






 本文详细解读了层次查询的执行过程,包括STARTWITH子句的用法、CONNECTBY条件的应用、ORDERBY SIBLINGSBY子句及层级数据集示例。理解层级查询对于处理组织结构或树形数据至关重要。
本文详细解读了层次查询的执行过程,包括STARTWITH子句的用法、CONNECTBY条件的应用、ORDERBY SIBLINGSBY子句及层级数据集示例。理解层级查询对于处理组织结构或树形数据至关重要。
层级查询概述
按下列次序处理包括层级子句的 SELECT 语句的子句:
1.FROM 子句(仅对于当前数据库中的单个表对象)
2.Hierarchical 子句
3.WHERE 子句(无连接断言)
4.GROUP BY 子句
5.HAVING 子句
6.Projection 子句
7.ORDER BY 子句
ORDER BY 子句的 ORDER BY SIBLING 选项可对同一父母的孩子行的集合进行排序。
包括层级子句的子查询按部分的顺序返回中间结果集,在此,特定层级的迭代(n+1)中产生的行紧跟在产生它们的迭代(n)中的行之后。然而,ORDER BY 子句、GROUP BY 或 HAVING 子句,或在 Projection 子句中指定的 DISTINCT 或 UNIQUE 关键字会销毁那部分的顺序。
层级子句跟在 SELECT 语句子句的词汇序列中的 WHERE 子句之后,但在该层级子句的结果上处理 WHERE 子句断言。如果 SELECT 语句包括层级子句,则 WHERE 子句不可指定连接子句,但在 FROM 子句中指定的表对象可作为连接一个或多个表的查询的结果集。
任何包括层级查询子句的 SELECT 语句都称为层级查询,在 FROM 子句指定的表上执行查询的递归序列:
1.可选的 START WITH 子句可指定条件。返回任何满足此条件的行作为该层级查询的第一个中间结果集。
2.下一步骤将在 CONNECT BY 子句中指定的条件应用到表。返回任何满足那个条件的行作为第二个中间结果集。
3.下一步骤将 CONNECT BY 条件应用到表。返回的任何行构成第三个中间结果集。
4.CONNECT BY 子句递归地运行查询来产生连续的中间结果集,直到迭代产生空结果集为止。
5.然后,层级 SELECT 语句组合前面的递归步骤的所有中间结果集,产生该层级子句的最终结果集。
6.然后,将 WHERE 子句的断言应用到该层级子句检索了的这个行集合,然后按罗列的顺序应用 SELECT 语句的剩余的子句。
在 START WITH 和 CONNECT BY 子句返回所有中间的结果集之后,您可使用 ORDER SIBLINGS BY 子句来对该层级之内的每个级别的有相同的父母的兄弟行进行排序。要获取更多信息,请参阅 ORDER SIBLINGS BY 子句。
您可使用来自 SET EXPLAIN 语句的输出来查看层级查询的执行路径。
层级子句提供一种有效的替代机制,使用节点数据库扩展来从层级数据集检索信息
层级数据集的示例
在接下来的几个主题中,那些展示层级查询的 SQL 代码示例是基于下列 employee 表中的层级数据,其行包含关于在组织的层级之内的员工的信息。mgrid 列展示员工向其汇报的管理者的员工标识符(empid):
CREATE TABLE employee(
empid INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(10),
salary DECIMAL(9, 2),
mgrid INTEGER
);
employee 表中 17 行的数据值如下。
INSERT INTO employee VALUES ( 1, ‘Jones’, 30000, 10);
INSERT INTO employee VALUES ( 2, ‘Hall’, 35000, 10);
INSERT INTO employee VALUES ( 3, ‘Kim’, 40000, 10);
INSERT INTO employee VALUES ( 4, ‘Lindsay’, 38000, 10);
INSERT INTO employee VALUES ( 5, ‘McKeough’, 42000, 11);
INSERT INTO employee VALUES ( 6, ‘Barnes’, 41000, 11);
INSERT INTO employee VALUES ( 7, ‘O’‘Neil’, 36000, 12);
INSERT INTO employee VALUES ( 8, ‘Smith’, 34000, 12);
INSERT INTO employee VALUES ( 9, ‘Shoeman’, 33000, 12);
INSERT INTO employee VALUES (10, ‘Monroe’, 50000, 15);
INSERT INTO employee VALUES (11, ‘Zander’, 52000, 16);
INSERT INTO employee VALUES (12, ‘Henry’, 51000, 16);
INSERT INTO employee VALUES (13, ‘Aaron’, 54000, 15);
INSERT INTO employee VALUES (14, ‘Scott’, 53000, 16);
INSERT INTO employee VALUES (15, ‘Mills’, 70000, 17);
INSERT INTO employee VALUES (16, ‘Goyal’, 80000, 17);
INSERT INTO employee VALUES (17, ‘Urbassek’, 95000, NULL);
每一 empid 与 mgrid 值对表达引用的关系,带有适当的 CONNECT BY 条件的查询的递归迭代可正确地组装成层级。
在此,最后一行中 mgrid 列中的 NULL 值展示其 empid 值为 17 的员工 Urbassek 是此报告层级的根节点。
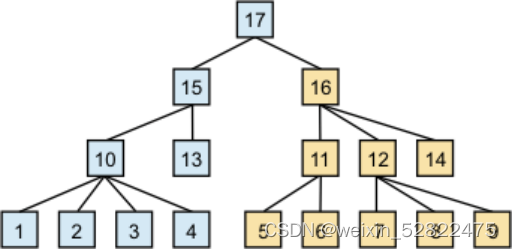
下图展示 employee 表数据的报告层级(以展示 empid 值的节点)的四个级别:
图: 在报告层级中的元素的关系
START WITH 子句
可选的 START WITH 子句指定条件。满足此条件的行成为层级查询中开启 CONNECT BY 子句的递归操作的根。
START WITH 子句是对 SQL 的 ANSI/ISO 标准的扩展。
语法

用法
START WITH 子句指定 CONNECT BY 子句为其递归活动的第一迭代使用的搜索条件。如果您省略 START WITH 子句,则 CONNECT BY 子句对于中间结果的初始集将每行都作为层级的根处理。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









