






一、Evox
https://evox.readthedocs.io/zh/latest/guide/install/install.htmlEvox是一个进化算法加速框架库,基于jax库开发。同类型的还有Evotorch,基于pytorch开发。
依照官网安装教程进行安装最后会需要CUDA12.5版本的驱动,但是服务器或者集群上的CUDA版本往往在11.7、12.0甚至更低。以下以CUDA11.7版本为例。
二、Jax
考虑到Evox库主要依赖jax库,只要安装在CUDA11x版本jax库即可适配Evox。因此进入Jax官网查看安装教程。
https://jax.readthedocs.io/en/latest/installation.html官网的安装教程还是有些晦涩难懂的,对于Linux服务器上的用户而言(默认安装了CUDA驱动)安装Jax的pip指令如下:
pip install -U "jax[cuda12]"如果是安装cuda11版本的,只要将[cuda12]修改为[cuda11]即可。
安装完进入python界面import evox时会发现报错如下:
An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.报错是因为Jax官方移除了自动下载CUDA-enabled版本的Jaxlib库,通过上面的pip命令下载的是CPU版本的Jaxlib。如果要下载CUDA-enabled版本的Jaxlib库,需要先在Jax包发布网站上找到指定版本的Jaxlib。网站如下:
https://storage.googleapis.com/jax-releases/通过Ctrl+F快速搜索cp39版本下的cu11-jaxlib包。本次安装需要的包如下:

把<Key>后面的轮子地址和网站拼起来就可以下载了。
https://storage.googleapis.com/jax-releases/cuda11/jaxlib-0.4.14+cuda11.cudnn86-cp39-cp39-manylinux2014_x86_64.whl下载了轮子以后在环境中pip安装,安装完会发现提示如下:
jax 0.4.30 requires jaxlib<=0.4.30,>=0.4.27, but you have jaxlib 0.4.14+cuda11.cudnn86 which is incompatible.降低Jax版本到0.4.16即可(为什么事0.4.16,试出来的,也可以别的版本,版本太低evox其他的依赖会报错)。
继续测试会发现提示Scipy和Numpy版本太高,部分提示如下:
AttributeError: `np.float_` was removed in the NumPy 2.0 release. Use `np.float64` instead.重新安装低版本,Scipy==0.10.1,Numpy==1.26.4
对于nvidia的一些必要库,建议直接安装去Pytorch官网安装CUDA118版本的Pytorch,同时也会安装好相关依赖,如果懒得去官网可以输入如下指令:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2此时import evox就不会报错了。
三、其他问题
1. 内存不足(可能)
按照一、二走完也可能会报错如下:
jaxlib.xla_extension.XlaRuntimeError: FAILED_PRECONDITION: DNN library initialization failed. Look at the errors above for more details.这是服务器的GPU内存已经占满了,可以输入nvidia-smi静态查看占用情况,也可以输入watch nvidia-smi动态查看(这个比较靠谱,可以判断是否为空占卡)。
Evox采用了GPU并行加速计算,但是这个库不能指定在某张卡上运行,如果服务器有N张卡,那么Evox就会在N张卡上并行,因此如果有一张卡满了,就有可能产生如上报错。
2. Ptxas未安装
将服务器上的evox环境进行docker打包以后,上传至集群中。运行集群容器,import evox时发生如下报错:
jaxlib.xla_extension.XlaRuntimeError: FAILED_PRECONDITION: Couldn't get ptxas/nvlink version string: INTERNAL: Couldn't invoke ptxas --version参考其他博客[1],原因是因为在进行docker打包时,只转移了环境,即pip安装包,但是未转移服务器miniconda上属于nvidia的相关依赖。输入指令可以查看是否安装Ptxas:
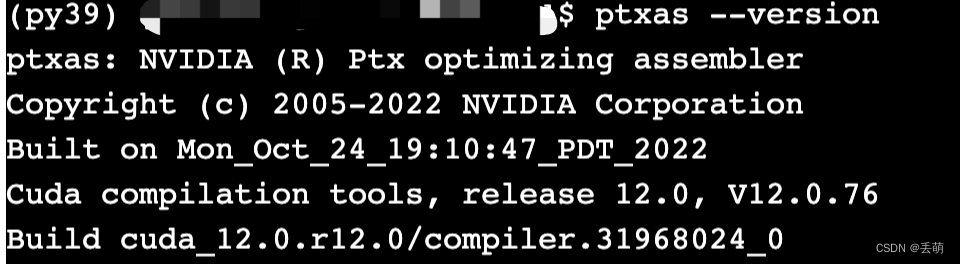
ptxas --version通过输入如下指令安装相关依赖(如果准备docker打包,那就直接在容器中安装,安装完再导出为镜像):
conda install -c nvidia cuda-nvcc如果未安装,则输出如下,例如docker容器中:

如果已安装,则输出如下,例如我在服务器的环境以及install环境以后得docker容器中:
3. Cuda Toolkit版本不对
在集群中运行evox发现报错如下,github问题区上的解释是ptxas版本太高,不适配CUDA驱动:
Execution of replica 0 failed: INTERNAL: Failed to load in-memory CUBIN (compiled for a different GPU?).: CUDA_ERROR_INVALID_IMAGE: device kernel image is invalid在服务器的docker容器中,输入nvcc --version发现nvcc的版本是12.5,即该版本是为CUDA驱动版本为12.5服务的。为了降低nvcc版本和ptxas版本(ptxas --version版本也是12.5,毕竟都是一个Tookit包的),参考nvidia CUDA安装手册的2.4.4节:
https://docs.nvidia.com/cuda/archive/11.7.0/pdf/CUDA_Installation_Guide_Windows.pdf其中安装命令如下:
conda install cuda -c nvidia/label/cuda-11.3.0考虑到我准备上传的集群的CUDA版本为11.7,这里直接将尾缀改为cuda-11.7.0进行安装。
注意:请直接在容器中进行conda install,在服务器中迁移环境到容器中仅仅只复制了环境文件,不包含miniconda其他的配置文件,方便起见请直接在容器中进行安装。
注意:请先使用conda uninstall cuda-nvcc卸载nvcc,因为conda不会进行覆盖安装,nvcc会依旧保持在12.5版本。
四、参考
[1] https://blog.youkuaiyun.com/keeppractice/article/details/132032867
















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









