格与其对应的房屋面积
| 房屋面积(x) | 成交价格(y) |
|---|---|
| 2104 | 460 |
| 1416 | 232 |
| 1536 | 315 |
| 852 | 178 |
| … | … |
下面定义机器学习中的变量:
-
m - 训练样本数量,在预测房价中指我们上面表格的行数m
-
x ( s ) x^{(s)} x(s) - 输入变量,或者叫做特征,在例子中指的就是房屋面积
-
y ( s ) y^{(s)} y(s) - 输出变量,或者叫做目标变量,是预测的对象或者叫做推理的目标,在例子中指的就是房屋价格
-
( x , y ) (x,y) (x,y) - 一个训练样本
-
( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)) - 第i个训练样本
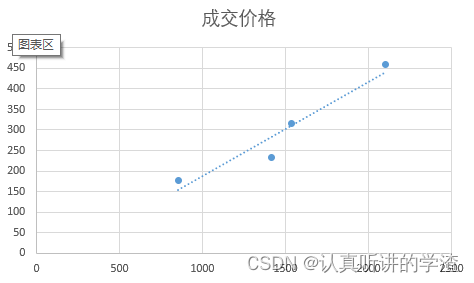
使用学习算法,我们可以在这组数据中画出一条直线,根据这条直线我们可以推断出房屋价格。
可以看出监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。在房价预测的案例中我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。用术语来讲,这叫做回归问题。
无监督学习 Unsupervised Learning
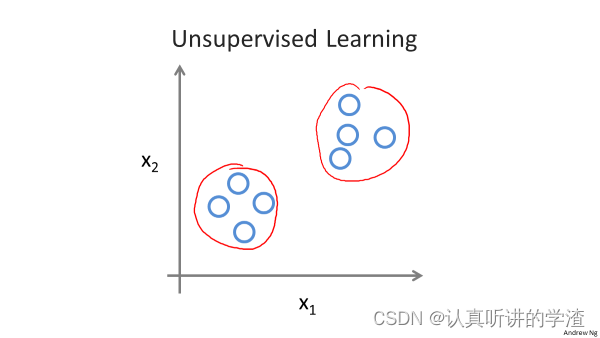

上图来自吴恩达老师视频课PPT
无监督学习和监督学习最大的区别就是数据集中的每条数据都没有标签,我们只知道数据,却不知道如何处理,也不知道么个数据点是什么。针对这种无标签的情况,无监督学习就是能够判断出数据有两个不同的聚集簇。无监督学习算法可能将这些数据分为两个不同的簇,所以叫聚类算法。
例如在语音分离的案例中,我们可以使用无监督学习的算法来完成这个任务对这个案例感兴趣可以参考[论文解读-Unsupervised Audio Source Separation using Generative Priors]

















 3035
3035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









