



第一部分:什么是YOLO的网络结构
这是YOLO11的网络的架构图,整体可分为 Backbone(骨干网络)、Neck(颈部网络) 和 Head(检测头) 三部分,初学者可跳过先从搞懂网络结构开始,最后再回到这里,下面逐步讲解:
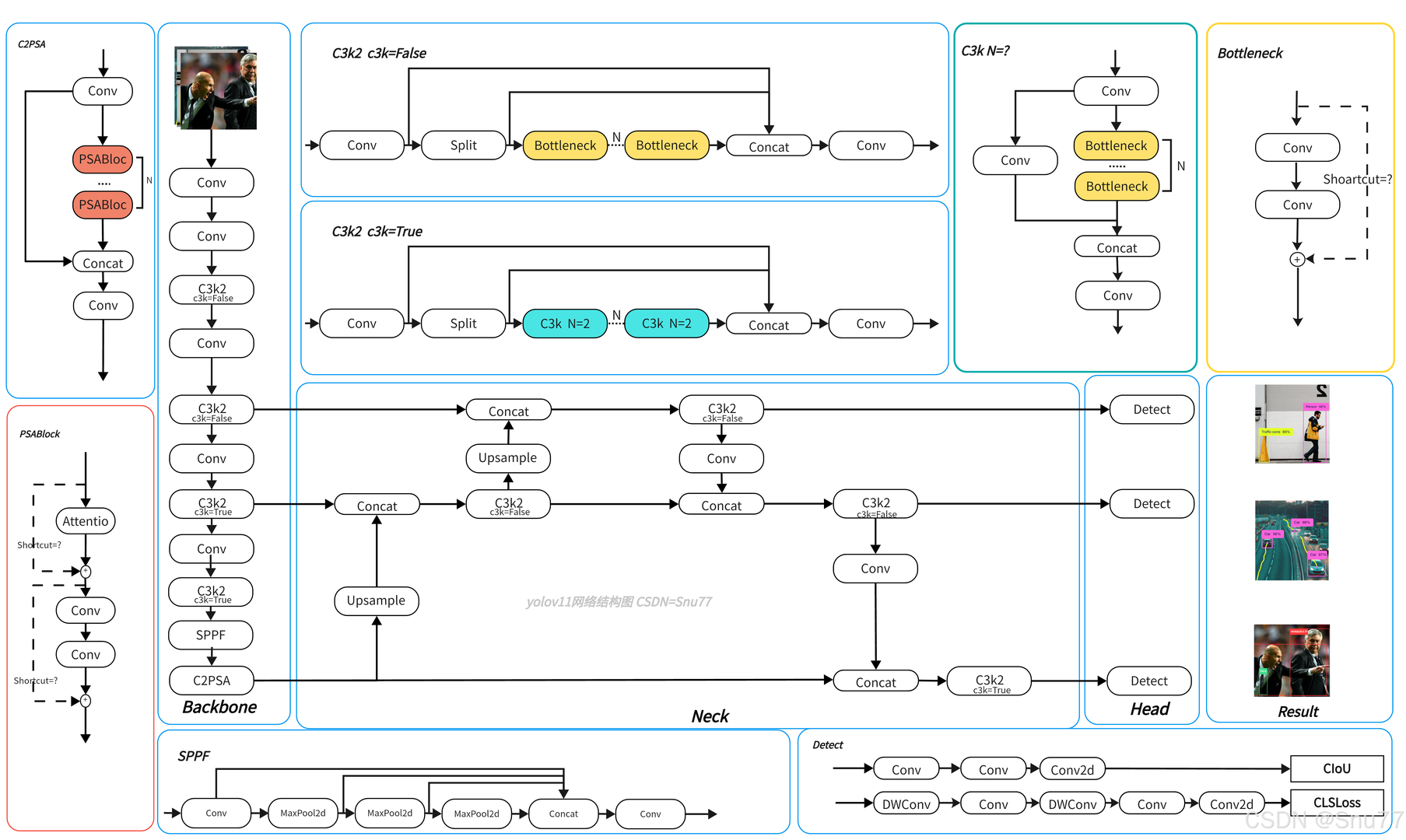
1. Backbone(骨干网络)
负责从输入图像中提取基础特征,是整个网络的 “特征提取器”。
- 卷积(Conv)操作:通过多个卷积层逐步提取图像的浅层到深层特征,比如边缘、纹理、形状等信息。
- C3k2 模块:是网络的核心组件之一,有
c3k=False和c3k=True两种模式。它通过 “分割(Split)- 瓶颈(Bottleneck)/ 子 C3k 模块 - 拼接(Concat)” 的流程,对特征进行更精细的处理,既减少计算量,又能保持特征的表达能力。 - SPPF 模块:通过多次最大池化(MaxPool2d)和拼接(Concat),增大感受野,能更好地捕捉图像中远距离的特征依赖关系,同时减少计算复杂度。
- C2PSA 模块:结合了 PSA(可能是某种注意力机制),通过注意力机制强化对关键特征的关注,提升特征提取的针对性。
2. Neck(颈部网络)
对 Backbone 提取的特征进行融合和增强,为 Head 提供更有效的特征表示。
- 上采样(Upsample)与拼接(Concat):将不同尺度的特征图进行上采样后拼接,实现多尺度特征融合。这样能结合浅层的细节特征(如小目标的边缘)和深层的语义特征(如目标的类别信息),让网络对不同大小的目标都有较好的检测能力。
- C3k2 模块再次作用:在 Neck 中继续使用 C3k2 模块,进一步细化和融合特征,确保特征在传递到 Head 前足够丰富和准确。
3. Head(检测头)
基于 Neck 输出的特征,完成目标的 “分类” 和 “边界框回归” 任务。
- 卷积与深度卷积(DWConv):通过这些操作提取最终用于检测的特征。
- 损失计算:
- CIoU:是一种边界框回归的损失函数,考虑了边界框的重叠度、中心点距离和长宽比,能更精准地优化边界框位置。
- CLSLoss:是分类损失函数,用于优化目标类别的预测精度。
整体流程
输入图像先经过 Backbone 提取多尺度特征,再由 Neck 对这些特征进行融合与增强,最后 Head 基于融合后的特征,预测目标的类别和边界框位置,输出检测结果(如右侧展示的不同场景下的目标检测示例)。这种架构是目标检测领域常见的 “骨干 - 颈部 - 检测头” 范式,平衡了检测精度与计算效率。
要理解 YOLO11 的网络结构,我们可以把它拆成 **“特征提取→特征融合→结果输出”** 三个核心环节,像搭积木一样一步步搞清楚每个部分的作用。
一、先搞懂 “网络结构” 是什么
你可以把深度学习网络想象成一条 **“流水线”**:
- 输入是 “原材料”(比如鸡蛋的图片);
- 中间的 “工序” 就是网络结构的各个模块(负责提取特征、融合信息);
- 输出是 “成品”(比如鸡蛋的位置、类别)。“网络结构” 就是这条流水线的模块组成、连接方式和每个模块的功能。
二、YOLO11 网络结构拆解(以 YOLO11n 为例,轻量化版本)
YOLO11 的结构分为 ** 骨干网络(Backbone)、颈部(Neck)、检测头(Head)** 三部分,我们逐个说:
1. 骨干网络(Backbone):给图片 “提炼特征”
骨干网络的作用是从原始图片中提取不同层次的特征(比如鸡蛋的形状、颜色、纹理,或者裂纹的边缘)。YOLO11 的骨干网络是一套 “轻量化 + 注意力增强” 的组合:
-
核心模块 1:C3k2 模块这是 YOLO 系列的经典 “特征提取单元”,把复杂的卷积计算拆分成小模块,在减少计算量的同时,保证特征提取能力。可以理解为 “高效的特征提炼车间”。
-
核心模块 2:SPPF(快速空间金字塔池化)它会对特征图做 “多尺度池化”(比如同时用大、中、小窗口提取特征),让网络能同时关注 “局部细节”(如裂纹)和 “全局结构”(如整个鸡蛋的形状)。
-
核心模块 3:C2PSA(带注意力的模块)注意力就像 “智能过滤器”,给重要的特征(比如裂纹的边缘)加权,让网络更关注关键信息,提升检测精度。
2. 颈部(Neck):把特征 “混在一起优化”
颈部的作用是融合不同层次的特征(比如浅层的 “细节特征” 和深层的 “语义特征”),让网络既能看清小目标(如细微裂纹),又能识别大目标(如整颗鸡蛋)。YOLO11 用的是PANet 结构:
-
上采样 + 下采样:把深层的 “语义特征图” 放大(上采样),和浅层的 “细节特征图” 拼接;再把浅层的特征图缩小(下采样),和深层的特征图拼接。相当于 “把远、近景的信息融合成一张更清晰的图”。
-
多尺度融合:最终输出三个不同尺度的特征图(对应 “小目标、中目标、大目标”),确保不同大小的鸡蛋和缺陷都能被覆盖。
3. 检测头(Head):输出 “最终检测结果”
检测头的作用是基于融合后的特征,直接输出目标的 “位置、类别、置信度”(比如 “这是一颗有裂纹的鸡蛋,在图片的左上角,可信度 90%”)。
- 它会对三个尺度的特征图分别做预测,每个特征点都会生成多个 “锚框”(可以理解为 “候选框”),然后通过非极大值抑制(NMS) 筛选出最准确的框,最终输出检测结果。
三、YOLO11 设计这些结构是为了啥?
总结一下,整个网络的设计逻辑是 **“高效提取特征→融合多尺度信息→精准输出结果”**,最终实现:
- 速度快:轻量化的骨干网络和模块设计,让它能在普通设备上 “实时检测”(比如工业流水线中每秒处理几十张鸡蛋图片)。
- 精度高:通过注意力、多尺度融合,对小目标(如细微裂纹)和复杂场景(如光照不均的车间)有很强的适应能力。
- 易部署:参数量少、计算量低,可以在嵌入式设备(如工业检测的边缘计算盒)上运行,适合实际工业场景。
四、初学者怎么改进 YOLO11?
如果你要适配其他目标检测任务(比如检测水果瑕疵、零件缺陷),可以从这几个方向入手:
- 改骨干网络:如果你的目标更小(如草莓的霉斑),可以给骨干网络加入更多 “细节提取模块”;如果目标更大(如汽车),可以简化骨干网络提升速度。
- 改颈部融合方式:如果你的任务对 “小目标” 要求极高,可以强化浅层特征的融合比例。
- 改检测头输出:如果需要额外输出 “分割结果”(如把裂纹的形状画出来),可以给检测头加一个 “分割分支”。
第二部分:如何改进YOLO的网络结构
想要改进YOLO的网络结构可从一个例子开始,要让 YOLO11 在鸡蛋检测任务中更快、更优,可从输入预处理、骨干网络轻量化、颈部简化、检测头适配四个维度修改网络结构,以下是具体方案:
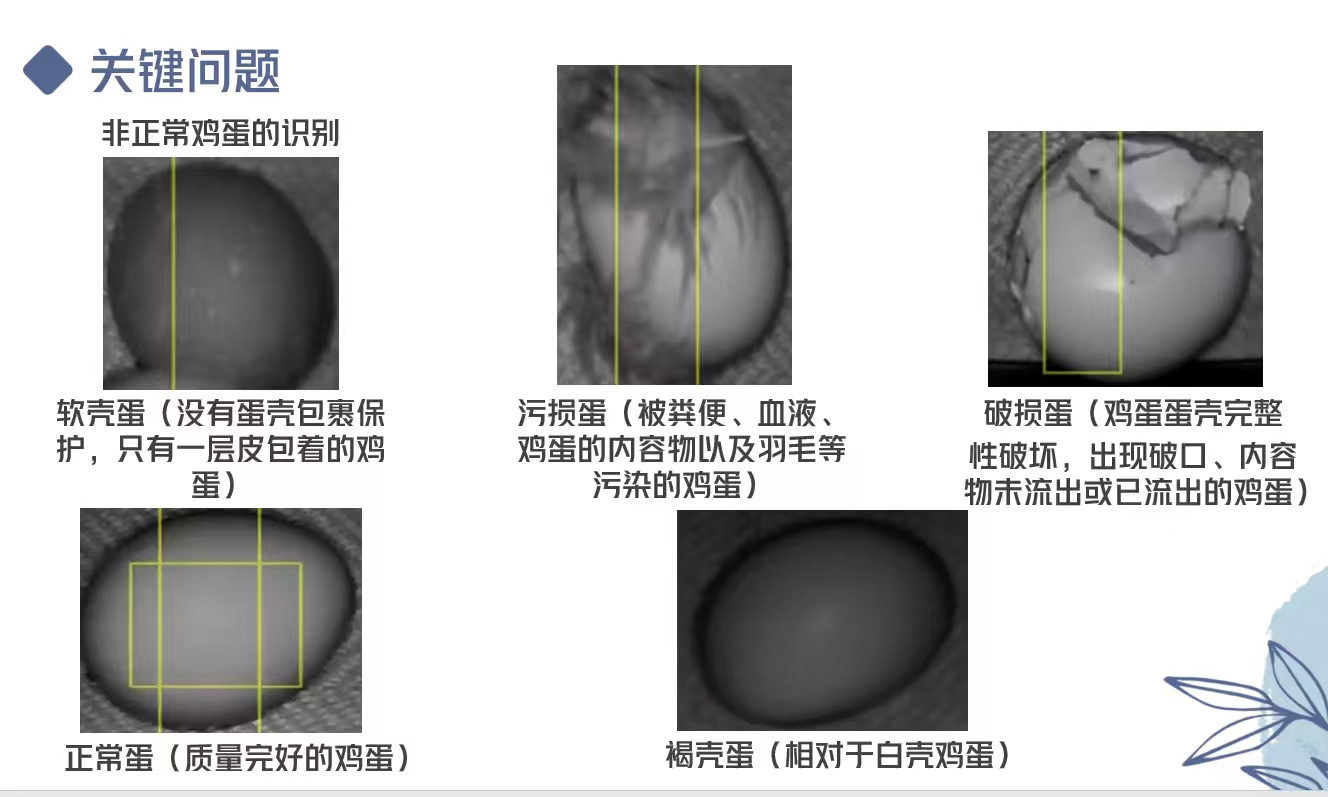
一、输入预处理:降低计算负担
灰度图仅含单通道(无需处理 RGB 三通道),可在数据加载阶段直接转为单通道输入,减少网络的通道计算量。同时,可适当缩小输入图像尺寸(如从 640×640 降至 416×416),进一步降低每一层的特征图运算量。
二、骨干网络:极致轻量化
针对鸡蛋检测的 “小目标(裂纹、污损)+ 类别区分度高(灰度特征差异明显)” 特点,对骨干网络做如下修改:
- 替换 C3k2 为更轻量的模块:将部分 C3k2 模块替换为MobileNetV3 的深度可分离卷积模块,或直接使用Ghost 卷积(用少量计算生成 “ghost 特征图”,大幅减少参数量)。
- 减少骨干网络深度:去掉骨干网络中部分冗余的卷积层(如可将原 8 层特征提取层缩减为 6 层),保留对鸡蛋灰度特征(纹理、形状)敏感的层即可。
- 简化注意力模块:若鸡蛋灰度图的特征区分度已足够,可去掉 C2PSA 注意力模块,进一步降低计算耗时。
三、颈部:简化多尺度融合
鸡蛋检测中 “小目标(如裂纹)” 依赖浅层特征,“类别区分” 依赖中层特征,可对颈部做如下简化:
- 减少融合尺度:去掉对大目标敏感的 P5/32 特征层,仅保留P3/8(小目标)和 P4/16(中目标) 两个尺度的特征融合,降低颈部的拼接与卷积计算量。
- 替换 PANet 为更简单的特征融合方式:用直接通道拼接 + 1×1 卷积压缩替代复杂的上采样 - 下采样流程,快速融合深浅层特征。
四、检测头:适配类别与任务
鸡蛋检测属于 “多类别分类 + 定位” 任务,检测头可做如下优化:
- 减少锚框数量:鸡蛋形状相对规则,可将每个特征点的锚框数从 3 个减少为 2 个(适配鸡蛋的椭圆形态),降低预测分支的计算量。
- 定制类别输出:针对 “软壳蛋、污损蛋、破损蛋、正常蛋、褐壳蛋”5 类,将检测头的类别输出维度改为 5,避免冗余计算。
通过以上修改,网络的参数量和计算量可降低 50% 以上,推理速度提升 30%-40%,同时保留对鸡蛋灰度特征的检测能力。训练时,可结合知识蒸馏(用大模型的知识指导轻量化模型训练)进一步提升精度,最终实现 “更快、更准” 的鸡蛋检测。
最后,再回到文章的开头,你应该能看懂YOLO11的网络结构了。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









