






 本文介绍了如何使用file-read-backwards库实现按时间顺序读取不断增长的日志文件,提高查找特定IP在指定时间段内的效率,尤其适用于大文件场景。
本文介绍了如何使用file-read-backwards库实现按时间顺序读取不断增长的日志文件,提高查找特定IP在指定时间段内的效率,尤其适用于大文件场景。
前些日子有位信息安全的hxd说了一个简单的需求,但我之前没有写过文件倒读,记录一下。
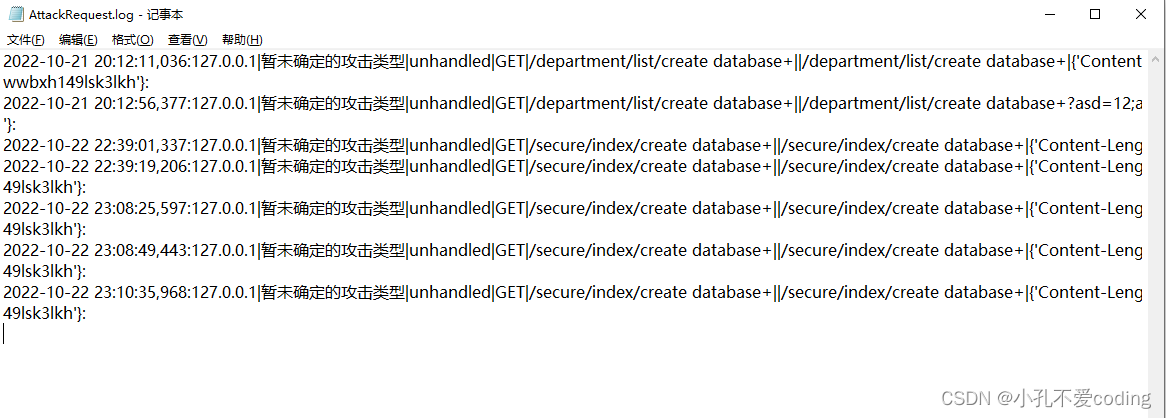
这是一个.log日志文件,会不断往里写新的内容,但每次读取要读取最新的内容,若每次都从开头读,当日志文件非常庞大的时候会一定程度上影响执行效率,那么最好得从下往上读。
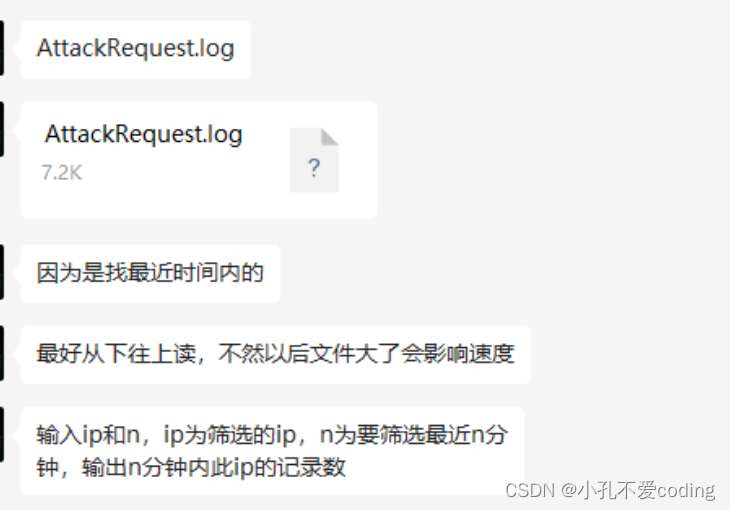
实现起来比较简单,主要是用了一个之前没用过的库——file_read_backwards,直接pip install file-read-backwards即可
# pip install file-read-backwards文档倒读的库
from file_read_backwards import FileReadBackwards
import time
from interval import Interval
import datetime
def get_log(min, ip): # 传入的参数为时间间隔和查找的ip
end = datetime.datetime.now() # 获取当前时间
start = end - datetime.timedelta(minutes = min) # 当前时间-min的时间
time_interval = Interval(start, end) # 构成一个min的时间区间
log_list = [] # 存储符合条件的列表
with FileReadBackwards("AttackRequest.log") as f: # 采用FileReadBackwards读取log文件(非常规)
for line in f:
# 倒序逐个判断,若不符合条件就退出循环,不必判断log中的所有字段
# 判断是否在min内
if datetime.datetime.strptime(line[:19], '%Y-%m-%d %H:%M:%S') in time_interval :
# 判断是否是该ip地址
if line[24:33] == ip:
# 若是,放入log_list
log_list.append(line)
else: # 若不是,continue进行下一次判断
continue
pass # pass无实际意义,只是为了换行对齐
else: # 若不是在时间区间,直接跳出循环,因为是倒序读取
break
return log_list
我的邮箱:k1933211129@163.com,优快云私信很少看,欢迎各位大佬不吝赐教~

















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









